| 1 |
%$Header: /home/dashley/cvsrep/e3ft_gpl01/e3ft_gpl01/dtaipubs/esrgubka/c_cil0/c_cil0.tex,v 1.24 2003/11/03 02:14:24 dtashley Exp $
|
| 2 |
|
| 3 |
\chapter[\ccilzeroshorttitle{}]{\ccilzerolongtitle{}}
|
| 4 |
|
| 5 |
\label{ccil0}
|
| 6 |
|
| 7 |
\beginchapterquote{``If our ancestors had invented arithmetic by counting with
|
| 8 |
their two fists or their eight fingers, instead of their
|
| 9 |
ten `digits', we would never have to worry about
|
| 10 |
writing binary-decimal conversion routines.
|
| 11 |
(And we would perhaps never have learned as much about
|
| 12 |
number systems.)''}
|
| 13 |
{Donald E. Knuth, \cite[p. 319]{bibref:b:knuthclassic2ndedvol2}}
|
| 14 |
|
| 15 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 16 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 17 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 18 |
\section{Introduction}
|
| 19 |
%Section tag: INT0
|
| 20 |
\label{ccil0:sint0}
|
| 21 |
|
| 22 |
Low-cost microcontrollers have no support for floating-point arithmetic,
|
| 23 |
and so integer arithmetic and fixed-point arithmetic are used nearly exclusively
|
| 24 |
in embedded systems. The ability to implement integer arithmetic
|
| 25 |
economically is a critical skill in the development of embedded
|
| 26 |
systems.
|
| 27 |
|
| 28 |
Integer arithmetic algorithms are critically important in embedded
|
| 29 |
systems for the following reasons:
|
| 30 |
|
| 31 |
\begin{itemize}
|
| 32 |
\item Mistakes in the implementation of arithmetic are frequently
|
| 33 |
responsible for product problems. (Mistakes are not confined
|
| 34 |
to obvious errors---errors such as filters which do not converge
|
| 35 |
on their input are also responsible for product problems.)
|
| 36 |
\item Floating-point arithmetic is not available or ill-advised
|
| 37 |
for nearly all small embedded systems for the following reasons:
|
| 38 |
\begin{itemize}
|
| 39 |
\item Low-cost microcontrollers do not possess hardware support for
|
| 40 |
floating-point arithmetic.
|
| 41 |
\item Implementation of floating-point arithmetic in software is
|
| 42 |
computationally expensive.
|
| 43 |
\item Implementation of floating-point arithmetic in software may
|
| 44 |
require large floating-point libraries, typically consuming
|
| 45 |
1K-4K of ROM.
|
| 46 |
\item Safety-critical software standards typically prohibit the
|
| 47 |
use of floating-point arithmetic.
|
| 48 |
\end{itemize}
|
| 49 |
\item Integer arithmetic algorithms (other than addition and subtraction)
|
| 50 |
are quite tedious and error-prone for a software developer to design, implement, and
|
| 51 |
unit test. The implementation of such algorithms represents
|
| 52 |
cost and risk. Cost and risk benefits are achieved if the algorithms in detail are
|
| 53 |
available in advance (thus precluding design activities), or
|
| 54 |
better yet if ready-to-use integer algorithm libraries are available.
|
| 55 |
\end{itemize}
|
| 56 |
|
| 57 |
This chapter describes the more fundamental principles and algorithms
|
| 58 |
(representation, fixed-point arithmetic, treatment of overflow, comparison,
|
| 59 |
addition, subtraction, multiplication, and division). A section
|
| 60 |
(Section \ref{ccil0:smim0}) is also included
|
| 61 |
on miscellaneous mappings involving integers which
|
| 62 |
are not numerical in intent.
|
| 63 |
Chapter %\cdtazeroxrefhyphen\cdtazerovolarabic{}
|
| 64 |
TBD
|
| 65 |
describes more complicated
|
| 66 |
integer algorithms and techniques (discrete-time operations
|
| 67 |
such as filtering, integration, and differentiation as well as more
|
| 68 |
complex functions such as square root). The split between these two chapters
|
| 69 |
is arbitrary; and in fact the material could have been divided differently
|
| 70 |
or combined.
|
| 71 |
|
| 72 |
Treatment of the topics in this chapter is largely in accordance with
|
| 73 |
Knuth \cite{bibref:b:knuthclassic2ndedvol2}. The principal issues in
|
| 74 |
the implementation of integer algorithms are:
|
| 75 |
|
| 76 |
\begin{itemize}
|
| 77 |
\item \textbf{How to use the arithmetic [or other] instructions provided by the machine to
|
| 78 |
operate on larger operands.} Microcontrollers typically provide arithmetic
|
| 79 |
instructions (comparison, shifting, addition, subtraction, and often but not
|
| 80 |
always multiplication and/or division) that operate on 8-bit or 16-bit integers.
|
| 81 |
A key question
|
| 82 |
is how small-operand instructions ``scale up''---that is, if and how they can
|
| 83 |
be used to assist in the implementation of integer arithmetic for much larger
|
| 84 |
operands.
|
| 85 |
\item \textbf{The order of the algorithm involved.} The order of algorithms
|
| 86 |
is a complicated issue when applied to microcontroller work. Many sophisticated
|
| 87 |
algorithms have a breakpoint below which they are less economical than
|
| 88 |
an inferior algorithm. Some applications (such as generating cryptographic keys
|
| 89 |
when integers thousands of bits long must be tested for primality) will
|
| 90 |
benefit from sophisticated algorithms becuase the operand sizes are large enough
|
| 91 |
to pass any such breakpoints. However, in microcontroller work, the need to manipulate
|
| 92 |
integers longer than 64 bits is very rare; thus, the breakpoints that indicate the
|
| 93 |
use of more sophisticated algorithms may not be reached. In microcontroller work,
|
| 94 |
depending on the operand sizes, there are circumstances in which an
|
| 95 |
$O(n^2)$ algorithm may be preferable to an $O(\log n)$ algorithm. Generally,
|
| 96 |
the order of algorithms must be balanced against operand sizes.
|
| 97 |
\end{itemize}
|
| 98 |
|
| 99 |
We do diverge from Knuth in some areas. The most prominent divergence is
|
| 100 |
in the proofs offered for some important theorems and lemmas. Knuth
|
| 101 |
employs contrapositive proof formats in many circumstances, whereas we prefer
|
| 102 |
to use linear proofs that are more understandable to engineers and microcontroller
|
| 103 |
software developers.
|
| 104 |
|
| 105 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 106 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 107 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 108 |
\section[Paradigms And Principles]
|
| 109 |
{Paradigms And Principles Of Microcontroller Arithmetic}
|
| 110 |
%Section tag: PPM0
|
| 111 |
\label{ccil0:sppm0}
|
| 112 |
|
| 113 |
How should one think about microcontroller arithmetic? What principles
|
| 114 |
guide us in its design and implementation? In this section,
|
| 115 |
we provide some general principles and paradigms of thought.
|
| 116 |
|
| 117 |
|
| 118 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 119 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 120 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 121 |
\subsection{Microcontroller Arithmetic As An Accident Of Silicon Design}
|
| 122 |
%Subsection tag: MAS0
|
| 123 |
\label{ccil0:sppm0:smas0}
|
| 124 |
|
| 125 |
In chapters
|
| 126 |
\cfryzeroxrefhyphen{}\ref{cfry0},
|
| 127 |
\ccfrzeroxrefhyphen{}\ref{ccfr0},
|
| 128 |
and
|
| 129 |
\cratzeroxrefhyphen{}\ref{crat0}
|
| 130 |
we consider rational approximation,
|
| 131 |
both in the form $h/k$ and $h/2^q$. Both forms of rational approximation
|
| 132 |
tend to be effective because we know that all modern processors possess
|
| 133 |
shift instructions, most possess integer multiply instructions, and many
|
| 134 |
possess integer divide instructions. In other words, the design
|
| 135 |
of the machine instruction set drives the strategies for implementation
|
| 136 |
of arithmetic, and makes some strategies attractive.
|
| 137 |
|
| 138 |
Similarly, the observation that all microcontrollers provide instructions
|
| 139 |
for integer arithmetic creates the attractiveness of fixed-point arithmetic.
|
| 140 |
|
| 141 |
Thus, we might view our approaches to microcontroller arithmetic as
|
| 142 |
an ``accident'' of silicon design, or as being driven by silicon
|
| 143 |
design.
|
| 144 |
|
| 145 |
Generally, we seek to determine the best way to use the primitive
|
| 146 |
operations provided by the machine (the instruction set) to
|
| 147 |
accomplish the mappings of interest.
|
| 148 |
|
| 149 |
The ``classic'' algorithms
|
| 150 |
presented by Knuth
|
| 151 |
Knuth (\cite[pp. 265-284]{bibref:b:knuthclassic2ndedvol2}) are especially
|
| 152 |
designed to use the ``small'' addition, subtraction, multiplication, and
|
| 153 |
division provided by the machine to add, subtract, multiply, and divide arbitrarily
|
| 154 |
large integers. In
|
| 155 |
\cite[pp. 265-266]{bibref:b:knuthclassic2ndedvol2}) Knuth writes:
|
| 156 |
|
| 157 |
\begin{quote}
|
| 158 |
\emph{The most important fact to understand about extended-precision numbers
|
| 159 |
is that they may be regarded as numbers written in radix-$w$ notation,
|
| 160 |
where $w$ is the computer's word size. For example, an integer that
|
| 161 |
fills 10 words on a computer whose word size is $w=10^{10}$ has 100
|
| 162 |
decimal digits; but we will consider it to be a 10-place number to
|
| 163 |
the base $10^{10}$. This viewpoint is justified for the same reason
|
| 164 |
that we may convert, say, from binary to hexadecimal notation,
|
| 165 |
simply by grouping the bits together.}
|
| 166 |
|
| 167 |
\emph{In these terms, we are given the following primitive operations to work with:}
|
| 168 |
|
| 169 |
\begin{itemize}
|
| 170 |
\item \emph{a$_0$) addition or subtraction of one-place integers, giving a one-place
|
| 171 |
answer and a carry;}
|
| 172 |
\item \emph{b$_0$) multiplication of a one-place integer by another one-place integer,
|
| 173 |
giving a two place answer;}
|
| 174 |
\item \emph{c$_0$) division of a two-place integer by a one-place integer,
|
| 175 |
provided that the quotient is a one-place integer, and yielding
|
| 176 |
also a one-place remainder.}
|
| 177 |
\end{itemize}
|
| 178 |
|
| 179 |
\noindent{}\emph{By adjusting the word size, if necessary, nearly all computers
|
| 180 |
will have these three operations available; so we will construct algorithms
|
| 181 |
(a), (b), and (c) mentioned above in terms of the primitive operations
|
| 182 |
(a$_0$), (b$_0$), and (c$_0$).}
|
| 183 |
|
| 184 |
\emph{Since we are visualizing extended-precision integers as base $b$ numbers, it is
|
| 185 |
sometimes helpful to think of the situation when $b = 10$, and to imagine
|
| 186 |
that we are doing the arithmetic by hand. Then operation (a$_0$) is analogous
|
| 187 |
to memorizing the addition table; (b$_0$) is analogous to memorizing the
|
| 188 |
multiplication table, and (c$_0$) is essentially memorizing the multiplication
|
| 189 |
table in reverse. The more complicated operations (a), (b), (c) on
|
| 190 |
high-precision numbers can now be done using simple addition, subraction,
|
| 191 |
multiplication, and long-division procedures that children are taught
|
| 192 |
in elementary school.}
|
| 193 |
\end{quote}
|
| 194 |
|
| 195 |
The critical issue for implementation of integer arithmetic with large operands
|
| 196 |
is how to use small-operand instructions to operate on larger operands---in other words,
|
| 197 |
how to ``scale up'' the capability provided by the instruction set.
|
| 198 |
|
| 199 |
|
| 200 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 201 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 202 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 203 |
\subsection{Microcontroller Arithmetic As A Mapping From Quantized Domain To
|
| 204 |
Quantized Range}
|
| 205 |
%Subsection tag: MAM0
|
| 206 |
\label{ccil0:sppm0:smam0}
|
| 207 |
|
| 208 |
Microcontroller software accepts inputs which are quantized. In nearly all cases,
|
| 209 |
this involves a mapping from $\vworkrealset$ to $\vworkintset$. Often, because
|
| 210 |
microcontroller products are optimized for cost, the quantization hardware
|
| 211 |
delivers quite poor precision, frequently less than 8 bits.
|
| 212 |
|
| 213 |
When a quantized input is accepted, it defines an inquality. Knowledge of
|
| 214 |
the quantized input (an integer) confines the actual input (a real
|
| 215 |
number, before
|
| 216 |
quantization) to an interval. With a low-cost hardware design, the
|
| 217 |
interval can be fairly large. Usually, by adding cost, the
|
| 218 |
interval can be made smaller.
|
| 219 |
|
| 220 |
Microcontroller outputs tend to be quantized as well, so it is
|
| 221 |
accurate to also characterize outputs as integers. For example, a PWM signal
|
| 222 |
generated by a microcontroller or the output of a D/A converter is
|
| 223 |
controlled by data that is an integer. Like inputs, often the ``granularity''
|
| 224 |
with which outputs can be controlled is quite coarse---again, 8 bits or
|
| 225 |
less is not uncommon.
|
| 226 |
|
| 227 |
Thus, we may view microcontroller software as a mapping from poor-quality
|
| 228 |
inputs to poor-quality outputs.
|
| 229 |
|
| 230 |
In such a framework, where the nature of inputs and outputs introduces
|
| 231 |
substantial error, it is imperative not to introduce additional error
|
| 232 |
in computer arithmetic. In other words, given inputs which are
|
| 233 |
integers, the responsibility of the software is to choose the best
|
| 234 |
integers as outputs. Usually this means that calculations should be
|
| 235 |
devised so as not to lose any information (i.e.
|
| 236 |
not to lose remainders, for example). Losing information is usually
|
| 237 |
equivalent to not being able to make the most correct mapping from input
|
| 238 |
to output. ``Lossy'' arithmetic can degrade the performance of a system,
|
| 239 |
since poor arithmetic may compound an inexpensive hardware design.
|
| 240 |
|
| 241 |
|
| 242 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 243 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 244 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 245 |
\subsection{Microcontroller Arithmetic As A Simulation Of Continuous Controllers}
|
| 246 |
%Subsection tag: MAE0
|
| 247 |
\label{ccil0:sppm0:smae0}
|
| 248 |
|
| 249 |
Control systems have not always employed digital controllers.
|
| 250 |
Many books and web sites (see \cite{bibref:w:historycontrol01}, for example)
|
| 251 |
discuss the historical development of feedback control. Controllers
|
| 252 |
have not historically been digital, or even electronic.
|
| 253 |
Early controllers for governing steam devices or windmills were
|
| 254 |
ultimately mechanical, and relied upon inertia or other physical
|
| 255 |
properties. It is possible to realize abstract notions
|
| 256 |
(integrators, differentiators, gains) using hydraulic systems or other mechanical systems;
|
| 257 |
and in fact hydraulic feedback controllers were used in early rockets
|
| 258 |
and aircraft. Very naturally, abstract notions (integrators,
|
| 259 |
differentiators, gains) can be implemented using analog
|
| 260 |
electronic components. The most common implementations involve
|
| 261 |
operational amplifiers, and the behavior of such implementations comes
|
| 262 |
very close to the ideal mathematical models.
|
| 263 |
|
| 264 |
Mechanical, hydraulic, and non-digital electronic controllers have
|
| 265 |
one very desirable characteristic---\emph{clipping}. If, for example,
|
| 266 |
one provides an analog differentiator with a $dV/dt$ which
|
| 267 |
is too large, the output that the differentiator can
|
| 268 |
provide is limited, usually by the supply voltage available to an operational
|
| 269 |
amplifier.
|
| 270 |
The differentiator \emph{must} clip.
|
| 271 |
|
| 272 |
Clipping often leads to behavior which is close to what
|
| 273 |
intuition would expect (i.e. we would present
|
| 274 |
clipping as an occasional advantage). For example, if an input to
|
| 275 |
an analog control system suffers a failure, the behavior
|
| 276 |
the of the controller is limited, as is its internal
|
| 277 |
state. Similarly, when the
|
| 278 |
input is restored, the controller will usually recover
|
| 279 |
in a reasonable time because the
|
| 280 |
state of the controller (typically maintained in capacitors) is limited
|
| 281 |
in the magnitude it can attain.
|
| 282 |
|
| 283 |
We might view a digital controller as an emulation of
|
| 284 |
an analog controller. We may want to cause the
|
| 285 |
controller to have limits (i.e. rails) internally, for
|
| 286 |
example to prevent excessive integrator ``windup''. We discuss
|
| 287 |
this further in Section \ref{ccil0:sode0}.
|
| 288 |
|
| 289 |
|
| 290 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 291 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 292 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 293 |
\section{Practical Design Issues}
|
| 294 |
%Section tag: PDI0
|
| 295 |
\label{ccil0:spdi0}
|
| 296 |
|
| 297 |
In this section, we consider practical issues surrounding the design
|
| 298 |
and construction of a set of integer arithmetic subroutines.
|
| 299 |
In practice, such a collection of subroutines is likely to be
|
| 300 |
arranged into a library. The purpose of the library would be to
|
| 301 |
free the clients (or callers) of the library from the complexity of
|
| 302 |
large integer calculations.
|
| 303 |
|
| 304 |
The design decisions surrounding the construction of a library vary in
|
| 305 |
the objectivity with which they can be approached. Some design decisions
|
| 306 |
(such as the best mechanism for passing parameters) can be approached
|
| 307 |
rigorously because the measures of goodness are unequivocal (minimal ROM consumption
|
| 308 |
or execution time, for example). However, other design decisions, particulary the
|
| 309 |
decision of the exact nature of the interface between an arithmetic library and
|
| 310 |
its clients, are more subjective. One size does \emph{not} fit all.
|
| 311 |
|
| 312 |
|
| 313 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 314 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 315 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 316 |
\subsection{Parameter Passing And Temporary Storage Mechanisms}
|
| 317 |
%Subsection tag: PPM0
|
| 318 |
\label{ccil0:spdi0:sppm0}
|
| 319 |
|
| 320 |
In small microcontroller work, the desire to save ROM and execution time
|
| 321 |
may lead to inelegant software construction. Because an arithmetic library
|
| 322 |
used in microcontroller work may be called from many different places
|
| 323 |
throughout ROM, serious thought should be given to optimizing the
|
| 324 |
parameter passing mechanisms, even perhaps at the expense of elegance.
|
| 325 |
The way in which the arithmetic library allocates temporary storage is
|
| 326 |
also a point of concern, because the most elegant way of allocating temporary
|
| 327 |
storage (on the stack) may either not be feasible (because of the possibility
|
| 328 |
of stack overflow) or may not be efficient (because the addressing modes of
|
| 329 |
the machine make data on the stack inefficient to address). In this section
|
| 330 |
we discuss both parameter passing and temporary storage mechanisms.
|
| 331 |
|
| 332 |
In the remainder of the discussion, we make the following assumptions
|
| 333 |
about software architecture.
|
| 334 |
|
| 335 |
\begin{enumerate}
|
| 336 |
\item \textbf{The arithmetic library need not be re-entrant.}
|
| 337 |
Most ``small'' microcontroller software loads use a non-preemptive
|
| 338 |
scheduling paradigm, so this is a reasonable assumption. We also
|
| 339 |
make the reasonable assumption that ISR's may not make calls into
|
| 340 |
the arithmetic library.
|
| 341 |
\item \textbf{Dynamic memory allocation, other than on the stack,
|
| 342 |
is not allowed by the software architecture.} This is also
|
| 343 |
a reasonable assumption in ``small'' microcontroller software.
|
| 344 |
\end{enumerate}
|
| 345 |
|
| 346 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 347 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 348 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 349 |
\subsubsection{Parameter Passing Mechanisms}
|
| 350 |
%Subsubsection tag: PPM0
|
| 351 |
\label{ccil0:spdi0:sppm0:sppm0}
|
| 352 |
|
| 353 |
If an arithmetic library exists in a microcontroller software load,
|
| 354 |
it may be called many times throughout ROM. Thus, the parameter
|
| 355 |
passing mechanisms chosen may have a large effect on ROM consumption
|
| 356 |
(due to the setup required for each subroutine call multiplied by
|
| 357 |
many instances throughout ROM) and execution time
|
| 358 |
(because in microcontroller software longer instructions nearly always
|
| 359 |
require more time). Because of the criticality of ROM consumption,
|
| 360 |
parameter passing mechanisms that lack elegance may be attractive.
|
| 361 |
|
| 362 |
In the category of parameter passing, we also include the way in which
|
| 363 |
return value(s) are passed back to the caller.
|
| 364 |
|
| 365 |
The following parameter-passing mechanisms may be employed:
|
| 366 |
|
| 367 |
\begin{enumerate}
|
| 368 |
\item \textbf{Pass by value as storage class \emph{automatic}.}
|
| 369 |
The most common scenario is that the arithmetic
|
| 370 |
library is written in assembly-language to be called from
|
| 371 |
`C', and so the assembly-language subroutines must adhere to the
|
| 372 |
parameter-passing conventions used by the compiler.
|
| 373 |
This usually means that the entire input or output value
|
| 374 |
will be passed in CPU registers or on the stack. Somewhat rarely,
|
| 375 |
a compiler will pass parameters in static locations.\footnote{The
|
| 376 |
usual reason for a `C' compiler to pass parameters in static locations
|
| 377 |
is because the instruction set of the machine was not designed for
|
| 378 |
higher-level languages, and references to [usually \emph{near}] memory
|
| 379 |
are cheaper than stack references. Such compilers also typically
|
| 380 |
analyze the calling tree of the program where possible and use this
|
| 381 |
information to overlay the parameter-passing memory areas of
|
| 382 |
subroutines that cannot be active simultaneously. Without the ability
|
| 383 |
to analyze the calling tree and make overlay decisions based on it,
|
| 384 |
memory would be exhausted, because each subroutine would need to have its
|
| 385 |
own static storage for parameters and local variables.}
|
| 386 |
\item \textbf{Pass by reference.}
|
| 387 |
Typically, it is convenient to pass pointer(s) to area(s) of memory
|
| 388 |
containing input operands, and also a pointer to an area of memory
|
| 389 |
owned by the caller which is written with the result by the arithmetic subroutine.
|
| 390 |
The efficiency of this approach depends on the compiler and the instruction
|
| 391 |
set of the machine. If the instruction set of the machine cannot
|
| 392 |
make effective use of pointers or stack frames, an arithmetic subroutine
|
| 393 |
might be constructed so that it first copies the operands to a static area of memory
|
| 394 |
reserved for the arithmetic library, then performs the necessary arithmetic
|
| 395 |
operations on the operands in the static area,
|
| 396 |
then copies the result(s) back to the area owned by the caller.
|
| 397 |
\item \textbf{Pass by common data block.}
|
| 398 |
In some cases, it may be preferable to reserve a block of memory in which to
|
| 399 |
pass parameters to arithmetic library functions, and from which to retrieve
|
| 400 |
results after an arithmetic library function returns. The allocation of such
|
| 401 |
a static memory block may be done manually\footnote{Note to self: need to
|
| 402 |
include gentleman's agreements on memory usage in my note on software architecture.}
|
| 403 |
or automatically (by development tools which can analyze the function calling tree and
|
| 404 |
manage the overlaying).
|
| 405 |
\end{enumerate}
|
| 406 |
|
| 407 |
|
| 408 |
|
| 409 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 410 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 411 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 412 |
\subsubsection{Temporary Storage Mechanisms}
|
| 413 |
%Subsubsection tag: TSM0
|
| 414 |
\label{ccil0:spdi0:sppm0:stsm0}
|
| 415 |
|
| 416 |
Need to indicate clearly on section on software architectures the
|
| 417 |
primary temporary storage mechanisms:
|
| 418 |
|
| 419 |
\begin{itemize}
|
| 420 |
\item Stack.
|
| 421 |
\item Memory block with overlay functionality.
|
| 422 |
\end{itemize}
|
| 423 |
|
| 424 |
Need to expand software architecture section to cover this, so don't
|
| 425 |
discuss here.
|
| 426 |
|
| 427 |
|
| 428 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 429 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 430 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 431 |
\subsection{Reporting Of Overflow, Underflow, And Domain Errors}
|
| 432 |
%Subsection tag: OUD0
|
| 433 |
\label{ccil0:spdi0:soud0}
|
| 434 |
|
| 435 |
Long integer data types used in microcontroller work are typically
|
| 436 |
of a static size (they cannot grow in size in as operations are
|
| 437 |
performed on them). The reason for the typical static sizes is that
|
| 438 |
dynamic allocation (except for allocation and
|
| 439 |
deallocation on the stack as subroutines
|
| 440 |
are called and return) is rarely used in small microcontroller work.
|
| 441 |
It will come about in the normal usage of an integer arithmetic
|
| 442 |
library that an attempt will be made to operate on integers in
|
| 443 |
a way which generates an overflow, generates an
|
| 444 |
underflow, or
|
| 445 |
represents a domain error (division by zero or
|
| 446 |
square root of a negative integer, for example).
|
| 447 |
An important design decision is how such normal exceptions should be
|
| 448 |
handled.
|
| 449 |
|
| 450 |
Possible design decisions in this area are:
|
| 451 |
|
| 452 |
\begin{enumerate}
|
| 453 |
\item \label{enum:ccil0:spdi0:soud0:01:01}
|
| 454 |
\textbf{To design arithmetic subroutines so that exceptions are not
|
| 455 |
possible.}
|
| 456 |
For example, multiplying an $m$-word integer by an $n$-word integer
|
| 457 |
will always generate an integer that will fit within $m+n$ words.
|
| 458 |
If a multiplication subroutine is designed so that the caller must
|
| 459 |
provide an $m$-word operand and an $n$-word operand and a pointer to
|
| 460 |
an $(m+n)$-word area of memory for the result, an overflow cannot occur.
|
| 461 |
Such a design decision essentially pushes overflow detection back up to
|
| 462 |
the callers of arithmetic subroutines.
|
| 463 |
\item \label{enum:ccil0:spdi0:soud0:01:02}
|
| 464 |
\textbf{To design arithmetic subroutines so that exceptions are possible,
|
| 465 |
but not to detect the exceptions, thus providing an implementation that
|
| 466 |
will produce incorrect results with some operand data values.}
|
| 467 |
For example, if an arithmetic subroutine is designed to add an $m$-word
|
| 468 |
operand to another $m$-word operand to produce an $m$-word result, overflow
|
| 469 |
is possible. A design decision to fail to detect such exceptions pushes
|
| 470 |
the responsibility up to the callers of the arithmetic subroutines.
|
| 471 |
Callers must devise a method for not calling arithmetic subroutines
|
| 472 |
with data values that will cause an exception, or else to detect an exception
|
| 473 |
when it has occurred.
|
| 474 |
\item \label{enum:ccil0:spdi0:soud0:01:03}
|
| 475 |
\textbf{To ``rail'' the result in response to an exception.}
|
| 476 |
It was stated earlier that analog control system functional blocks
|
| 477 |
built with operational
|
| 478 |
amplifiers typically have an output which cannot go beyond the
|
| 479 |
supply rails. One may implement similar behavior in arithmetic subroutines.
|
| 480 |
In an addition subroutine which adds two $m$-word operands to produce an
|
| 481 |
$m$-word result (with each word having $w$ bits), it would be natural to
|
| 482 |
return $2^{mw}-1$ in the event of an overflow in a positive direction and
|
| 483 |
$-2^{mw}$ in the event of an overlfow in a negative direction. Note that
|
| 484 |
the caller will not be able to distinguish a ``rail'' value which represents
|
| 485 |
a valid result from a ``rail'' value substituted to indicate an exception.
|
| 486 |
\item \label{enum:ccil0:spdi0:soud0:01:04}
|
| 487 |
\textbf{To reserve special result data values to indicate exceptions.}
|
| 488 |
Depending on the arithmetic subroutine being implemented, it may be possible
|
| 489 |
to reserve certain result data values to indicate exceptions. This approach
|
| 490 |
is often awkward, as most mathematical subroutines are naturally defined so that
|
| 491 |
all bit patterns in the memory reserved for the result are valid numbers.
|
| 492 |
Additionally, with long result data values, it may not be economical to
|
| 493 |
compare the result against the reserved exception values. Thus, this is seldom
|
| 494 |
an optimal way to deal with exceptions.
|
| 495 |
|
| 496 |
Additionally, if this approach is employed, the semantics of how exception
|
| 497 |
values combine with other exception values and data values must be decided.
|
| 498 |
\item \label{enum:ccil0:spdi0:soud0:01:05}
|
| 499 |
\textbf{To return exception codes to the caller separate from the result data.}
|
| 500 |
In the `C' language, pointers are often used to supply an arithmetic subroutine
|
| 501 |
with the input operands and to provide the arithmetic subroutine with a location
|
| 502 |
(which belongs to the caller) in which to store the result data. Thus, the return
|
| 503 |
value of the arithmetic subroutine (normally assigned through the subroutine name)
|
| 504 |
is often available to return exception codes. For example,
|
| 505 |
a `C' function may be defined as
|
| 506 |
|
| 507 |
\begin{verbatim}
|
| 508 |
unsigned char int128_add(INT128 *result,
|
| 509 |
INT128 *arg1,
|
| 510 |
INT128 *arg2),
|
| 511 |
\end{verbatim}
|
| 512 |
|
| 513 |
leaving the returned \texttt{unsigned char} value available to return
|
| 514 |
exception information. Note that this arrangement has the following advantages:
|
| 515 |
|
| 516 |
\begin{enumerate}
|
| 517 |
\item All bit patterns in the result data memory area area available
|
| 518 |
as data bit patterns.
|
| 519 |
\item The exception data is very economical to test, because it is placed
|
| 520 |
in a machine-native data type.
|
| 521 |
\item The exception data can easily be discarded or by the caller if desired.
|
| 522 |
\item All decisions about how to handle exceptions are left to the caller.
|
| 523 |
\end{enumerate}
|
| 524 |
\item \label{enum:ccil0:spdi0:soud0:01:06}
|
| 525 |
\textbf{To maintain exception data with each result integer.}
|
| 526 |
It is possible to reserve bits for exception information which are part of the
|
| 527 |
long integer data type. This exception state essentially conveys
|
| 528 |
\emph{NaN}\footnote{\emph{N}ot \emph{a} \emph{n}umber.} information---integers with
|
| 529 |
exception information set are not true numbers, but rather they are different from the
|
| 530 |
true result in some way. As with (\ref{enum:ccil0:spdi0:soud0:01:04}), the
|
| 531 |
semantics of how to combine NaN values and NaN values with ordinary non-NaN numbers
|
| 532 |
must be defined.
|
| 533 |
\item \label{enum:ccil0:spdi0:soud0:01:07}
|
| 534 |
\textbf{To maintain a global exception state variable.}
|
| 535 |
A variable or set of variables can be reserved which hold the
|
| 536 |
exception information, if any, from the most recent call to
|
| 537 |
a function in the arithmetic library.
|
| 538 |
|
| 539 |
To save CPU cycles, the arithmetic library can
|
| 540 |
be designed so that it will assign the global exception state variable only if an
|
| 541 |
exception occurs---the caller then has the responsibility of clearing the exception
|
| 542 |
state variable before making any call into the arithmetic library where the
|
| 543 |
exception result is of interest. The interface between the caller and the library
|
| 544 |
can be further optimized if the library only OR's data into the variable containing
|
| 545 |
the exception state. Using this optimization, the caller can clear the exception state
|
| 546 |
variable, make several calls into the arithmetic library, and then retrieve a meaningful
|
| 547 |
exception state variable value summarizing several arithmetic operations.
|
| 548 |
\item \label{enum:ccil0:spdi0:soud0:01:08}
|
| 549 |
\textbf{Hybrid approaches.}
|
| 550 |
The approaches (\ref{enum:ccil0:spdi0:soud0:01:01})
|
| 551 |
through (\ref{enum:ccil0:spdi0:soud0:01:07}) can be combined.
|
| 552 |
For example, approach (\ref{enum:ccil0:spdi0:soud0:01:03})
|
| 553 |
might be combined with approach (\ref{enum:ccil0:spdi0:soud0:01:05})
|
| 554 |
so that exceptions are ``railed'', but the caller may also be made
|
| 555 |
aware that an exception has occured. Many hybrid approaches are possible.
|
| 556 |
\end{enumerate}
|
| 557 |
|
| 558 |
|
| 559 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 560 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 561 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 562 |
\subsection{Semantics Of Combining Overflow, Underflow, And Domain Errors}
|
| 563 |
%Subsection tag: CMB0
|
| 564 |
\label{ccil0:spdi0:scmb0}
|
| 565 |
|
| 566 |
For control system arithmetic, some form of clipping as suggested
|
| 567 |
in Section \ref{ccil0:sppm0:smae0} is probably the
|
| 568 |
best approach. Definitely, an overflow should generate a result
|
| 569 |
which is the largest representable integer, and an
|
| 570 |
underflow should generate a result which is the smallest
|
| 571 |
representable integer.
|
| 572 |
|
| 573 |
In addition to treating an overflow by clipping, it may be
|
| 574 |
advantageous to reserve a flag in the representation of a
|
| 575 |
multiple-precision integer to record that an overflow has occured and been clipped.
|
| 576 |
Some functions which accept the integer as input may be interested
|
| 577 |
in the value of such a flag, where othere---perhaps most---may
|
| 578 |
not.
|
| 579 |
|
| 580 |
The correct course of action in the event of a domain error (such
|
| 581 |
as division by zero) is less clear. It is noteworthy that in a
|
| 582 |
normal control system, domain errors cannot occur (but overflows
|
| 583 |
can).
|
| 584 |
|
| 585 |
The best approach when a domain error is involved probably
|
| 586 |
depends on the basis for the underlying calculation. For
|
| 587 |
example, if integer division is used as part of a
|
| 588 |
strategy for software ratiometric conversion, a value
|
| 589 |
of zero in the denominator probably represents extreme electrical
|
| 590 |
noise, and the most sane approach may be to replace the
|
| 591 |
denominator by one. However, in other contexts it may be appropriate
|
| 592 |
to think in terms of
|
| 593 |
|
| 594 |
\begin{equation}
|
| 595 |
\lim_{k \rightarrow 0^+} \frac{kn}{kd}
|
| 596 |
\end{equation}
|
| 597 |
|
| 598 |
\noindent{}or
|
| 599 |
|
| 600 |
\begin{equation}
|
| 601 |
\lim_{k \rightarrow 0^-} \frac{kn}{kd} .
|
| 602 |
\end{equation}
|
| 603 |
|
| 604 |
Put in other terms, there is not a clear ``one solution
|
| 605 |
meets all needs'' approach to dealing with domain
|
| 606 |
errors.
|
| 607 |
|
| 608 |
As in the case of overflows, it may be advantageous to reserve a bit
|
| 609 |
flag to signal that a domain error has occured and that the result
|
| 610 |
is not valid or not reliable. Note that floating point chips
|
| 611 |
(such as the 80x87) provide similar indications of domain errors.
|
| 612 |
|
| 613 |
It may also be advantageous to adopt conventions for how
|
| 614 |
overflow or domain error flags propagate through binary or
|
| 615 |
unary operators. For example, if two numbers are multiplied, and
|
| 616 |
one of the two has the overflow flag set, it may be wise set the
|
| 617 |
overflow flag in the result. A scheme for how warning
|
| 618 |
flags propagate may be beneficial.
|
| 619 |
|
| 620 |
|
| 621 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 622 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 623 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 624 |
\subsection{Variable Versus Constant Subroutine Execution Time}
|
| 625 |
%Subsection tag: VVC0
|
| 626 |
\label{ccil0:spdi0:svvc0}
|
| 627 |
|
| 628 |
As a design goal of an embedded system, we seek to minimize the
|
| 629 |
timing variability of software components. An arithmetic subroutine
|
| 630 |
that with a high probability takes a short time to execute and with a
|
| 631 |
low probability takes a long time to execute, and where the execution
|
| 632 |
time is data dependent, is a serious risk. An embedded software product
|
| 633 |
may pass all release testing, but then fail in the field because of
|
| 634 |
specific data values used in calculations.
|
| 635 |
|
| 636 |
A very conservative design goal would be to design every arithmetic subroutine
|
| 637 |
to require exactly the same execution time, regardless of data values.
|
| 638 |
This goal is not practical because machine instructions themselves
|
| 639 |
usually have a variable execution time, particularly for multiplication
|
| 640 |
and division instructions. A fallback goal would be to avoid
|
| 641 |
large differences between minimum and maximum execution time, without
|
| 642 |
increasing the maximum execution time. A very practical step to take
|
| 643 |
(using division as an example)
|
| 644 |
is to insert artifical delays into easily detectable exception cases (such as
|
| 645 |
division by zero) so that the exception case takes as long as the
|
| 646 |
minimum time for a division with valid operands.
|
| 647 |
|
| 648 |
|
| 649 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 650 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 651 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 652 |
\section{Fixed-Point Arithmetic}
|
| 653 |
%Section tag: FPA0
|
| 654 |
\label{ccil0:sfpa0}
|
| 655 |
|
| 656 |
\emph{Fixed-point arithmetic}\index{fixed-point arithmetic}
|
| 657 |
is a scheme for the representation
|
| 658 |
of engineering quantities (conceptually real numbers with optional
|
| 659 |
units) by integers so that calculations can be performed
|
| 660 |
on these quantitites using [usually multiple-precision]
|
| 661 |
integer arithmetic.
|
| 662 |
|
| 663 |
In discussing fixed-point arithmetic,
|
| 664 |
we must be careful to distinguish between the
|
| 665 |
\emph{represented value} (the engineering quantity)
|
| 666 |
and the \emph{representation} (the integer which represents
|
| 667 |
the engineering quantity). In most cases, we must also
|
| 668 |
be careful to devise a system to track the units of the
|
| 669 |
represented values, as, especially with control systems,
|
| 670 |
the units of represented values (due to integration and
|
| 671 |
differentiation) can become very complex
|
| 672 |
and mistakes are easy to make.
|
| 673 |
|
| 674 |
Fixed-point arithmetic is the dominant paradigm of construction
|
| 675 |
for calculations in small microcontroller systems. It may not be
|
| 676 |
clear why this should be so or what advantages it offers [over
|
| 677 |
floating-point arithmetic]. The reasons for
|
| 678 |
this predominance are:
|
| 679 |
|
| 680 |
\begin{itemize}
|
| 681 |
\item Fixed-point calculations tend to be very efficient, because
|
| 682 |
they make direct use of the integer arithmetic instructions in the
|
| 683 |
microcontroller's instruction set. On the other hand, floating-point
|
| 684 |
arithmetic operations tend to be much slower.
|
| 685 |
|
| 686 |
\item Floating-point calculations typically require a floating-point
|
| 687 |
library, which may consume at least several hundred bytes
|
| 688 |
of ROM.
|
| 689 |
|
| 690 |
\item Some safety-critical software standards prohibit the use of
|
| 691 |
floating-point arithmetic because it can result in nebulous
|
| 692 |
behavior. Fixed-point arithmetic avoids these concerns.
|
| 693 |
\end{itemize}
|
| 694 |
|
| 695 |
In order to carry out fixed-point arithmetic---that is, in order to
|
| 696 |
operate on engineering quantities as integers---we
|
| 697 |
require that the relationship between the
|
| 698 |
represented value and the representation be of the form
|
| 699 |
|
| 700 |
\begin{equation}
|
| 701 |
\label{eq:ccil0:sfpa0:00}
|
| 702 |
x = r_I u + \Psi,
|
| 703 |
\end{equation}
|
| 704 |
|
| 705 |
\noindent{}where $x \in \vworkrealset$ (possibly with units) is the represented
|
| 706 |
value, $u \in \vworkintset$ is the representation,
|
| 707 |
$r_I \in \vworkrealset$ is the scaling factor (possibly with
|
| 708 |
units), and $\Psi \in \vworkrealset$ (possibly with units) is the offset.
|
| 709 |
Note that the units of $r_I$, $\Psi$, and $x$ must match.
|
| 710 |
|
| 711 |
We further require that $r_I \vworkdivides{} \Psi$\footnote{We \emph{are}
|
| 712 |
aware that this is an abuse of nomenclature, as
|
| 713 |
`$\vworkdivides$' (``divides'') is traditionally only applied to integers.}
|
| 714 |
(i.e. that $\Psi$ be an
|
| 715 |
integral multiple of $r_I$)
|
| 716 |
so that the offset in the represented value corresponds to an integer
|
| 717 |
in the representation. Without this restriction, we could not remove the
|
| 718 |
offset from the representation with integer subtraction only. Note that
|
| 719 |
we do \emph{not} require that $r_I$ or $\Psi$ be rational, although
|
| 720 |
they must both be rational or both be irrational in order to satisfy
|
| 721 |
(\ref{eq:ccil0:sfpa0:00}).
|
| 722 |
|
| 723 |
In (\ref{eq:ccil0:sfpa0:00}), since we've required that $r_I \vworkdivides{} \Psi$,
|
| 724 |
we can replace $\Psi$ by
|
| 725 |
|
| 726 |
\begin{equation}
|
| 727 |
\label{eq:ccil0:sfpa0:00b}
|
| 728 |
\psi = \frac{\Psi}{r_I}
|
| 729 |
\end{equation}
|
| 730 |
|
| 731 |
\noindent{}to obtain
|
| 732 |
|
| 733 |
\begin{equation}
|
| 734 |
\label{eq:ccil0:sfpa0:01}
|
| 735 |
x = r_I (u + \psi),
|
| 736 |
\end{equation}
|
| 737 |
|
| 738 |
\noindent{}where $\psi \in \vworkintset$ is the offset in representational
|
| 739 |
counts.
|
| 740 |
|
| 741 |
Note that we can also easily obtain the following relationships from the
|
| 742 |
defining equations (\ref{eq:ccil0:sfpa0:00}),
|
| 743 |
(\ref{eq:ccil0:sfpa0:00b}), and (\ref{eq:ccil0:sfpa0:01}).
|
| 744 |
|
| 745 |
\begin{equation}
|
| 746 |
\label{eq:ccil0:sfpa0:02}
|
| 747 |
u = \frac{x - \Psi}{r_I} = \frac{x}{r_I} - \psi
|
| 748 |
\end{equation}
|
| 749 |
|
| 750 |
\begin{equation}
|
| 751 |
\label{eq:ccil0:sfpa0:03}
|
| 752 |
\psi = \frac{\Psi}{r_I}
|
| 753 |
\Longleftrightarrow
|
| 754 |
\Psi = r_I \psi
|
| 755 |
\Longleftrightarrow
|
| 756 |
r_I = \frac{\Psi}{\psi}
|
| 757 |
\end{equation}
|
| 758 |
|
| 759 |
|
| 760 |
For example, in a 16-bit signed integer (which inherently may range
|
| 761 |
from -32768 to 32767 inclusive), one might used a fixed-point
|
| 762 |
representation of 100 integer counts per $^\circ$C ($r_I = 0.01 \; ^\circ$C)
|
| 763 |
with an offset of 100$^\circ$C ($\Psi$ = 100$^\circ$C or equivalently
|
| 764 |
$\psi$ = 10000), giving
|
| 765 |
a representational range from -227.68$^\circ$C to 427.67$^\circ$C inclusive.
|
| 766 |
|
| 767 |
If $r_I = 2^N, \; N \in \vworkintset$, then the radix point of the represented
|
| 768 |
value is positioned
|
| 769 |
between two bits of the representation---this arrangement may have computational
|
| 770 |
advantages
|
| 771 |
if the whole and fractional parts of the represented value need to be separated
|
| 772 |
easily in the representation. Note also that if $r_I = 2^{WN}$ where $W$ is the
|
| 773 |
machine integer size of the computer (in bits), then the radix point of the represented value
|
| 774 |
occurs between two addressable machine integers of the representation, which can be convenient.
|
| 775 |
However, we do not require for our definition of a fixed-point representation that
|
| 776 |
$r_I$ be an integral power of two; and in fact we do not even require by our
|
| 777 |
definition that $r_I$ be rational. Note that in general our definition above is the
|
| 778 |
weakest set of conditions so that real-world engineering values can be manipulated
|
| 779 |
using integer operations performed upon the representation.
|
| 780 |
|
| 781 |
|
| 782 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 783 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 784 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 785 |
\section{Representation Of Integers}
|
| 786 |
%Section Tag: ROI0
|
| 787 |
\label{ccil0:sroi0}
|
| 788 |
|
| 789 |
In this section, we discuss common representations of integers, both
|
| 790 |
\emph{machine} integers and \emph{synthetic long} integers.
|
| 791 |
By \emph{representation} we mean the mapping between the abstract
|
| 792 |
mathematical notion of an integer and the way it is stored in the computer
|
| 793 |
(voltage levels and the programming model).
|
| 794 |
Although
|
| 795 |
in Knuth's development of integer arithmetic
|
| 796 |
\cite{bibref:b:knuthclassic2ndedvol2}
|
| 797 |
it is assumed that
|
| 798 |
integers may be represented in any base, we don't require such generality
|
| 799 |
in practice and in this work we confine ourselves for the most
|
| 800 |
part to $b=2^n$, and often to $n = 8i$, $i \in \vworkintsetpos$. The assumption
|
| 801 |
of $b=2^n$ characterizes all modern digital computers, and we feel comfortable
|
| 802 |
making this assumption throughout the work. However, the assumption
|
| 803 |
$n = 8i$, $i \in \vworkintsetpos$ does not hold universally, and so we
|
| 804 |
most often do not make this assumption.
|
| 805 |
|
| 806 |
By \emph{machine} integer, we mean an integer upon which the computer
|
| 807 |
can operate in a single instruction (such as to add, increment,
|
| 808 |
load, store, etc.). For most microcontrollers, machine integers are
|
| 809 |
either 8 or 16 bits in size. The representation of a machine integer
|
| 810 |
is designed and specified by the microcontroller manufacturer. In principle,
|
| 811 |
nothing would prevent a microcontroller manufacturer from devising
|
| 812 |
and implementing a novel way of representing machine integers and supporting
|
| 813 |
this novel representation with an instruction set. However, in
|
| 814 |
practice, all machine integers are either simple unsigned integers or two's
|
| 815 |
complement signed integers. In addition to the efficiency of these
|
| 816 |
representations with respect to the design of digital logic, these representations
|
| 817 |
are so standard and so pervasive that they are universally tacitly assumed.
|
| 818 |
For example, ``\texttt{if (i \& 0x1)}'' is an accepted C-language
|
| 819 |
idiom for ``if $i$ is odd'', and it is expected that such code will
|
| 820 |
work on all platforms.
|
| 821 |
|
| 822 |
By \emph{synthetic long} integer, we mean an integer of
|
| 823 |
arbitrary\footnote{By \emph{arbitrary}, we do not necessarily mean that
|
| 824 |
the integer can grow to be arbitrarily large in magnitude, or that
|
| 825 |
its maximum size is not known at compile time. We mean \emph{arbitrarily}
|
| 826 |
longer than a machine integer. Multiple-precision arithmetic libraries
|
| 827 |
can be divided into two classes---those that fix the size of the integers
|
| 828 |
at compile time, and those that use dynamic allocation and allow integers to
|
| 829 |
grow as needed at run time. The former category
|
| 830 |
is normally used for small microcontroller work, whereas the latter category
|
| 831 |
(such as the GNU MP Library \cite{bibref:s:gnumultipleprecisionarithmeticlibrary})
|
| 832 |
is normally used in scientific and number theoretic calculation and on
|
| 833 |
more powerful platforms than microcontrollers. The representational concepts
|
| 834 |
we present here apply to both categories.}
|
| 835 |
length that is formed by concatenating machine integers. There is some
|
| 836 |
subjectivity in deciding the representation of multiple-precision integers,
|
| 837 |
and we discuss in the subsections
|
| 838 |
\ref{ccil0:sroi0:srou0} and
|
| 839 |
\ref{ccil0:sroi0:sros0} which immediately follow.
|
| 840 |
|
| 841 |
|
| 842 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 843 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 844 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 845 |
\subsection{Representation Of Unsigned Integers}
|
| 846 |
%Subsection Tag: ROU0
|
| 847 |
\label{ccil0:sroi0:srou0}
|
| 848 |
|
| 849 |
Unsigned machine integers are always represented as an ordered
|
| 850 |
array of bits (Figure \ref{fig:ccil0:sroi0:srou0:00}). For an
|
| 851 |
$m$-bit unsigned integer $u$, we denote these bits $u_{[m-1]}$ through
|
| 852 |
$u_{[0]}$, with $u_{[m-1]}$ the most significant bit. The value
|
| 853 |
of $u$ is the sum of the values of each bit multiplied
|
| 854 |
by the power of 2 it represents:
|
| 855 |
|
| 856 |
\begin{figure}
|
| 857 |
\centering
|
| 858 |
\includegraphics[width=4.6in]{c_cil0/uintrep1.eps}
|
| 859 |
\caption{Representation Of Unsigned Machine Integers}
|
| 860 |
\label{fig:ccil0:sroi0:srou0:00}
|
| 861 |
\end{figure}
|
| 862 |
|
| 863 |
\begin{equation}
|
| 864 |
\label{eq:ccil0:sroi0:srou0:00}
|
| 865 |
u = \sum_{i=0}^{m-1} u_{[i]} 2^i .
|
| 866 |
\end{equation}
|
| 867 |
|
| 868 |
In general, an $m$-bit unsigned integer can assume the values of
|
| 869 |
0 through $2^m - 1$, so that
|
| 870 |
|
| 871 |
\begin{equation}
|
| 872 |
\label{eq:ccil0:sroi0:srou0:01}
|
| 873 |
u \in \{0, \ldots{} , 2^m - 1 \} .
|
| 874 |
\end{equation}
|
| 875 |
|
| 876 |
Unsigned synthetic long integers are always represented as an array
|
| 877 |
of unsigned machine integers.
|
| 878 |
Consistent with the GMP \cite{bibref:s:gnumultipleprecisionarithmeticlibrary},
|
| 879 |
we call each element of the array a \emph{limb} and we call the size of
|
| 880 |
each limb the \emph{limbsize}. This usage is very close to what Knuth
|
| 881 |
calls the \emph{word}size $w$ in the excerpt presented in
|
| 882 |
Section \ref{ccil0:sppm0:smas0}.
|
| 883 |
|
| 884 |
Microcontroller processors are more likely than more powerful processors to have
|
| 885 |
a non-orthogonal instruction set, and so the limbsize may not be consistent between
|
| 886 |
operations in an arithmetic library.
|
| 887 |
With some processors, the appropriate limbsize may vary depending on the operation being
|
| 888 |
performed.
|
| 889 |
For example, a microcontroller processor may be able to add two 16-bit integers to
|
| 890 |
obtain a 16-bit result plus a carry, but only be able to multiply two 8-bit integers to
|
| 891 |
obtain a 16-bit result (thus, the appropriate limbsize for addition may be
|
| 892 |
16 bits while the appropriate limbsize for multiplication may be 8 bits).
|
| 893 |
In such cases, it is usually most efficient to add using 16-bit limbs but
|
| 894 |
multiply using 8-bit limbs. Adding using 8-bit limbs on a machine which will
|
| 895 |
support 16-bit additions is not normally a good design decision---even if the
|
| 896 |
machine supports an 8-bit addition instruction which is faster than the 16-bit addition
|
| 897 |
instruction, $m/2$ 16-bit additions will nearly always be faster than
|
| 898 |
$m$ 8-bit additions. Using different limbsizes within the same arithmetic library
|
| 899 |
may require some consideration of alignment and
|
| 900 |
endian issues, but these are implementation details
|
| 901 |
which are easily solved.
|
| 902 |
|
| 903 |
We view a synthetic long unsigned integer as an array of limbs (machine integers)
|
| 904 |
of some size, and we agree that we will not address the array in any other way than
|
| 905 |
by loading and storing limbs of this size.\footnote{Well \ldots{} not quite.
|
| 906 |
In software for large computers (personal computers and workstations) with an
|
| 907 |
orthogonal instruction set, we may be able to adhere to this rule. However,
|
| 908 |
with microcontrollers, arithmetic libraries which are optimized
|
| 909 |
may break this rule.} In particular, because
|
| 910 |
computers may be ``big-endian'' or ``little-endian'', loading and storing
|
| 911 |
smaller units than limbs may lead in
|
| 912 |
a worst case to software defects or in a best case to non-portable code.
|
| 913 |
|
| 914 |
Assume that $w$ is the number of bits in a limb.
|
| 915 |
Notationally, we denote an unsigned
|
| 916 |
synthetic long integer as an array of $m$ limbs
|
| 917 |
$u_{m-1}$ through $u_0$, each containing $w$ bits,
|
| 918 |
with $u_0$ the least significant machine integer.
|
| 919 |
We may also define $b=2^w$ (consistent with Knuth's
|
| 920 |
notation).
|
| 921 |
The value of
|
| 922 |
such a synthetic long machine integer is
|
| 923 |
|
| 924 |
\begin{equation}
|
| 925 |
\label{eq:ccil0:sroi0:srou0:02}
|
| 926 |
u = \sum_{i=0}^{m-1} u_{i} 2^{wi}
|
| 927 |
=
|
| 928 |
\sum_{i=0}^{m-1} u_{i} b^i.
|
| 929 |
\end{equation}
|
| 930 |
|
| 931 |
As an alternative, we may write the value as the sum of the bit-values,
|
| 932 |
|
| 933 |
\begin{equation}
|
| 934 |
\label{eq:ccil0:sroi0:srou0:03}
|
| 935 |
u = \sum_{i=0}^{wm-1} u_{[i]} 2^{i} .
|
| 936 |
\end{equation}
|
| 937 |
|
| 938 |
Naturally, the range of such a synthetic long integer is
|
| 939 |
|
| 940 |
\begin{equation}
|
| 941 |
\label{eq:ccil0:sroi0:srou0:04}
|
| 942 |
u \in \{0, \ldots{} , 2^{wm} - 1 \} .
|
| 943 |
\end{equation}
|
| 944 |
|
| 945 |
In storing an unsigned synthetic long machine integer, the most natural way
|
| 946 |
to order the array of limbs depends on whether dynamic memory allocation is
|
| 947 |
used by the arithmetic library. In microcontroller work, where arithmetic
|
| 948 |
library subroutines typically operate on fixed-size operands and produce
|
| 949 |
fixed-size results, storing
|
| 950 |
limbs most significant limb first (i.e. in `C', so that element \texttt{[0]}
|
| 951 |
of the array of limbs contains the most significant limb) may be natural
|
| 952 |
and convenient. However, this ordering would lead to computational waste in a library such
|
| 953 |
as the GMP \cite{bibref:s:gnumultipleprecisionarithmeticlibrary} where integers
|
| 954 |
may grow arbitrarily large and the library may need to reallocate long synthetic
|
| 955 |
integers to contain more limbs, as each reallocation would need to be followed
|
| 956 |
by a memory copy to align the integer's existing limbs to the end of the array.
|
| 957 |
For libraries such as the GMP, it is more practical to store limbs
|
| 958 |
least-significant limb first, as it eliminates the need to copy memory
|
| 959 |
when reallocations are done.
|
| 960 |
|
| 961 |
|
| 962 |
|
| 963 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 964 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 965 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 966 |
\subsection{Representation Of Signed Integers}
|
| 967 |
%Subsection Tag: ROS0
|
| 968 |
\label{ccil0:sroi0:sros0}
|
| 969 |
|
| 970 |
Signed machine integers are always represented in two's complement form on modern
|
| 971 |
processors. This representation is universal because of the digital logic
|
| 972 |
conveniences---the same addition and subtraction mappings which are correct
|
| 973 |
for unsigned machine integers are also correct for signed machine integers,
|
| 974 |
although the criteria for overflow and comparison are
|
| 975 |
different.
|
| 976 |
|
| 977 |
Most readers are familiar with two's complement representation, so we will not
|
| 978 |
belabor it. However, we will present essential properties.
|
| 979 |
When two's complement representation is used in an $m$-bit machine integer $u$:
|
| 980 |
|
| 981 |
\begin{enumerate}
|
| 982 |
\item All bit patterns with $u_{[m-1]} = 0$ represent non-negative integers, and
|
| 983 |
represent the same integer as if the representation were unsigned.
|
| 984 |
\item All bit patterns with $u_{[m-1]} = 1$ represent negative numbers; specifically
|
| 985 |
$u_{[m-2:0]} - 2^{m-1}$; i.e.
|
| 986 |
|
| 987 |
\begin{equation}
|
| 988 |
\label{eq:ccil0:sroi0:sros0:00}
|
| 989 |
u = - u_{[m-1]} 2^{m-1} + \sum_{i=0}^{m-2} u_{[i]} 2^i .
|
| 990 |
\end{equation}
|
| 991 |
|
| 992 |
\item $u \in \{-2^{m-1}, \ldots{}, 2^{m-1}-1 \}$.
|
| 993 |
\item All bit patterns represent a unique integer.
|
| 994 |
\item For any integer except $-2^{m-1}$,
|
| 995 |
negation can be performed by forming the one's complement (complementing
|
| 996 |
every bit), then adding one. To see why this is true algebraically, note that
|
| 997 |
|
| 998 |
\end{enumerate}
|
| 999 |
|
| 1000 |
|
| 1001 |
However, let us observe that the value of an
|
| 1002 |
$m$-bit two's complement
|
| 1003 |
machine integer is
|
| 1004 |
|
| 1005 |
|
| 1006 |
In general, an $m$-bit signed machine integer can assume the values of
|
| 1007 |
$-2^{m-1}$ through $2^{m-1} - 1$, so that
|
| 1008 |
|
| 1009 |
\begin{equation}
|
| 1010 |
\label{eq:ccil0:sroi0:sros0:01}
|
| 1011 |
u \in \{-2^{m-1}, \ldots{} , 2^{m-1} - 1 \} .
|
| 1012 |
\end{equation}
|
| 1013 |
|
| 1014 |
There are [at least] two different representations of signed
|
| 1015 |
multiple-precision integers:
|
| 1016 |
|
| 1017 |
\begin{itemize}
|
| 1018 |
\item Two's complement representation.
|
| 1019 |
\item Sign-magnitude representation.
|
| 1020 |
\end{itemize}
|
| 1021 |
|
| 1022 |
There are two different representations commonly used
|
| 1023 |
for signed multiple-precision integers because two's complement
|
| 1024 |
representation is not ideal for multiplication and division, although
|
| 1025 |
it is ideal for addition and subtraction. For multiple-precision
|
| 1026 |
integer arithmetic, sign-magnitude representation is more common.
|
| 1027 |
|
| 1028 |
In two's complement representation of multiple-precision integers,
|
| 1029 |
the representation is the same as suggested by
|
| 1030 |
(\ref{eq:ccil0:sroi0:sros0:00}), except
|
| 1031 |
more bits are involved. For a two's complement representation
|
| 1032 |
of a number consisting of $n$ machine integers with $W$ bits per
|
| 1033 |
machine integer,
|
| 1034 |
|
| 1035 |
\begin{equation}
|
| 1036 |
\label{eq:ccil0:sroi0:sros0:02}
|
| 1037 |
u = - u_{B(Wn-1)} 2^{Wn-1} + \sum_{i=0}^{Wn-2} u_{B(i)} 2^i .
|
| 1038 |
\end{equation}
|
| 1039 |
|
| 1040 |
Because we would like to know how to compare signed multiple-precision
|
| 1041 |
integers in two's complement representation, we can gain some
|
| 1042 |
insight into the representation by rewriting
|
| 1043 |
(\ref{eq:ccil0:sroi0:sros0:02}) in terms of machine integers:
|
| 1044 |
|
| 1045 |
\begin{equation}
|
| 1046 |
\label{eq:ccil0:sroi0:sros0:03}
|
| 1047 |
u = - u_{B(Wn-1)} 2^{Wn-1}
|
| 1048 |
+
|
| 1049 |
\sum_{i=W(m-1)}^{Wn-2} u_{B(i)} 2^i
|
| 1050 |
+
|
| 1051 |
\sum_{i=0}^{m-2} u_{i} 2^{Wi} .
|
| 1052 |
\end{equation}
|
| 1053 |
|
| 1054 |
(\ref{eq:ccil0:sroi0:sros0:03}) gives some insight into the
|
| 1055 |
relative values of multiple-precision signed two's complement
|
| 1056 |
integers with respect to the values of the machine integers
|
| 1057 |
that comprise them. We discuss this further in
|
| 1058 |
Section \ref{ccil0:scsi0}.
|
| 1059 |
|
| 1060 |
In sign-magnitude representation of multiple-precision signed two's
|
| 1061 |
complement integers, an integer $u$ is represented as a sign
|
| 1062 |
bit (usually a value of one indicates negativity), and a magnitude,
|
| 1063 |
which is $|u|$. Unlike two's complement representation,
|
| 1064 |
sign-magnitude representation, has two representations of zero---a positive
|
| 1065 |
one and a negative one. Either a canonical form for zero should be
|
| 1066 |
adopted, or both values should be treated identically.
|
| 1067 |
|
| 1068 |
Assuming that the sign bit is stored in the most significant bit position,
|
| 1069 |
it is easy to deduce that the value of a multiple-precision
|
| 1070 |
signed two's complement integer in sign-magnitude representation is
|
| 1071 |
|
| 1072 |
\begin{equation}
|
| 1073 |
\label{eq:ccil0:sros0:srou0:04}
|
| 1074 |
u = (-1)^{u_{B(m-1)}} \sum_{i=0}^{m-2} u_{B(i)} 2^i .
|
| 1075 |
\end{equation}
|
| 1076 |
|
| 1077 |
Sign-magnitude representation is especially convenient because
|
| 1078 |
it allows machine instructions which accept unsigned operands to be used
|
| 1079 |
to make calculations involving signed integers.
|
| 1080 |
|
| 1081 |
|
| 1082 |
|
| 1083 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1084 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1085 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1086 |
\section{Characteristics Of Practical Processors}
|
| 1087 |
%Section tag: CPP
|
| 1088 |
\label{ccil0:scpp0}
|
| 1089 |
|
| 1090 |
Before discussing specific algorithms, it is necessary to
|
| 1091 |
discuss the construction of practical processors---how such a processor
|
| 1092 |
manipulates machine integers. We accept as a typical processor the
|
| 1093 |
TMS-370C8, an 8-bit microcontroller manufactured by
|
| 1094 |
Texas Instruments.
|
| 1095 |
|
| 1096 |
\begin{figure}
|
| 1097 |
\centering
|
| 1098 |
\includegraphics[width=4.6in]{c_cil0/t370flag.eps}
|
| 1099 |
\caption{Texas Instruments TMS-370C8 Flags}
|
| 1100 |
\label{fig:ccil0:scpp0:00}
|
| 1101 |
\end{figure}
|
| 1102 |
|
| 1103 |
\begin{figure}
|
| 1104 |
\centering
|
| 1105 |
\includegraphics[width=4.6in]{c_cil0/t370cjmp.eps}
|
| 1106 |
\caption{Texas Instruments TMS-370C8 Conditional Jump Instructions}
|
| 1107 |
\label{fig:ccil0:scpp0:01}
|
| 1108 |
\end{figure}
|
| 1109 |
|
| 1110 |
A typical microcontroller allows operations on machine integers
|
| 1111 |
in the following steps:
|
| 1112 |
|
| 1113 |
\begin{itemize}
|
| 1114 |
\item A machine instruction is performed on one or two machine
|
| 1115 |
integer operands (for example: addition, subtraction,
|
| 1116 |
multiplication, division, increment, decrement, complement,
|
| 1117 |
negation, or comparison). This machine instruction may
|
| 1118 |
produce a result, and usually sets a number of condition flags that
|
| 1119 |
reflect the nature and validity of the result (Is it zero?
|
| 1120 |
Is it negative? Did the result overflow?). As an
|
| 1121 |
example, the condition
|
| 1122 |
flags of the TMS-370C8 are shown in Figure \ref{fig:ccil0:scpp0:00}.
|
| 1123 |
.
|
| 1124 |
\item A conditional branch instruction is used to branch conditionally
|
| 1125 |
based on the state of the condition flags. The definition of
|
| 1126 |
the condition flags and the way in which the conditional
|
| 1127 |
branch instruction utilizes them is designed to provide a
|
| 1128 |
way to treat both unsigned and signed machine integers.
|
| 1129 |
As an example, the way in which the conditional
|
| 1130 |
jump instructions of the TMS-370C8 use the flags
|
| 1131 |
is shown in Figure \ref{fig:ccil0:scpp0:01}.
|
| 1132 |
\end{itemize}
|
| 1133 |
|
| 1134 |
It is not too often necessary to understand in detail
|
| 1135 |
the Boolean relationships that govern how machine integers are
|
| 1136 |
added, subtracted, and compared; and how signed comparisons differ
|
| 1137 |
from unsigned comparisons. In most cases, it is adequate to
|
| 1138 |
rely on the design of the microcontroller. However, we do present
|
| 1139 |
rudimentary observations in this section.
|
| 1140 |
|
| 1141 |
|
| 1142 |
|
| 1143 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1144 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1145 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1146 |
\section{Comparison Of Integers}
|
| 1147 |
|
| 1148 |
|
| 1149 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1150 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1151 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1152 |
\subsection{Comparison Of Unsigned Integers}
|
| 1153 |
|
| 1154 |
|
| 1155 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1156 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1157 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1158 |
\subsection{Comparison Of Signed Integers}
|
| 1159 |
%Section Tag: CSI0
|
| 1160 |
\label{ccil0:scsi0}
|
| 1161 |
|
| 1162 |
|
| 1163 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1164 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1165 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1166 |
\section{Integer Addition}
|
| 1167 |
%Section tag: IAD0
|
| 1168 |
\label{ccil0:siad0}
|
| 1169 |
|
| 1170 |
Addition of two $m$-bit integers is a combinational function---that is,
|
| 1171 |
the inputs uniquely determine the output. Addition of binary
|
| 1172 |
numbers is performed
|
| 1173 |
|
| 1174 |
|
| 1175 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1176 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1177 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1178 |
\subsection{Hardware Implementation Of Addition}
|
| 1179 |
|
| 1180 |
|
| 1181 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1182 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1183 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1184 |
\subsection{Addition Of Unsigned Operands}
|
| 1185 |
|
| 1186 |
|
| 1187 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1188 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1189 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1190 |
\subsection{Addition Of Signed Operands}
|
| 1191 |
|
| 1192 |
|
| 1193 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1194 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1195 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1196 |
\section {Integer Subtraction}
|
| 1197 |
|
| 1198 |
|
| 1199 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1200 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1201 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1202 |
\subsection{Hardware Implementation Of Subtraction}
|
| 1203 |
|
| 1204 |
|
| 1205 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1206 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1207 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1208 |
\subsection{Subtraction Of Unsigned Operands}
|
| 1209 |
|
| 1210 |
|
| 1211 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1212 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1213 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1214 |
\subsection{Subtraction Of Signed Operands}
|
| 1215 |
|
| 1216 |
|
| 1217 |
|
| 1218 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1219 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1220 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1221 |
\section{Integer Multiplication}
|
| 1222 |
|
| 1223 |
|
| 1224 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1225 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1226 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1227 |
\subsection{Hardware Implementation Of Multiplication}
|
| 1228 |
|
| 1229 |
|
| 1230 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1231 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1232 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1233 |
\subsection{Multiplication Of Unsigned Operands}
|
| 1234 |
|
| 1235 |
|
| 1236 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1237 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1238 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1239 |
\subsection{Multiplication Of Signed Operands}
|
| 1240 |
|
| 1241 |
|
| 1242 |
|
| 1243 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1244 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1245 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1246 |
\section{Integer Division}
|
| 1247 |
\label{ccil0:sidv0}
|
| 1248 |
|
| 1249 |
\index{division}\index{integer division}In this section,
|
| 1250 |
we discuss the best known methods of dividing integers using
|
| 1251 |
typical microcontroller instruction sets. In general, given
|
| 1252 |
two arbitrary integers $p$ and $q$, we are interested in determining
|
| 1253 |
their quotient $q=\lfloor{}p/q\rfloor$ and remainder
|
| 1254 |
$r=p\bmod{}q$ as economically as possible.
|
| 1255 |
|
| 1256 |
|
| 1257 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1258 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1259 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1260 |
\subsection{Hardware Implementation Of Division}
|
| 1261 |
|
| 1262 |
|
| 1263 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1264 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1265 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1266 |
\subsection{General Unsigned Division Without A Machine Division Instruction}
|
| 1267 |
\label{ccil0:sidv0:sgdn0}
|
| 1268 |
|
| 1269 |
|
| 1270 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1271 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1272 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1273 |
\subsection{General Unsigned Division With A Machine Division Instruction}
|
| 1274 |
\label{ccil0:sidv0:sgdu0}
|
| 1275 |
|
| 1276 |
As mentioned many places in this work, efficiency in microcontroller software
|
| 1277 |
involves phrasing computational problems in a way which makes good use of
|
| 1278 |
the machine instruction set. In Section \ref{ccil0:sidv0:sgdn0} we discussed
|
| 1279 |
the classic shift-compare-subtract algorithm for division. This algorithm
|
| 1280 |
is far from efficient. A reasonable question to ask is whether we can
|
| 1281 |
leverage ``small'' division capability (provided by the machine instruction set)
|
| 1282 |
to accomplish ``large'' divisions (those which we require in practice).
|
| 1283 |
It ends up that this is possible: the technique involved is effectively
|
| 1284 |
to use machine division instructions to estimate the highest-order bits of
|
| 1285 |
the quotient based on the highest-order bits of the dividend and divisor.
|
| 1286 |
|
| 1287 |
Knuth's discussion of division
|
| 1288 |
algorithms \cite[pp. 270-275]{bibref:b:knuthclassic2ndedvol2} is the
|
| 1289 |
basis for most of the material in this subsection. However, Knuth has
|
| 1290 |
a gift for terseness that is sometimes a curse for the reader, and so
|
| 1291 |
we take more time than Knuth to explain certain results.
|
| 1292 |
|
| 1293 |
First, as a starting point, we present \emph{Algorithm D} from
|
| 1294 |
Knuth \cite[pp. 272-273]{bibref:b:knuthclassic2ndedvol2}. Then,
|
| 1295 |
we justify the algorithm and explain why it is valid. Finally,
|
| 1296 |
we supply implementation advice for microcontroller instruction sets.
|
| 1297 |
|
| 1298 |
\begin{vworkalgorithmstatementpar}{Arbitrary Unsigned Division Using
|
| 1299 |
Machine Unsigned Division Instructions}
|
| 1300 |
\label{alg:ccil0:sidv0:sgdu0:01}
|
| 1301 |
(From Knuth \cite[pp. 272-273]{bibref:b:knuthclassic2ndedvol2})
|
| 1302 |
Given nonnegative integers $u=(u_{m+n-1} \ldots{} u_1 u_0)_b$
|
| 1303 |
and $v=(v_{n-1} \ldots{} v_1 v_0)_b$, where
|
| 1304 |
$v_{n-1} \neq 0$ and $n > 1$, we form the radix-$b$ quotient
|
| 1305 |
$\lfloor{}u/v\rfloor{} = (q_m q_{m-1} \ldots{} q_0)_b$ and
|
| 1306 |
the remainder $u \bmod v = (r_{n-1} \ldots{} r_1 r_0)_b$. When
|
| 1307 |
$n=1$, the simpler algorithm of
|
| 1308 |
Subsection \ref{ccil0:sidv0:sldm0}
|
| 1309 |
should be used.
|
| 1310 |
|
| 1311 |
\begin{algblvl0}
|
| 1312 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:01}
|
| 1313 |
[Normalize.] Set $d \gets \lfloor{}b/(v_{n-1} + 1)\rfloor$.
|
| 1314 |
Then set $(u_{m+n} u_{m+n-1} \ldots{} u_1 u_0)_b$ equal to
|
| 1315 |
$(u_{m+n-1} \ldots{} u_1 u_0)_b$ times $d$; similarly,
|
| 1316 |
set $(v_{n-1} \ldots{} v_1 v_0)_b$ equal to
|
| 1317 |
$(v_{n-1} \ldots{} v_1 v_0)_b$ times $d$. (Notice the introduction
|
| 1318 |
of a new digit position $u_{m+n}$ at the left of
|
| 1319 |
$u_{m+n-1}$; if $d=1$, all we need to do in this step is set
|
| 1320 |
$u_{m+n} \gets 0$. On a binary computer it may be preferable
|
| 1321 |
to choose $d$ to be a power of 2 instead of using the value
|
| 1322 |
suggested here; any value of $d$ that results in
|
| 1323 |
$v_{n-1} \geq \lfloor{}b/2\rfloor$ will suffice. See also
|
| 1324 |
exercise 37.)
|
| 1325 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:02}
|
| 1326 |
[Initialize $j$.] Set $j \gets m$. (The loop on $j$,
|
| 1327 |
steps
|
| 1328 |
\ref{enumstep:alg:ccil0:sidv0:sgdu0:01:03}
|
| 1329 |
through
|
| 1330 |
\ref{enumstep:alg:ccil0:sidv0:sgdu0:01:07},
|
| 1331 |
will be essentially a division of
|
| 1332 |
$(u_{j+n} \ldots{} u_{j+1} u_j)_b$ by $(v_{n-1} \ldots{} v_1 v_0)_b$ to
|
| 1333 |
get a single quotient digit $q_j$; see Figure \ref{fig:alg:ccil0:sidv0:sgdu0:01:01}.)
|
| 1334 |
|
| 1335 |
\begin{figure}
|
| 1336 |
\centering
|
| 1337 |
\includegraphics[width=4.6in]{c_cil0/kdfc01.eps}
|
| 1338 |
\caption{Flowchart For Algorithm \ref{alg:ccil0:sidv0:sgdu0:01} (From \cite[p. 273]{bibref:b:knuthclassic2ndedvol2})}
|
| 1339 |
\label{fig:alg:ccil0:sidv0:sgdu0:01:01}
|
| 1340 |
\end{figure}
|
| 1341 |
|
| 1342 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:03}
|
| 1343 |
[Calculate $\hat{q}$.] Set
|
| 1344 |
$\hat{q} \gets \lfloor{}u_{j+n}b + u_{j+n-1})/v_{n-1}\rfloor$ and
|
| 1345 |
let $\hat{r}$ be the remainder, $(u_{j+n}b + u_{j+n-1}) \bmod v_{n-1}$.
|
| 1346 |
Now test if $\hat{q} = b$ or $\hat{q} v_{n-2} > b\hat{r} + u_{j+n-2}$;
|
| 1347 |
if so, decrease $\hat{q}$ by 1, increase $\hat{r}$ by $v_{n-1}$, and repeat
|
| 1348 |
this test if $\hat{r} < b$. (The test of $v_{n-2}$ determines at high
|
| 1349 |
speed most of the cases in which the trial value $\hat{q}$ is one too large,
|
| 1350 |
and it eliminates \emph{all} cases where $\hat{q}$ is two too large;
|
| 1351 |
see exercises 19, 20, 21.)
|
| 1352 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:04}
|
| 1353 |
[Multiply and subtract.] Replace $(u_{j+n} u_{j+n-1} \ldots{} u_j)_b$ by
|
| 1354 |
|
| 1355 |
\begin{equation}
|
| 1356 |
\nonumber
|
| 1357 |
(u_{j+n} u_{j+n-1} \ldots{} u_j)_b - \hat{q} (0 v_{n-1} \ldots{} v_1 v_0)_b.
|
| 1358 |
\end{equation}
|
| 1359 |
|
| 1360 |
This computation consists of a simple multiplication by a one-place number,
|
| 1361 |
combined with a subtraction. The digits $(u_{j+n}, u_{j+n-1}, \ldots{}, u_j)$
|
| 1362 |
should be kept positive; if the result of this step is actually negative,
|
| 1363 |
$(u_{j+n} u_{j+n-1} \ldots{} u_j)_b$ should be left as the true
|
| 1364 |
value plus $b^{n+1}$, namely as the $b$'s complement of the true value, and
|
| 1365 |
a ``borrow'' to the left should be remembered.
|
| 1366 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:05}
|
| 1367 |
[Test remainder.] Set $q_j \gets \hat{q}$. If the result of step
|
| 1368 |
\ref{enumstep:alg:ccil0:sidv0:sgdu0:01:04} was negative, go to
|
| 1369 |
step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:06}; otherwise go on to
|
| 1370 |
step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:07}.
|
| 1371 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:06}
|
| 1372 |
[Add back.] (The probability that this step is necessary is very small, on the
|
| 1373 |
order of only $2/b$, as shown in exercise 21; test data to activate this step
|
| 1374 |
should therefore be specifically contrived when debugging.) Decrease
|
| 1375 |
$q_j$ by 1, and add $(0 v_{n-1} \ldots v_1 v_0)_b$ to
|
| 1376 |
$(u_{j+n} u_{j+n-1} \ldots{} u_{j+1} u_j)_b$. (A carry will occur to the left of
|
| 1377 |
$u_{j+n}$, and it should be ignored since it cancels with the borrow that
|
| 1378 |
occured in step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:04}.)
|
| 1379 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:07}
|
| 1380 |
[Loop on $j$.] Decrease $j$ by one. Now if $j \geq 0$, go back to step
|
| 1381 |
\ref{enumstep:alg:ccil0:sidv0:sgdu0:01:03}.
|
| 1382 |
\item \label{enumstep:alg:ccil0:sidv0:sgdu0:01:08}
|
| 1383 |
[Unnormalize.] Now $(q_m \ldots{} q_1 q_0)_b$ is the desired quotient, and
|
| 1384 |
the desired remainder may be obtained by dividing
|
| 1385 |
$(u_{n-1} \ldots{} u_1 u_0)_b$ by $d$.
|
| 1386 |
\end{algblvl0}
|
| 1387 |
\end{vworkalgorithmstatementpar}
|
| 1388 |
\vworkalgorithmfooter{}
|
| 1389 |
|
| 1390 |
The general idea of Algorithm \ref{alg:ccil0:sidv0:sgdu0:01} is that
|
| 1391 |
digits (machine words) of the quotient $q$ can be successively estimated
|
| 1392 |
based on the first digits of the dividend and divisor. Knuth
|
| 1393 |
\cite[p. 271]{bibref:b:knuthclassic2ndedvol2} explores the properties of
|
| 1394 |
the digit estimate
|
| 1395 |
|
| 1396 |
\begin{equation}
|
| 1397 |
\label{eq:ccil0:sidv0:sgdu0:01}
|
| 1398 |
\hat{q} = \min \left( {\left\lfloor{\frac{u_n b + u_{n-1}}{v_{n-1}}}\right\rfloor, b-1} \right).
|
| 1399 |
\end{equation}
|
| 1400 |
|
| 1401 |
The first point to make about an estimate in the form of
|
| 1402 |
(\ref{eq:ccil0:sidv0:sgdu0:01}) is that it can only be accomplished
|
| 1403 |
efficiently if the machine-native division instruction supports
|
| 1404 |
overflow detection, since it is possible that
|
| 1405 |
$(u_n b + u_{n-1})/v_{n-1} \geq b$, even if
|
| 1406 |
$u/v < b$, as is shown by the following example.
|
| 1407 |
|
| 1408 |
\begin{vworkexamplestatement}
|
| 1409 |
\label{ex:ccil0:sidv0:sgdu0:01:01}
|
| 1410 |
Assume that we wish to apply the estimate of $\hat{q}$ provided by
|
| 1411 |
(\ref{eq:ccil0:sidv0:sgdu0:01})
|
| 1412 |
to $u=16,776,704$ and $v=65,535$. Demonstrate that a machine division
|
| 1413 |
overflow will occur when estimating the first digit, assuming a processor
|
| 1414 |
that can divide a 16-bit dividend by an 8-bit divisor to produce an 8-bit
|
| 1415 |
quotient.
|
| 1416 |
\end{vworkexamplestatement}
|
| 1417 |
\begin{vworkexampleparsection}{Solution}
|
| 1418 |
Note that according to Knuth's intention, the word size on such a machine
|
| 1419 |
is 8 bits. Thus, $b=256$. Note that $u/v = 255 + 255/256 < b = 256$, as
|
| 1420 |
required by Knuth's precondition. However, although $u/v < b$,
|
| 1421 |
$u = [255 \; 254 \; 0] [256^2 \; 256 \; 1]^T = [u_2 u_1 u_0] [b^2 b^1 b^0]^T$ and
|
| 1422 |
$v = [255 \; 255] [256 \; 1]^T = [v_1 v_0] [b^1 b^0]^T$, so that calculating
|
| 1423 |
an estimate $\hat{q}$ as required by (\ref{eq:ccil0:sidv0:sgdu0:01}),
|
| 1424 |
$(u_n b + u_{n-1})/v_{n-1} = 65,534/255 = 256 + 254/255 \geq b$, is a division
|
| 1425 |
overflow for a single machine division instruction. Thus, it follows that
|
| 1426 |
a machine with division overflow detection can quickly determine that $b-1$ from
|
| 1427 |
(\ref{eq:ccil0:sidv0:sgdu0:01}) is the minimum, whereas a machine without
|
| 1428 |
division overflow
|
| 1429 |
detection would have to use several additional machine instructions to make
|
| 1430 |
this determination.
|
| 1431 |
\end{vworkexampleparsection}
|
| 1432 |
\vworkexamplefooter{}
|
| 1433 |
|
| 1434 |
The second thing to establish about $\hat{q}$ as defined by
|
| 1435 |
(\ref{eq:ccil0:sidv0:sgdu0:01}) is how ``good'' of an estimate
|
| 1436 |
$\hat{q}$ is---how much information, exactly, about $q$ can we
|
| 1437 |
obtain by examining the first two words of $u$ and the first
|
| 1438 |
word of $v$?
|
| 1439 |
|
| 1440 |
We first establish in the following lemma that our estimate of
|
| 1441 |
$q$, $\hat{q}$, can be no less than $q$.
|
| 1442 |
|
| 1443 |
\begin{vworklemmastatementpar}{\mbox{\boldmath$\hat{q} \geq q$}}
|
| 1444 |
\label{lem:ccil0:sidv0:sgdu0:01}
|
| 1445 |
The estimate of $q$ provided by (\ref{eq:ccil0:sidv0:sgdu0:01}),
|
| 1446 |
$\hat{q}$ is always at least as great as the actual value of
|
| 1447 |
$q$, i.e. $\hat{q} \geq q$.
|
| 1448 |
\end{vworklemmastatementpar}
|
| 1449 |
\begin{vworklemmaproof}
|
| 1450 |
Knowledge of $u_{n}$, $u_{n-1}$, and $v_{n-1}$ necessarily confine
|
| 1451 |
the intervals in which the actual values of $u$ and $v$ may be;
|
| 1452 |
specifically:\footnote{In
|
| 1453 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:04})
|
| 1454 |
and
|
| 1455 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:07}),
|
| 1456 |
we use statements of the form ``$x = x$'' as an idiom for
|
| 1457 |
``$x$ is known''.}
|
| 1458 |
|
| 1459 |
\begin{eqnarray}
|
| 1460 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:01}
|
| 1461 |
u & = & \sum_{i=0}^{n} u_i b^i \\
|
| 1462 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:02}
|
| 1463 |
& = & u_n b^n + u_{n-1} b^{n-1} + \ldots{} + u_2 b^2 + u_1 b + u_0 \\
|
| 1464 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:03}
|
| 1465 |
& = & (u_n b + u_{n-1}) b^{n-1} + \ldots{} + u_2 b^2 + u_1 b + u_0
|
| 1466 |
\end{eqnarray}
|
| 1467 |
|
| 1468 |
\begin{eqnarray}
|
| 1469 |
\nonumber & (u_n = u_n \wedge u_{n-1} = u_{n-1}) & \\
|
| 1470 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:04}
|
| 1471 |
& \vworkvimp & \\
|
| 1472 |
\nonumber & (u_n b + u_{n-1}) b^{n-1} \leq u \leq (u_n b + u_{n-1}) b^{n-1} + b^{n-1} - 1 &
|
| 1473 |
\end{eqnarray}
|
| 1474 |
|
| 1475 |
\begin{eqnarray}
|
| 1476 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:05}
|
| 1477 |
v & = & \sum_{i=0}^{n-1} v_i b^i \\
|
| 1478 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:06}
|
| 1479 |
& = & v_{n-1} b^{n-1} + v_{n-2} b^{n-2} + \ldots{} + v_2 b^2 + v_1 b + v_0
|
| 1480 |
\end{eqnarray}
|
| 1481 |
|
| 1482 |
\begin{equation}
|
| 1483 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:07}
|
| 1484 |
(v_{n-1} = v_{n-1})
|
| 1485 |
\vworkhimp
|
| 1486 |
v_{n-1} b^{n-1} \leq v \leq v_{n-1} b^{n-1} + b^{n-1} - 1
|
| 1487 |
\end{equation}
|
| 1488 |
|
| 1489 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:04}) and
|
| 1490 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:07}) reflect the uncertainties in the
|
| 1491 |
values of $u$ and $v$ respectively because only the first digit(s) of
|
| 1492 |
$u$ and $v$ are being considered in forming the estimate $\hat{q}$.
|
| 1493 |
|
| 1494 |
By definition, the actual value of $q$ is $\lfloor{}u/v\rfloor$. For a
|
| 1495 |
rational function $f(u,v) = u/v$ where $u \in [u_{min}, u_{max}]$ and
|
| 1496 |
$v \in [v_{min}, v_{max}]$, the minimum value of $u/v$ occurs at
|
| 1497 |
$u_{min}/v_{max}$, and the maximum value of $u/v$ occurs at
|
| 1498 |
$u_{max}/v_{min}$. We can therefore write that
|
| 1499 |
|
| 1500 |
\begin{equation}
|
| 1501 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:08}
|
| 1502 |
\left\lfloor{\frac{(u_n b + u_{n-1}) b^{n-1}}{v_{n-1} b^{n-1} + b^{n-1} - 1}}\right\rfloor
|
| 1503 |
\leq
|
| 1504 |
q
|
| 1505 |
\leq
|
| 1506 |
\left\lfloor{\frac{(u_n b + u_{n-1}) b^{n-1} + b^{n-1} - 1}{v_{n-1} b^{n-1}}}\right\rfloor .
|
| 1507 |
\end{equation}
|
| 1508 |
|
| 1509 |
In other words, knowledge of $u_{n}$, $u_{n-1}$, and $v_{n-1}$ confines $q$ to the
|
| 1510 |
interval indicated in (\ref{eq:lem:ccil0:sidv0:sgdu0:01:08}). We must prove that,
|
| 1511 |
given a specific $u_{n}$, $u_{n-1}$, and $v_{n-1}$, $\hat{q}$ is at least as large as
|
| 1512 |
the upper bound in (\ref{eq:lem:ccil0:sidv0:sgdu0:01:08}); otherwise we could find a
|
| 1513 |
$q$ such that $q > \hat{q}$. We can algebraically manipulate the upper bound in
|
| 1514 |
in (\ref{eq:lem:ccil0:sidv0:sgdu0:01:08}) to yield
|
| 1515 |
|
| 1516 |
\begin{equation}
|
| 1517 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:09}
|
| 1518 |
\left\lfloor{\frac{(u_n b + u_{n-1}) b^{n-1}}{v_{n-1} b^{n-1} + b^{n-1} - 1}}\right\rfloor
|
| 1519 |
\leq
|
| 1520 |
q
|
| 1521 |
\leq
|
| 1522 |
\left\lfloor{\frac{u_n b + u_{n-1} + \frac{b^{n-1}-1}{b^{n-1}}}{v_{n-1}}}\right\rfloor .
|
| 1523 |
\end{equation}
|
| 1524 |
|
| 1525 |
In (\ref{eq:lem:ccil0:sidv0:sgdu0:01:09}), since $(b^{n-1}-1)/b^{n-1} < 1$ and since
|
| 1526 |
$u_n b + u_{n-1}$ is an integer, we can conclude that
|
| 1527 |
$\lfloor u_n b + u_{n-1} + (b^{n-1}-1)/b^{n-1} \rfloor = \lfloor u_n b + u_{n-1} \rfloor$
|
| 1528 |
and hence that
|
| 1529 |
|
| 1530 |
\begin{equation}
|
| 1531 |
\label{eq:lem:ccil0:sidv0:sgdu0:01:10}
|
| 1532 |
q
|
| 1533 |
\leq
|
| 1534 |
\left\lfloor{\frac{u_n b + u_{n-1} + \frac{b^{n-1}-1}{b^{n-1}}}{v_{n-1}}}\right\rfloor
|
| 1535 |
=
|
| 1536 |
\left\lfloor{\frac{u_n b + u_{n-1}}{v_{n-1}}}\right\rfloor
|
| 1537 |
=
|
| 1538 |
\hat{q} .
|
| 1539 |
\end{equation}
|
| 1540 |
|
| 1541 |
Therefore, $\hat{q} \geq q$.
|
| 1542 |
\end{vworklemmaproof}
|
| 1543 |
\vworklemmafooter{}
|
| 1544 |
|
| 1545 |
Lemma \ref{lem:ccil0:sidv0:sgdu0:01} establishes that
|
| 1546 |
a digit estimate $\hat{q}$ based on the first digit of the
|
| 1547 |
divisor $v$ can be no less than the actual digit $q$, i.e.
|
| 1548 |
$\hat{q}-q \geq 0$. However, we must also establish an upper bound
|
| 1549 |
on $\hat{q}-q$.
|
| 1550 |
|
| 1551 |
Intuitively, based on
|
| 1552 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:06}), we might guess that
|
| 1553 |
if $v_{n-1}$ is small, the estimate $\hat{q}$ may be quite
|
| 1554 |
poor, as the interval to which the actual value of $v$ is confined
|
| 1555 |
may be quite large. This fact is the basis for the normalization
|
| 1556 |
step [\ref{enumstep:alg:ccil0:sidv0:sgdu0:01:01}] in Algorithm
|
| 1557 |
\ref{alg:ccil0:sidv0:sgdu0:01}. We now prove a useful result
|
| 1558 |
for how much $u, v$ must be normalized so that $\hat{q}-q \leq 2$.
|
| 1559 |
|
| 1560 |
\begin{vworklemmastatementpar}{Normalization Requirement So That
|
| 1561 |
\mbox{\boldmath$\hat{q} - q \leq 2$}}
|
| 1562 |
\label{lem:ccil0:sidv0:sgdu0:02}
|
| 1563 |
If $v_{n-1} \geq \lfloor b/2 \rfloor$ and $\hat{q}$ is chosen as
|
| 1564 |
indicated in (\ref{eq:ccil0:sidv0:sgdu0:01}), then
|
| 1565 |
$0 \leq \hat{q} - q \leq 2$.
|
| 1566 |
\end{vworklemmastatementpar}
|
| 1567 |
\begin{vworklemmaproof}
|
| 1568 |
The lower limit on $\hat{q} - q$ is proved in Lemma \ref{lem:ccil0:sidv0:sgdu0:01}.
|
| 1569 |
We now seek only to prove that $\hat{q} - q \leq 2$.
|
| 1570 |
By definition of $\hat{q}$ and $q$,
|
| 1571 |
|
| 1572 |
\begin{equation}
|
| 1573 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:01}
|
| 1574 |
\hat{q} - q = \left\lfloor {\frac{u_n b + u_{n-1}}{v_{n-1}}} \right\rfloor
|
| 1575 |
- \left\lfloor {\frac{u}{v}} \right\rfloor
|
| 1576 |
\end{equation}
|
| 1577 |
|
| 1578 |
When only nonnegative integers are involved,
|
| 1579 |
(\cmtnzeroxrefhyphen\ref{eq:cmtn0:sfcf0:02})
|
| 1580 |
supplies an exact expression for the floor of a
|
| 1581 |
ratio of integers. Using (\cmtnzeroxrefhyphen\ref{eq:cmtn0:sfcf0:02}),
|
| 1582 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:01}) can be decomposed into
|
| 1583 |
|
| 1584 |
\begin{equation}
|
| 1585 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:02}
|
| 1586 |
\hat{q} - q = \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1587 |
- \frac{(u_n b + u_{n-1}) \bmod v_{n-1}}{v_{n-1}}
|
| 1588 |
- \frac{u}{v}
|
| 1589 |
+ \frac{u \bmod v}{v} .
|
| 1590 |
\end{equation}
|
| 1591 |
|
| 1592 |
\noindent{}Note that (\ref{eq:lem:ccil0:sidv0:sgdu0:02:02}) is an exact
|
| 1593 |
expression (rather than an
|
| 1594 |
inequality).
|
| 1595 |
|
| 1596 |
Note in (\ref{eq:lem:ccil0:sidv0:sgdu0:02:02}) that
|
| 1597 |
$(u_n b + u_{n-1}) \bmod v_{n-1} \in [0, v_{n-1}-1]$, and that in general
|
| 1598 |
there is no reason to expect it cannot be zero. Thus, we can assume that
|
| 1599 |
it \emph{is} zero, which will maximize $\hat{q}-q$. We can thus convert
|
| 1600 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:02}) into the inequality
|
| 1601 |
|
| 1602 |
\begin{equation}
|
| 1603 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:03}
|
| 1604 |
\hat{q} - q \leq \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1605 |
- \frac{u}{v}
|
| 1606 |
+ \frac{u \bmod v}{v} .
|
| 1607 |
\end{equation}
|
| 1608 |
|
| 1609 |
In (\ref{eq:lem:ccil0:sidv0:sgdu0:02:03}) we can also observe that
|
| 1610 |
$(u \bmod v)/v \in [0, (v-1)/v]$. If we replace this expression with
|
| 1611 |
``1'' (which is unattainable, but barely), this will change the relational
|
| 1612 |
operator from ``$\leq$'' to ``$<$'':
|
| 1613 |
|
| 1614 |
\begin{equation}
|
| 1615 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:04}
|
| 1616 |
\hat{q} - q < \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1617 |
- \frac{u}{v}
|
| 1618 |
+ 1 .
|
| 1619 |
\end{equation}
|
| 1620 |
|
| 1621 |
The result we wish to show is that with $v_{n-1} \geq \lfloor b/2 \rfloor$,
|
| 1622 |
$\hat{q}-q \leq 2$. To simplify the subsequent algebraic manipulations, note in
|
| 1623 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:04}) that
|
| 1624 |
|
| 1625 |
\begin{eqnarray}
|
| 1626 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:05}
|
| 1627 |
& \hat{q} - q \leq 2 & \\
|
| 1628 |
\nonumber & \vworkvertequiv & \\
|
| 1629 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:06}
|
| 1630 |
& \displaystyle \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1631 |
- \frac{u}{v}
|
| 1632 |
+ 1 \leq 3 & \\
|
| 1633 |
\nonumber & \vworkvertequiv & \\
|
| 1634 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:07}
|
| 1635 |
& \displaystyle \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1636 |
- \frac{u}{v} \leq 2 &
|
| 1637 |
\end{eqnarray}
|
| 1638 |
|
| 1639 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:06}) may be counterintuitive, so
|
| 1640 |
further explanation is offered here. Since $\hat{q} \in \vworkintset$ and $q \in \vworkintset$,
|
| 1641 |
$\hat{q}-q \in \vworkintset$. Thus, proving
|
| 1642 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:06}) or
|
| 1643 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:07}) proves that
|
| 1644 |
$\hat{q}-q \in \{ \ldots, -1, 0, 1, 2 \}$ (however, by
|
| 1645 |
Lemma \ref{lem:ccil0:sidv0:sgdu0:01}, $\hat{q}-q \geq 0$, so in fact
|
| 1646 |
what would be proved is that $\hat{q}-q \in \{ 0, 1, 2 \}$). For
|
| 1647 |
algebraic simplicity,
|
| 1648 |
we choose to prove (\ref{eq:lem:ccil0:sidv0:sgdu0:02:07}).
|
| 1649 |
|
| 1650 |
First, adjust numerator and denominator of the first term in
|
| 1651 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:07}) by $b^{n-1}$ so that the terms more closely
|
| 1652 |
resemble $u$ and $v$ in
|
| 1653 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:02})
|
| 1654 |
and
|
| 1655 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:01:06}):
|
| 1656 |
|
| 1657 |
\begin{equation}
|
| 1658 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:08}
|
| 1659 |
\frac{u_n b^n + u_{n-1} b^{n-1}}{v_{n-1} b^{n-1}}
|
| 1660 |
- \frac{u}{v} \leq 2 .
|
| 1661 |
\end{equation}
|
| 1662 |
|
| 1663 |
For logical implication to be maintained,
|
| 1664 |
we must make the most pessimistic choices and assumptions possible in
|
| 1665 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:08}) in order to maximize the value
|
| 1666 |
of the left side of the inequality.
|
| 1667 |
The first assumption to be made is the error in estimating
|
| 1668 |
$u$ and $v$ based on their most significant digits. It can be
|
| 1669 |
seen that (\ref{eq:lem:ccil0:sidv0:sgdu0:02:08}) will be maximized if:
|
| 1670 |
|
| 1671 |
\begin{itemize}
|
| 1672 |
\item We assume that $u = u_{n} b^n + u_{n-1} b^{n-1}$ (i.e. that we estimate
|
| 1673 |
$u$ precisely).
|
| 1674 |
\item We assume that $v = v_{n-1} b^{n-1} + b^{n-1} - 1$ (i.e. that
|
| 1675 |
we underestimate $v$ by the maximum amount possible).
|
| 1676 |
\item We minimize the value of $v_{n-1} b^{n-1}$.
|
| 1677 |
\end{itemize}
|
| 1678 |
|
| 1679 |
Assuming that $u$ is estimated precisely yields
|
| 1680 |
|
| 1681 |
\begin{equation}
|
| 1682 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:09}
|
| 1683 |
\frac{u}{v_{n-1} b^{n-1}}
|
| 1684 |
- \frac{u}{v} \leq 2 .
|
| 1685 |
\end{equation}
|
| 1686 |
|
| 1687 |
Assuming that $v$ is underestimated by the maximum amount possible
|
| 1688 |
yields
|
| 1689 |
|
| 1690 |
\begin{equation}
|
| 1691 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:10}
|
| 1692 |
\frac{u}{v - b^{n-1} + 1}
|
| 1693 |
- \frac{u}{v} \leq 2 .
|
| 1694 |
\end{equation}
|
| 1695 |
|
| 1696 |
Finally, with $b$ and $v$ fixed, $u$ can be maximized by noting that
|
| 1697 |
$u \leq bv - 1$ (by the problem assumption that the quotient is a single digit).
|
| 1698 |
However, for algebraic simplicity, we make the substitution $u=bv$ (rather than
|
| 1699 |
$u=bv-1$), since the weaker upper bound is strong enough to prove the
|
| 1700 |
first result we seek.
|
| 1701 |
|
| 1702 |
\begin{equation}
|
| 1703 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:11}
|
| 1704 |
\frac{bv}{v - b^{n-1} + 1}
|
| 1705 |
- \frac{bv}{v} \leq 2
|
| 1706 |
\end{equation}
|
| 1707 |
|
| 1708 |
\begin{equation}
|
| 1709 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:12}
|
| 1710 |
\frac{bv}{v - b^{n-1} + 1}
|
| 1711 |
- b \leq 2
|
| 1712 |
\end{equation}
|
| 1713 |
|
| 1714 |
Solving (\ref{eq:lem:ccil0:sidv0:sgdu0:02:12})
|
| 1715 |
for $v$ yields
|
| 1716 |
|
| 1717 |
\begin{equation}
|
| 1718 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:13}
|
| 1719 |
v \geq \frac{b^n}{2} + b^{n-1} - \frac{1}{b} - 1
|
| 1720 |
\end{equation}
|
| 1721 |
|
| 1722 |
Again using the assumption that $v$ is underestimated by the maximum amount
|
| 1723 |
possible, we may make the substitution that $v = v_{n-1} b^{n-1} + b^{n-1} -1$,
|
| 1724 |
leading to
|
| 1725 |
|
| 1726 |
\begin{equation}
|
| 1727 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:13b}
|
| 1728 |
v_{n-1} \geq \frac{b}{2} - \frac{1}{2 b^{n-2}} .
|
| 1729 |
\end{equation}
|
| 1730 |
|
| 1731 |
There are two cases to consider: $b$ even and $b$ odd. If $b$ is even, the
|
| 1732 |
proof is complete, as $\lfloor b/2 \rfloor = b/2$ and the choice of
|
| 1733 |
$v_{n-1} = \lfloor b/2 \rfloor$ will automatically satisfy
|
| 1734 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:13b}). However, if $b$ is odd,
|
| 1735 |
$\lfloor b/2 \rfloor = b/2 - 1/2 < b/2 - 1/2b^{n-2}$, violating
|
| 1736 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:13b}),
|
| 1737 |
and so we need to
|
| 1738 |
further examine this case.
|
| 1739 |
|
| 1740 |
If $b$ is odd and $v_{n-1} = \lfloor b/2 \rfloor$, then
|
| 1741 |
$v_{n-1} = b/2 - 1/2$, violating (\ref{eq:lem:ccil0:sidv0:sgdu0:02:13b}).
|
| 1742 |
However, any larger choice of $v_{n-1}$ (such as
|
| 1743 |
$\lfloor b/2 \rfloor + 1$, $\lfloor b/2 \rfloor + 2$, etc.) satisfies
|
| 1744 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:13b}); so that it remains only to prove
|
| 1745 |
the $v_{n-1} = \lfloor b/2 \rfloor = b/2 - 1/2$
|
| 1746 |
case.
|
| 1747 |
|
| 1748 |
If $v_{n-1} = \lfloor b/2 \rfloor = b/2 - 1/2$, then
|
| 1749 |
|
| 1750 |
\begin{eqnarray}
|
| 1751 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:14}
|
| 1752 |
v & \in & \left[
|
| 1753 |
\left( \frac{b}{2} - \frac{1}{2}\right) b^{n-1},
|
| 1754 |
\left( \frac{b}{2} - \frac{1}{2}\right) b^{n-1} + b^{n-1} - 1
|
| 1755 |
\right] \\
|
| 1756 |
\nonumber & = &
|
| 1757 |
\left[
|
| 1758 |
\frac{b^n}{2} - \frac{b^{n-1}}{2},
|
| 1759 |
\frac{b^n}{2} + \frac{b^{n-1}}{2} -1
|
| 1760 |
\right] .
|
| 1761 |
\end{eqnarray}
|
| 1762 |
|
| 1763 |
Note in this case that the estimation error ($v - v_{n-1}b^{n-1}$) and the
|
| 1764 |
value of $v$ are not independent; and in fact it is this aspect
|
| 1765 |
of the problem that has led to the violation of
|
| 1766 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:13b}) with $b$ odd and
|
| 1767 |
$v_{n-1} = \lfloor b/2 \rfloor$.
|
| 1768 |
|
| 1769 |
In order to prove the case of $b$ odd and $v = \lfloor b/2 \rfloor = b/2 - 1/2$,
|
| 1770 |
we must reexamine some simplifying assumptions made earlier in order to obtain
|
| 1771 |
tighter inequalities. In (\ref{eq:lem:ccil0:sidv0:sgdu0:02:02}), we can no
|
| 1772 |
longer accept the maximum of $(u \bmod v)/v$ as one; instead we construct the
|
| 1773 |
tighter inequality
|
| 1774 |
|
| 1775 |
\begin{eqnarray}
|
| 1776 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:15}
|
| 1777 |
& \displaystyle \hat{q} - q \leq \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1778 |
- \frac{u}{v}
|
| 1779 |
+ \frac{u \bmod v}{v} & \\
|
| 1780 |
\nonumber & \vworkvimp & \\
|
| 1781 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:16}
|
| 1782 |
& \displaystyle \hat{q} - q \leq \frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1783 |
- \frac{u}{v}
|
| 1784 |
+ \frac{v-1}{v} , &
|
| 1785 |
\end{eqnarray}
|
| 1786 |
|
| 1787 |
which leads to
|
| 1788 |
|
| 1789 |
\begin{equation}
|
| 1790 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:17}
|
| 1791 |
\frac{u_n b + u_{n-1}}{v_{n-1}}
|
| 1792 |
- \frac{u+1}{v}
|
| 1793 |
< 2 .
|
| 1794 |
\end{equation}
|
| 1795 |
|
| 1796 |
In order to maximize the left-hand side of
|
| 1797 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:17}), we assume that we
|
| 1798 |
estimate $u$ exactly so that $u = u_n b^n + u_{n-1} b^{n-1}$,
|
| 1799 |
yielding
|
| 1800 |
|
| 1801 |
\begin{equation}
|
| 1802 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:18}
|
| 1803 |
\frac{u}{v_{n-1} b^{n-1}}
|
| 1804 |
- \frac{u+1}{v}
|
| 1805 |
< 2 .
|
| 1806 |
\end{equation}
|
| 1807 |
|
| 1808 |
We also assume that $u$ is the maximum value
|
| 1809 |
possible, $u=bv-1$, leading to
|
| 1810 |
|
| 1811 |
\begin{equation}
|
| 1812 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:19}
|
| 1813 |
\frac{bv-1}{v_{n-1} b^{n-1}}
|
| 1814 |
- b
|
| 1815 |
< 2 .
|
| 1816 |
\end{equation}
|
| 1817 |
|
| 1818 |
Finally, we assume that $v$ is the upper limit in
|
| 1819 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:02:14}),
|
| 1820 |
$v=b^n/2 + b^{n-1}/2 - 1$, and substitute the known value of
|
| 1821 |
$v_{n-1}$ for the case being proved, $v_{n-1} = b/2-1/2$, yielding
|
| 1822 |
|
| 1823 |
\begin{equation}
|
| 1824 |
\label{eq:lem:ccil0:sidv0:sgdu0:02:20}
|
| 1825 |
\frac{b \left( \frac{b^n}{2} + \frac{b^{n-1}}{2} - 1 \right) - 1}
|
| 1826 |
{\left( \frac{b}{2} - \frac{1}{2} \right) b^{n-1}}
|
| 1827 |
- b
|
| 1828 |
< 2 .
|
| 1829 |
\end{equation}
|
| 1830 |
|
| 1831 |
Simplification of (\ref{eq:lem:ccil0:sidv0:sgdu0:02:20})
|
| 1832 |
will establish that it is always true. This completes the proof.
|
| 1833 |
\end{vworklemmaproof}
|
| 1834 |
\vworklemmafooter{}
|
| 1835 |
|
| 1836 |
Lemmas \ref{lem:ccil0:sidv0:sgdu0:01} and
|
| 1837 |
\ref{lem:ccil0:sidv0:sgdu0:02},
|
| 1838 |
standing alone, lead to a good implementation of
|
| 1839 |
division without any further results. If it is known that
|
| 1840 |
$0 \leq \hat{q} - q \leq 2$, Algorithm \ref{alg:ccil0:sidv0:sgdu0:01}
|
| 1841 |
can be trivially modified to only calculate
|
| 1842 |
$\hat{q}$ (omitting the additional tests in Step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:03}),
|
| 1843 |
and then
|
| 1844 |
to include up to two add-back steps
|
| 1845 |
(duplication of Step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:06}).
|
| 1846 |
Although such an algorithm would be
|
| 1847 |
satisfactory, it has the disadvantage that the add-back steps would
|
| 1848 |
be executed very frequently, slowing the algorithm substantially, especially
|
| 1849 |
for long operands.
|
| 1850 |
We now show that the additional tests in Step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:03} of
|
| 1851 |
Algorithm \ref{alg:ccil0:sidv0:sgdu0:01} can eliminate
|
| 1852 |
altogether the case of $\hat{q}-q = 2$ (Lemma \ref{lem:ccil0:sidv0:sgdu0:03}), and
|
| 1853 |
can with a probability close to unity eliminate the
|
| 1854 |
case of $\hat{q}-q = 1$ (Lemmas \ref{lem:ccil0:sidv0:sgdu0:04}
|
| 1855 |
and \ref{lem:ccil0:sidv0:sgdu0:05}). Together these tests, which are present in
|
| 1856 |
the statement of Algorithm \ref{alg:ccil0:sidv0:sgdu0:01},
|
| 1857 |
reduce add-back (Step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:06}) to rare occurrence, and create a more
|
| 1858 |
efficient algorithm than would be possible with the
|
| 1859 |
results of Lemmas \ref{lem:ccil0:sidv0:sgdu0:01} and \ref{lem:ccil0:sidv0:sgdu0:02} alone.
|
| 1860 |
|
| 1861 |
\begin{vworklemmastatementpar}
|
| 1862 |
{\mbox{\boldmath$\hat{q} v_{n-2} \leq b \hat{r} + u_{j+n-2} \vworkhimp 0 \leq \hat{q} - q \leq 1$}}
|
| 1863 |
\label{lem:ccil0:sidv0:sgdu0:03}
|
| 1864 |
If the divisor normalization requirement ($v_{n-1} \geq \lfloor b/2 \rfloor$) as specified in
|
| 1865 |
Step \ref{enumstep:alg:ccil0:sidv0:sgdu0:01:01} of
|
| 1866 |
Algorithm \ref{alg:ccil0:sidv0:sgdu0:01} is met, then
|
| 1867 |
|
| 1868 |
\begin{equation}
|
| 1869 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:01}
|
| 1870 |
\hat{q} v_{n-2} \leq b \hat{r} + u_{j+n-2} \vworkhimp 0 \leq \hat{q} - q \leq 1 .
|
| 1871 |
\end{equation}
|
| 1872 |
\end{vworklemmastatementpar}
|
| 1873 |
\begin{vworklemmaproof}
|
| 1874 |
For reference, note that:
|
| 1875 |
|
| 1876 |
\begin{eqnarray}
|
| 1877 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:02}
|
| 1878 |
u & = & u_{j+n} b^{j+n} + u_{j+n-1} b^{j+n-1} + \ldots{} + u_1 b + u_0 \\
|
| 1879 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:03}
|
| 1880 |
v & = & v_{n-1} b^{n-1} + v_{n-2} b^{n-2} + \ldots{} + v_1 b + v_0
|
| 1881 |
\end{eqnarray}
|
| 1882 |
|
| 1883 |
By definition, we the remainder
|
| 1884 |
$\hat{r}$ has the value
|
| 1885 |
$\hat{r} = u_{j+n} b + u_{j+n-1} - \hat{q} v_{n-1}$. Substituting this value
|
| 1886 |
into (\ref{eq:lem:ccil0:sidv0:sgdu0:03:01}) produces
|
| 1887 |
|
| 1888 |
\begin{equation}
|
| 1889 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:04}
|
| 1890 |
\hat{q} v_{n-2} \leq b (u_{j+n} b + u_{j+n-1} - \hat{q} v_{n-1}) + u_{j+n-2} ,
|
| 1891 |
\end{equation}
|
| 1892 |
|
| 1893 |
and solving for $\hat{q}$ yields
|
| 1894 |
|
| 1895 |
\begin{equation}
|
| 1896 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:05}
|
| 1897 |
\hat{q} \leq \frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}}.
|
| 1898 |
\end{equation}
|
| 1899 |
|
| 1900 |
It is known from Lemma \ref{lem:ccil0:sidv0:sgdu0:01} that the type of estimate
|
| 1901 |
represented by the floor of the right-hand size of (\ref{eq:lem:ccil0:sidv0:sgdu0:03:05})
|
| 1902 |
can be no less than $q$, leading to
|
| 1903 |
|
| 1904 |
\begin{eqnarray}
|
| 1905 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:06}
|
| 1906 |
& \displaystyle q \leq \hat{q}
|
| 1907 |
\leq
|
| 1908 |
\left\lfloor { \frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}} } \right\rfloor & \\
|
| 1909 |
\nonumber & \displaystyle \leq
|
| 1910 |
\frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}}. &
|
| 1911 |
\end{eqnarray}
|
| 1912 |
|
| 1913 |
Because $q, \hat{q} \in \vworkintset$, it is only necessary to prove that
|
| 1914 |
|
| 1915 |
\begin{equation}
|
| 1916 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:07}
|
| 1917 |
\frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}} -
|
| 1918 |
\left\lfloor \frac{u}{v} \right\rfloor
|
| 1919 |
< 2
|
| 1920 |
\end{equation}
|
| 1921 |
|
| 1922 |
in order to prove that $\hat{q}-q \leq 1$. Using
|
| 1923 |
(\cmtnzeroxrefhyphen\ref{eq:cmtn0:sfcf0:02}),
|
| 1924 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:03:07}) can be rewritten as
|
| 1925 |
|
| 1926 |
\begin{equation}
|
| 1927 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:08}
|
| 1928 |
\frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}} -
|
| 1929 |
\frac{u}{v} -
|
| 1930 |
\frac{u \bmod v}{v}
|
| 1931 |
< 2 .
|
| 1932 |
\end{equation}
|
| 1933 |
|
| 1934 |
In order for implication to hold, we must make the most pessimistic
|
| 1935 |
assumptions about $u \bmod v$ (those which maximize it). The maximum value
|
| 1936 |
of $u \bmod v$ is $v-1$, leading to
|
| 1937 |
|
| 1938 |
\begin{equation}
|
| 1939 |
\label{eq:lem:ccil0:sidv0:sgdu0:03:09}
|
| 1940 |
\frac{u_{j+n} b^2 + u_{j+n-1}b + u_{j+n-2}}{v_{n-1}b + v_{n-2}} -
|
| 1941 |
\frac{u + 1}{v}
|
| 1942 |
< 1 .
|
| 1943 |
\end{equation}
|
| 1944 |
|
| 1945 |
In order to maximize the left side of (\ref{}),
|
| 1946 |
we must assume that $u$ is maximized, $v$ is minimized,
|
| 1947 |
|
| 1948 |
|
| 1949 |
\end{vworklemmaproof}
|
| 1950 |
\vworklemmafooter{}
|
| 1951 |
|
| 1952 |
\begin{vworklemmastatementpar}
|
| 1953 |
{\mbox{\boldmath$\hat{q} v_{n-2} > b \hat{r} + u_{n-2} \vworkhimp q < \hat{q}$}}
|
| 1954 |
\label{lem:ccil0:sidv0:sgdu0:04}
|
| 1955 |
Given $\hat{q} > 0$, an estimate of $q$, and the remainder
|
| 1956 |
based on the estimate, $\hat{r} = u_n b + u_{n-1} - \hat{q} v_{n-1}$,
|
| 1957 |
|
| 1958 |
\begin{equation}
|
| 1959 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:01}
|
| 1960 |
\hat{q} v_{n-2} > b \hat{r} + u_{n-2} \vworkhimp \hat{q} > q .
|
| 1961 |
\end{equation}
|
| 1962 |
\end{vworklemmastatementpar}
|
| 1963 |
\begin{vworklemmaproof}
|
| 1964 |
We make the assumption that $v_{n-1}$ and $v_{n-2}$ are not both 0.
|
| 1965 |
$v_{n-1} > 0$ is guaranteed by
|
| 1966 |
the normalization of
|
| 1967 |
$v$ in Algorithm \ref{alg:ccil0:sidv0:sgdu0:01}.
|
| 1968 |
|
| 1969 |
\begin{equation}
|
| 1970 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:02}
|
| 1971 |
\hat{q} v_{n-2} > b \hat{r} + u_{n-2}
|
| 1972 |
\end{equation}
|
| 1973 |
|
| 1974 |
\begin{equation}
|
| 1975 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:03}
|
| 1976 |
\hat{q} v_{n-2} > b (u_n b + u_{n-1} - \hat{q} v_{n-1}) + u_{n-2}
|
| 1977 |
\end{equation}
|
| 1978 |
|
| 1979 |
Solving (\ref{eq:lem:ccil0:sidv0:sgdu0:04:03}) for $\hat{q}$ yields
|
| 1980 |
|
| 1981 |
\begin{equation}
|
| 1982 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:04}
|
| 1983 |
\hat{q}
|
| 1984 |
>
|
| 1985 |
\frac{u_n b^2 + u_{n-1} b + u_{n-2}}{v_{n-1} b + v_{n-2}}
|
| 1986 |
\geq
|
| 1987 |
\left\lfloor {\frac{u_n b^2 + u_{n-1} b + u_{n-2}}{v_{n-1} b + v_{n-2}}} \right\rfloor
|
| 1988 |
.
|
| 1989 |
\end{equation}
|
| 1990 |
|
| 1991 |
Note that the right-hand term of
|
| 1992 |
(\ref{eq:lem:ccil0:sidv0:sgdu0:04:04})
|
| 1993 |
is similar in form to the estimate $\hat{q}$ in
|
| 1994 |
Lemma \ref{lem:ccil0:sidv0:sgdu0:01}, where it is proved that
|
| 1995 |
$\hat{q} \geq q$. It is possible to use identical algebraic technique
|
| 1996 |
as is used in Lemma \ref{lem:ccil0:sidv0:sgdu0:01} in order to prove that
|
| 1997 |
|
| 1998 |
\begin{equation}
|
| 1999 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:05}
|
| 2000 |
\left\lfloor {\frac{u_n b^2 + u_{n-1} b + u_{n-2}}{v_{n-1} b + v_{n-2}}} \right\rfloor
|
| 2001 |
\geq q,
|
| 2002 |
\end{equation}
|
| 2003 |
|
| 2004 |
and it follows that
|
| 2005 |
|
| 2006 |
\begin{equation}
|
| 2007 |
\label{eq:lem:ccil0:sidv0:sgdu0:04:06}
|
| 2008 |
\hat{q}
|
| 2009 |
>
|
| 2010 |
\frac{u_n b^2 + u_{n-1} b + u_{n-2}}{v_{n-1} b + v_{n-2}}
|
| 2011 |
\geq
|
| 2012 |
\left\lfloor {\frac{u_n b^2 + u_{n-1} b + u_{n-2}}{v_{n-1} b + v_{n-2}}} \right\rfloor
|
| 2013 |
\geq q,
|
| 2014 |
\end{equation}
|
| 2015 |
|
| 2016 |
and thus $\hat{q} > q$.
|
| 2017 |
\end{vworklemmaproof}
|
| 2018 |
\vworklemmafooter{}
|
| 2019 |
|
| 2020 |
\begin{vworklemmastatementpar}
|
| 2021 |
{Add-back occurs with approximate probability \mbox{\boldmath$2/b$}}
|
| 2022 |
\label{lem:ccil0:sidv0:sgdu0:05}
|
| 2023 |
The estimate of $q$ provided by (\ref{eq:ccil0:sidv0:sgdu0:01}),
|
| 2024 |
\end{vworklemmastatementpar}
|
| 2025 |
\begin{vworklemmaproof}
|
| 2026 |
\end{vworklemmaproof}
|
| 2027 |
\vworklemmafooter{}
|
| 2028 |
|
| 2029 |
|
| 2030 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2031 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2032 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2033 |
\subsection{Division Of Signed Operands}
|
| 2034 |
|
| 2035 |
|
| 2036 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2037 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2038 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2039 |
\subsection{Large Dividends With Machine-Native Divisors}
|
| 2040 |
\label{ccil0:sidv0:sldm0}
|
| 2041 |
|
| 2042 |
Division of arbitrary-sized operands (Section \ref{ccil0:sidv0:sgdu0}) is
|
| 2043 |
a costly operation. In many practical applications, we are able to exploit
|
| 2044 |
data sizes of operands or special relationships between the values of
|
| 2045 |
operands to use the instruction set of the machine more effectively.
|
| 2046 |
In this subsection, we investigate what optimizations we may achieve when:
|
| 2047 |
|
| 2048 |
\begin{itemize}
|
| 2049 |
\item We wish to calculate the quotient and remainder of
|
| 2050 |
unsigned integers $p$ and $q$: $p/q$ and
|
| 2051 |
$p \bmod{} q$; \emph{and}
|
| 2052 |
\item The machine possesses unsigned division instructions
|
| 2053 |
which provide both a quotient and a remainder from
|
| 2054 |
a division; \emph{and}
|
| 2055 |
\item The bitsize of the divisor $q$ is not larger than can
|
| 2056 |
be accomodated (as a divisor) by machine division instructions.
|
| 2057 |
\end{itemize}
|
| 2058 |
|
| 2059 |
Processors which possess integer division instructions usually
|
| 2060 |
possess one of two types of instructions:
|
| 2061 |
|
| 2062 |
\begin{itemize}
|
| 2063 |
\item Instructions where the the divisor, quotient and remainder are
|
| 2064 |
$Q$ bits, but the dividend is $2Q$ bits (we call these
|
| 2065 |
``large dividend'' instructions). For example, an
|
| 2066 |
instruction which accepts a 16-bit dividend and an
|
| 2067 |
8-bit divisor to produce an 8-bit quotient and an 8-bit remainder is
|
| 2068 |
typical.
|
| 2069 |
With such instructions, overflow is possible, and is always detectable.
|
| 2070 |
However, in this subsection we never describe algorithms which detect
|
| 2071 |
overflow---instead, we arrange for data values which cannot generate an
|
| 2072 |
overflow.
|
| 2073 |
\item Instructions where the dividend, divisor, quotient, and remainder
|
| 2074 |
are all $Q$ bits (we call these ``small dividend'' instructions).
|
| 2075 |
With such instructions, overflow is not possible.
|
| 2076 |
\end{itemize}
|
| 2077 |
|
| 2078 |
We call the bitsize $Q$ a \emph{chunk}. We use \emph{chunk} rather than
|
| 2079 |
\emph{word} because the chunksize and wordsize in general are not
|
| 2080 |
required to be the same.
|
| 2081 |
|
| 2082 |
For the remainder of this discussion, we assume large dividend
|
| 2083 |
instructions (the first category above).
|
| 2084 |
The algorithms developed can be implemented on small dividend machines
|
| 2085 |
by halving data sizes so that the divisor fills no more than half
|
| 2086 |
of the available bits.
|
| 2087 |
|
| 2088 |
We assume that we are interested in calculating the integer quotient
|
| 2089 |
$\lfloor{}p/q\rfloor$ and remainder $p \bmod{} q$ of two unsigned
|
| 2090 |
integers $p$ and $q$, where $p$ is of size $P$ bits and $q$ is
|
| 2091 |
of size $Q$ bits. For simplicity and without detracting from the
|
| 2092 |
generality of the solution, we assume that $Q \vworkdivides{} P$.
|
| 2093 |
|
| 2094 |
We then seek to calculate
|
| 2095 |
|
| 2096 |
\begin{eqnarray}
|
| 2097 |
\label{eq:ccil0:sidv0:sldm0:001}
|
| 2098 |
\frac{p}{q} & = & \frac{2^{P-Q} p_{[P/Q-1]} + 2^{P-2Q} p_{[P/Q-2]} + \ldots{} + 2^{Q} p_{[1]} + p_{[0]}}{q_{[0]}} \\
|
| 2099 |
\nonumber & = & \frac{\sum_{i=0}^{P/Q-1} 2^{iQ} p_{[i]}}{q_{[0]}} .
|
| 2100 |
\end{eqnarray}
|
| 2101 |
|
| 2102 |
\noindent{}Using the integer identity
|
| 2103 |
|
| 2104 |
\begin{equation}
|
| 2105 |
\label{eq:ccil0:sidv0:sldm0:002}
|
| 2106 |
\frac{a}{b} = \left\lfloor{\frac{a}{b}}\right\rfloor + \frac{a \bmod b}{b} ,
|
| 2107 |
\end{equation}
|
| 2108 |
|
| 2109 |
\noindent{}we can reform (\ref{eq:ccil0:sidv0:sldm0:001}) into
|
| 2110 |
|
| 2111 |
\begin{eqnarray}
|
| 2112 |
\nonumber
|
| 2113 |
\frac{p}{q} & = & 2^{P-Q} \left\lfloor{\frac{p_{[P/Q-1]}}{q_{[0]}}}\right\rfloor \\
|
| 2114 |
\label{eq:ccil0:sidv0:sldm0:003}
|
| 2115 |
& + & 2^{P-Q} \frac{p_{[P/Q-1]}\bmod q_{[0]}}{q_{[0]}}
|
| 2116 |
+ 2^{P-2Q} \frac{p_{[P/Q-2]}}{q_{[0]}} \\
|
| 2117 |
\nonumber & + & \frac{\sum_{i=0}^{P/Q-3} 2^{iQ} p_{[i]}}{q_{[0]}} ,
|
| 2118 |
\end{eqnarray}
|
| 2119 |
|
| 2120 |
\noindent{}which can be polished slightly to yield
|
| 2121 |
|
| 2122 |
\begin{eqnarray}
|
| 2123 |
\nonumber
|
| 2124 |
\frac{p}{q} & = & 2^{P-Q} \left\lfloor{\frac{p_{[P/Q-1]}}{q_{[0]}}}\right\rfloor \\
|
| 2125 |
\label{eq:ccil0:sidv0:sldm0:004}
|
| 2126 |
& + & 2^{P-2Q} \frac{2^Q (p_{[P/Q-1]}\bmod q_{[0]}) + p_{[P/Q-2]}}{q_{[0]}} \\
|
| 2127 |
\nonumber & + & \frac{\sum_{i=0}^{P/Q-3} 2^{iQ} p_{[i]}}{q_{[0]}} .
|
| 2128 |
\end{eqnarray}
|
| 2129 |
|
| 2130 |
Note in (\ref{eq:ccil0:sidv0:sldm0:004}) that the first term,
|
| 2131 |
$\lfloor{}p_{[P/Q-1]} / q_{[0]}\rfloor$, as well as
|
| 2132 |
a portion of the second term, $p_{[P/Q-1]}\bmod q_{[0]}$, can be
|
| 2133 |
calculated using a single machine division instruction with
|
| 2134 |
$p_{[P/Q-1]}$ as the dividend and $q_{[0]}$ as the divisor.
|
| 2135 |
Note also that multiplication of an integer by a power of 2
|
| 2136 |
can be achieved by placing the integer correctly within the
|
| 2137 |
result. In this regard note that $Q=8$ or $Q=16$ are
|
| 2138 |
the most typical cases, and so the placement can be achieved simply
|
| 2139 |
by selecting the correct memory address.
|
| 2140 |
|
| 2141 |
It is initially unclear whether we can evaluate or reduce the fraction in the
|
| 2142 |
second term of (\ref{eq:ccil0:sidv0:sldm0:004}),
|
| 2143 |
$[2^Q (p_{[P/Q-1]}\bmod q_{[0]}) + p_{[P/Q-2]}] / q_{[0]}$,
|
| 2144 |
using a single large dividend machine instruction, because
|
| 2145 |
the upper chunk of the dividend is populated with non-zero bits
|
| 2146 |
(specifically, $p_{[P/Q-1]}\bmod q_{[0]}$), and it seems that
|
| 2147 |
a division overflow may be possible. However, with some thought,
|
| 2148 |
it is clear that $p_{[P/Q-1]}\bmod q_{[0]} \leq q_{[0]} - 1$ and
|
| 2149 |
$p_{[P/Q-2]} \leq 2^Q - 1$, thus the largest numerator possible
|
| 2150 |
is $2^Q q_{[0]} - 1$, which, when divided by $q_{[0]}$, will result
|
| 2151 |
in a quotient and remainder of $2^Q - 1$. Thus, no division overflow
|
| 2152 |
can occur, and the fraction in the
|
| 2153 |
second term of (\ref{eq:ccil0:sidv0:sldm0:004}) can be evaluated
|
| 2154 |
using a large divisor integer machine instruction.
|
| 2155 |
|
| 2156 |
The fraction in the
|
| 2157 |
second term of (\ref{eq:ccil0:sidv0:sldm0:004}) can be simplified
|
| 2158 |
using (\ref{eq:ccil0:sidv0:sldm0:002}) to yield:
|
| 2159 |
|
| 2160 |
\begin{eqnarray}
|
| 2161 |
\nonumber
|
| 2162 |
\frac{p}{q} & = & 2^{P-Q} \left\lfloor{\frac{p_{[P/Q-1]}}{q_{[0]}}}\right\rfloor \\
|
| 2163 |
\label{eq:ccil0:sidv0:sldm0:005}
|
| 2164 |
& + & 2^{P-2Q} \left\lfloor{\frac{2^Q (p_{[P/Q-1]}\bmod q_{[0]}) + p_{[P/Q-2]}}{q_{[0]}}}\right\rfloor \\
|
| 2165 |
\nonumber & + & 2^{P-2Q} \frac{(2^Q (p_{[P/Q-1]}\bmod q_{[0]}) + p_{[P/Q-2]}) \bmod q_{[0]}}{q_{[0]}} \\
|
| 2166 |
\nonumber & + & \frac{\sum_{i=0}^{P/Q-3} 2^{iQ} p_{[i]}}{q_{[0]}} .
|
| 2167 |
\end{eqnarray}
|
| 2168 |
|
| 2169 |
The process of combining adjacent terms can be continued until all
|
| 2170 |
divisions and modulo operations necessary can be carried out using
|
| 2171 |
long dividend division instructions. If we envision a
|
| 2172 |
long-dividend division instruction as a functional block that
|
| 2173 |
accepts a $2Q$-bit dividend and a $Q$-bit divisor to produce a
|
| 2174 |
$Q$-bit quotient and a $Q$-bit remainder
|
| 2175 |
(Figure \ref{fig:ccil0:sidv0:sldm0:00}), then we can draw the
|
| 2176 |
entire division as outlined by (\ref{eq:ccil0:sidv0:sldm0:005})
|
| 2177 |
as shown in Figure \ref{fig:ccil0:sidv0:sldm0:01}.
|
| 2178 |
|
| 2179 |
\begin{figure}
|
| 2180 |
\centering
|
| 2181 |
\includegraphics[width=4.6in]{c_cil0/lddvblk.eps}
|
| 2182 |
\caption{Long Dividend Division Machine Instruction As A Functional Block}
|
| 2183 |
\label{fig:ccil0:sidv0:sldm0:00}
|
| 2184 |
\end{figure}
|
| 2185 |
|
| 2186 |
\begin{figure}
|
| 2187 |
\centering
|
| 2188 |
\includegraphics[width=4.6in]{c_cil0/ldmnblk.eps}
|
| 2189 |
\caption{Long Dividend/Machine-Native Divisor Division In Functional Block Form}
|
| 2190 |
\label{fig:ccil0:sidv0:sldm0:01}
|
| 2191 |
\end{figure}
|
| 2192 |
|
| 2193 |
The following example illustrates how to apply the technique.
|
| 2194 |
|
| 2195 |
\begin{vworkexamplestatement}
|
| 2196 |
\label{ex:ccil0:sidv0:sldm0:01}
|
| 2197 |
Implement 32/8 unsigned division on the TMS370C8 processor, which is
|
| 2198 |
characterized by a 16/8 division instruction.
|
| 2199 |
\end{vworkexamplestatement}
|
| 2200 |
\begin{vworkexampleparsection}{Solution}
|
| 2201 |
It would be possible to prepare an implementation directly from
|
| 2202 |
Figure \ref{fig:ccil0:sidv0:sldm0:01}: however, it may be
|
| 2203 |
more instructive to work through a solution without the
|
| 2204 |
aid of this figure.
|
| 2205 |
|
| 2206 |
In the case of the TMS370C8, the chunk size $Q$ is 8 bits; therefore
|
| 2207 |
$Q=8$. The problem statement indicates that we must accept 32-bit dividends;
|
| 2208 |
therefore $P=32$. Thus
|
| 2209 |
|
| 2210 |
\begin{equation}
|
| 2211 |
\label{eq:ex:ccil0:sidv0:sldm0:01:001}
|
| 2212 |
p = 2^{24} p_{[3]} + 2^{16} p_{[2]} + 2^{8} p_{[1]} + p_{[0]}
|
| 2213 |
\end{equation}
|
| 2214 |
|
| 2215 |
\noindent{}and
|
| 2216 |
|
| 2217 |
\begin{equation}
|
| 2218 |
\label{eq:ex:ccil0:sidv0:sldm0:01:002}
|
| 2219 |
q = q_{[0]} .
|
| 2220 |
\end{equation}
|
| 2221 |
|
| 2222 |
\noindent{}Thus the quotient and remainder we would like to determine,
|
| 2223 |
$\lfloor p/q \rfloor$ and $p \bmod q$, can be obtained by repeated
|
| 2224 |
application of (\ref{eq:ccil0:sidv0:sldm0:002}) as shown
|
| 2225 |
in Equations (\ref{eq:ex:ccil0:sidv0:sldm0:01:003})
|
| 2226 |
through (\ref{eq:ex:ccil0:sidv0:sldm0:01:011}).
|
| 2227 |
|
| 2228 |
\begin{equation}
|
| 2229 |
\label{eq:ex:ccil0:sidv0:sldm0:01:003}
|
| 2230 |
\frac{p}{q}
|
| 2231 |
=
|
| 2232 |
\frac{2^{24} p_{[3]} + 2^{16} p_{[2]} + 2^{8} p_{[1]} + p_{[0]}}{q_{[0]}}
|
| 2233 |
\end{equation}
|
| 2234 |
|
| 2235 |
\begin{equation}
|
| 2236 |
\label{eq:ex:ccil0:sidv0:sldm0:01:004}
|
| 2237 |
\frac{p}{q}
|
| 2238 |
=
|
| 2239 |
2^{24} \frac{p_{[3]}}{q_{[0]}}
|
| 2240 |
+
|
| 2241 |
2^{16} \frac{p_{[2]}}{q_{[0]}}
|
| 2242 |
+
|
| 2243 |
2^{8} \frac{p_{[1]}}{q_{[0]}}
|
| 2244 |
+
|
| 2245 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2246 |
\end{equation}
|
| 2247 |
|
| 2248 |
\begin{equation}
|
| 2249 |
\label{eq:ex:ccil0:sidv0:sldm0:01:005}
|
| 2250 |
\frac{p}{q}
|
| 2251 |
=
|
| 2252 |
2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2253 |
+
|
| 2254 |
2^{24} \frac{(p_{[3]} \bmod q_{[0]})}{q_{[0]}}
|
| 2255 |
+
|
| 2256 |
2^{16} \frac{p_{[2]}}{q_{[0]}}
|
| 2257 |
+
|
| 2258 |
2^{8} \frac{p_{[1]}}{q_{[0]}}
|
| 2259 |
+
|
| 2260 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2261 |
\end{equation}
|
| 2262 |
|
| 2263 |
\begin{equation}
|
| 2264 |
\label{eq:ex:ccil0:sidv0:sldm0:01:006}
|
| 2265 |
\frac{p}{q}
|
| 2266 |
=
|
| 2267 |
2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2268 |
+
|
| 2269 |
2^{16} \frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}
|
| 2270 |
+
|
| 2271 |
2^{8} \frac{p_{[1]}}{q_{[0]}}
|
| 2272 |
+
|
| 2273 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2274 |
\end{equation}
|
| 2275 |
|
| 2276 |
\begin{eqnarray}
|
| 2277 |
\label{eq:ex:ccil0:sidv0:sldm0:01:007}
|
| 2278 |
\frac{p}{q} & = & 2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2279 |
+
|
| 2280 |
2^{16} \left\lfloor{\frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}}\right\rfloor \\
|
| 2281 |
\nonumber & + &
|
| 2282 |
2^{16} \frac{(2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}}{q_{[0]}}
|
| 2283 |
+
|
| 2284 |
2^{8} \frac{p_{[1]}}{q_{[0]}}
|
| 2285 |
+
|
| 2286 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2287 |
\end{eqnarray}
|
| 2288 |
|
| 2289 |
\begin{eqnarray}
|
| 2290 |
\label{eq:ex:ccil0:sidv0:sldm0:01:008}
|
| 2291 |
\frac{p}{q} & = & 2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2292 |
+
|
| 2293 |
2^{16} \left\lfloor{\frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}}\right\rfloor \\
|
| 2294 |
\nonumber & + &
|
| 2295 |
2^{8} \frac{2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}}{q_{[0]}}
|
| 2296 |
+
|
| 2297 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2298 |
\end{eqnarray}
|
| 2299 |
|
| 2300 |
\begin{eqnarray}
|
| 2301 |
\nonumber\frac{p}{q} & = & 2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2302 |
+
|
| 2303 |
2^{16} \left\lfloor{\frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}}\right\rfloor \\
|
| 2304 |
\label{eq:ex:ccil0:sidv0:sldm0:01:009}
|
| 2305 |
& + &
|
| 2306 |
2^{8} \left\lfloor{\frac{2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}}{q_{[0]}}}\right\rfloor \\
|
| 2307 |
\nonumber & + &
|
| 2308 |
2^{8} \frac{(2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}) \bmod q_{[0]}}{q_{[0]}} \\
|
| 2309 |
\nonumber & + &
|
| 2310 |
\frac{p_{[0]}}{q_{[0]}}
|
| 2311 |
\end{eqnarray}
|
| 2312 |
|
| 2313 |
\begin{eqnarray}
|
| 2314 |
\nonumber\frac{p}{q} & = & 2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2315 |
+
|
| 2316 |
2^{16} \left\lfloor{\frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}}\right\rfloor \\
|
| 2317 |
\label{eq:ex:ccil0:sidv0:sldm0:01:010}
|
| 2318 |
& + &
|
| 2319 |
2^{8} \left\lfloor{\frac{2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}}{q_{[0]}}}\right\rfloor \\
|
| 2320 |
\nonumber & + &
|
| 2321 |
\frac{2^8((2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}) \bmod q_{[0]}) + p_{[0]}}{q_{[0]}}
|
| 2322 |
\end{eqnarray}
|
| 2323 |
|
| 2324 |
\begin{eqnarray}
|
| 2325 |
\nonumber & \displaystyle \frac{p}{q} = 2^{24} \left\lfloor{\frac{p_{[3]}}{q_{[0]}}}\right\rfloor
|
| 2326 |
+
|
| 2327 |
2^{16} \left\lfloor{\frac{2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}}{q_{[0]}}}\right\rfloor & \\
|
| 2328 |
\label{eq:ex:ccil0:sidv0:sldm0:01:011}
|
| 2329 |
& \displaystyle +
|
| 2330 |
2^{8} \left\lfloor{\frac{2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}}{q_{[0]}}}\right\rfloor & \\
|
| 2331 |
\nonumber & \displaystyle +
|
| 2332 |
\left\lfloor{\frac{2^8((2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}) \bmod q_{[0]}) + p_{[0]}}{q_{[0]}}}\right\rfloor + & \\
|
| 2333 |
\nonumber
|
| 2334 |
& \displaystyle \frac{(2^8((2^8((2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}) \bmod q_{[0]}) + p_{[1]}) \bmod q_{[0]}) + p_{[0]}) \bmod q_{[0]}}{q_{[0]}}
|
| 2335 |
&
|
| 2336 |
\end{eqnarray}
|
| 2337 |
|
| 2338 |
Note several things about the implementation suggested by
|
| 2339 |
(\ref{eq:ex:ccil0:sidv0:sldm0:01:011}):
|
| 2340 |
|
| 2341 |
\begin{itemize}
|
| 2342 |
\item No addition or multiplication is required to calculate terms such as
|
| 2343 |
$2^8 (p_{[3]} \bmod q_{[0]}) + p_{[2]}$. The high-order byte of the
|
| 2344 |
large dividend can be stuffed with $p_{[3]} \bmod q_{[0]}$ and
|
| 2345 |
the low-order byte with $p_{[2]}$.
|
| 2346 |
\item No addition or multiplication is required to calculate the
|
| 2347 |
result $\lfloor p/q \rfloor$.
|
| 2348 |
Note in (\ref{eq:ex:ccil0:sidv0:sldm0:01:011}) that the results are
|
| 2349 |
conveniently grouped as bytes with multipliers of $2^{24}$,
|
| 2350 |
$2^{16}$, $2^8$, and $2^0=1$. The terms can simply be placed into
|
| 2351 |
the appropriate byte, as a way of multplication by the appropriate
|
| 2352 |
power of 2. Note also that each term is guaranteed to be
|
| 2353 |
$\in \{0, 1, 2, \ldots{} , 255\}$, by the argument presented
|
| 2354 |
earlier for (\ref{eq:ccil0:sidv0:sldm0:004}). Thus, the
|
| 2355 |
addition will result in no carries, and each result byte can simply
|
| 2356 |
be placed directly in the correct memory location---addition is
|
| 2357 |
not necessary.
|
| 2358 |
\item Four machine division instructions are required, and the remainder
|
| 2359 |
is produced automatically by the fourth instruction.
|
| 2360 |
\end{itemize}
|
| 2361 |
|
| 2362 |
An implemenation for the TMS370C8 is supplied as Figure
|
| 2363 |
\ref{fig:ex:ccil0:sidv0:sldm0:01:01}. A block diagram of the data
|
| 2364 |
flow for this implementation is supplied as
|
| 2365 |
Figure \ref{fig:ex:ccil0:sidv0:sldm0:01:02}.
|
| 2366 |
\end{vworkexampleparsection}
|
| 2367 |
\vworkexamplefooter{}
|
| 2368 |
|
| 2369 |
\begin{figure}
|
| 2370 |
\begin{verbatim}
|
| 2371 |
;Assume that byte memory locations p3, p2, p1, and p0 contain the
|
| 2372 |
;32-bit unsigned dividend, and byte q0 contains the 8-bit unsigned
|
| 2373 |
;divisor. Assume also that the result quotient will be placed
|
| 2374 |
;in byte memory locations d3, d2, d1, and d0; and that the
|
| 2375 |
;remainder will be placed in the byte memory location r0. Further
|
| 2376 |
;assume that all memory locations are in the register file (near).
|
| 2377 |
CLR A ;High-order chunk of large divisor
|
| 2378 |
;must be 0.
|
| 2379 |
MOV p3, B ;Load the low-order chunk of divisor.
|
| 2380 |
DIV q0, A ;Perform the first division.
|
| 2381 |
MOV A, d3 ;Quotient becomes this part of the
|
| 2382 |
;result.
|
| 2383 |
MOV B, A ;Remainder becomes high-order chunk of
|
| 2384 |
;next division.
|
| 2385 |
MOV p2, B ;Next byte becomes low-order chunk.
|
| 2386 |
DIV q0, A ;Do the second division.
|
| 2387 |
MOV A, d2 ;Quotient becomes this part of the
|
| 2388 |
;result.
|
| 2389 |
MOV B, A ;Remainder becomes high-order chunk of
|
| 2390 |
;next division.
|
| 2391 |
MOV p1, B ;Next byte becomes low-order chunk.
|
| 2392 |
DIV q0, A ;Do the third division.
|
| 2393 |
MOV A, d1 ;Quotient becomes this part of the
|
| 2394 |
;result.
|
| 2395 |
MOV B, A ;Remainder becomes high-order chunk of
|
| 2396 |
;next division.
|
| 2397 |
MOV p0, B ;Next byte becomes low-order chunk.
|
| 2398 |
DIV q0, A ;Do the fourth division.
|
| 2399 |
MOV A, d0 ;Quotient becomes this part of the
|
| 2400 |
;result.
|
| 2401 |
MOV B, r0 ;This is the remainder, which could be used
|
| 2402 |
;for rounding.
|
| 2403 |
\end{verbatim}
|
| 2404 |
\caption{TMS370C8 Code Snippet Illustrating Unsigned 32/8
|
| 2405 |
Division Using Unsigned 16/8
|
| 2406 |
Machine Instructions (Example \ref{ex:ccil0:sidv0:sldm0:01})}
|
| 2407 |
\label{fig:ex:ccil0:sidv0:sldm0:01:01}
|
| 2408 |
\end{figure}
|
| 2409 |
|
| 2410 |
\begin{figure}
|
| 2411 |
\centering
|
| 2412 |
\includegraphics[width=4.6in]{c_cil0/t370dmp.eps}
|
| 2413 |
\caption{Block Diagram Of Data Flow Of Figure \ref{fig:ex:ccil0:sidv0:sldm0:01:01}}
|
| 2414 |
\label{fig:ex:ccil0:sidv0:sldm0:01:02}
|
| 2415 |
\end{figure}
|
| 2416 |
|
| 2417 |
|
| 2418 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2419 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2420 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2421 |
\section{Miscellaneous Integer Mappings}
|
| 2422 |
%Section tag: MIM0
|
| 2423 |
\label{ccil0:smim0}
|
| 2424 |
|
| 2425 |
Embedded system work and ROM constraints often inspire a great deal
|
| 2426 |
of cleverness in the selection of instructions to perform mappings or
|
| 2427 |
tests. In this section, we discuss integer mappings (i.e. functions)
|
| 2428 |
for which economical implementations are known; and in the next section
|
| 2429 |
(Section \ref{ccil0:smit0})
|
| 2430 |
we discuss integer tests for which economical implementations are known.
|
| 2431 |
|
| 2432 |
To the best of our knowledge, there is no way to derive these mappings
|
| 2433 |
and tests---they have been collected from many software developers and
|
| 2434 |
come from human intuition and experience.
|
| 2435 |
|
| 2436 |
|
| 2437 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2438 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2439 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2440 |
\subsection{Lowest-Order Bit}
|
| 2441 |
%Subsection tag: LIB0
|
| 2442 |
\label{ccil0:smim0:slib0}
|
| 2443 |
|
| 2444 |
\index{lowest-order bit}
|
| 2445 |
\index{least significant bit}
|
| 2446 |
|
| 2447 |
The mapping
|
| 2448 |
|
| 2449 |
\texttt{mask = x \& -x}
|
| 2450 |
|
| 2451 |
\noindent{}is the most economical way known to extract the
|
| 2452 |
lowest-order bit set in an integer \texttt{x}, or
|
| 2453 |
0 if no bits are set.\footnote{This mapping was contributed by
|
| 2454 |
David Baker (\texttt{bakerda@engin.umich.edu})
|
| 2455 |
and Raul Selgado (\texttt{rselgado@visteon.com}).} Since most processors have an instruction to form the
|
| 2456 |
two's complement of an integer, this mapping usually requires only
|
| 2457 |
two arithmetic instructions.
|
| 2458 |
|
| 2459 |
When implementing this mapping in assembly-language on processors without a
|
| 2460 |
two's complement instruction, two other possible implementations are:
|
| 2461 |
|
| 2462 |
\begin{itemize}
|
| 2463 |
\item \texttt{mask = x \& ($\sim$x + 1)}
|
| 2464 |
\item \texttt{mask = x \& ((x \^{ } -1) + 1)}
|
| 2465 |
\end{itemize}
|
| 2466 |
|
| 2467 |
|
| 2468 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2469 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2470 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2471 |
\section{Miscellaneous Integer Tests}
|
| 2472 |
%Section tag: MIT0
|
| 2473 |
\label{ccil0:smit0}
|
| 2474 |
|
| 2475 |
\subsection{Power Of 2}
|
| 2476 |
%Subsection tag: PTW0
|
| 2477 |
\label{ccil0:smit0:sptw0}
|
| 2478 |
|
| 2479 |
\index{power of two}
|
| 2480 |
\index{2N@$2^N$}
|
| 2481 |
|
| 2482 |
The test
|
| 2483 |
|
| 2484 |
\texttt{(x \& (x-1) == 0) \&\& (x != 0)}
|
| 2485 |
|
| 2486 |
\noindent{}is the most economical way known to
|
| 2487 |
test whether an integer is a positive power of two
|
| 2488 |
(1, 2, 4, 8, 16, etc.).\footnote{The test appeared as part of
|
| 2489 |
a discussion on
|
| 2490 |
the GMP mailing list in 2002.}
|
| 2491 |
|
| 2492 |
|
| 2493 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2494 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2495 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2496 |
\section{Exercises}
|
| 2497 |
|
| 2498 |
\begin{vworkexercisestatement}
|
| 2499 |
\label{exe:ccil0:sexe0:01}
|
| 2500 |
Show that any $m$-bit two's complement integer $u_{[m-1:0]}$ except
|
| 2501 |
$-2^{m-1}$ can be negated by forming the one's complement, then adding one.
|
| 2502 |
\end{vworkexercisestatement}
|
| 2503 |
|
| 2504 |
|
| 2505 |
|
| 2506 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2507 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2508 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2509 |
\vfill
|
| 2510 |
\noindent\begin{figure}[!b]
|
| 2511 |
\noindent\rule[-0.25in]{\textwidth}{1pt}
|
| 2512 |
\begin{tiny}
|
| 2513 |
\begin{verbatim}
|
| 2514 |
$RCSfile: c_cil0.tex,v $
|
| 2515 |
$Source: /home/dashley/cvsrep/e3ft_gpl01/e3ft_gpl01/dtaipubs/esrgubka/c_cil0/c_cil0.tex,v $
|
| 2516 |
$Revision: 1.24 $
|
| 2517 |
$Author: dtashley $
|
| 2518 |
$Date: 2003/11/03 02:14:24 $
|
| 2519 |
\end{verbatim}
|
| 2520 |
\end{tiny}
|
| 2521 |
\noindent\rule[0.25in]{\textwidth}{1pt}
|
| 2522 |
\end{figure}
|
| 2523 |
|
| 2524 |
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 2525 |
% $Log: c_cil0.tex,v $
|
| 2526 |
% Revision 1.24 2003/11/03 02:14:24 dtashley
|
| 2527 |
% All duplicate labels as flagged by LaTeX removed. Additional files added
|
| 2528 |
% to Microsoft Visual Studio edit context.
|
| 2529 |
%
|
| 2530 |
% Revision 1.23 2002/08/26 17:57:03 dtashley
|
| 2531 |
% Additional solutions chapter added. Precautionary checkin to be sure
|
| 2532 |
% that I've captured all changes.
|
| 2533 |
%
|
| 2534 |
% Revision 1.22 2002/08/25 13:18:21 dtashley
|
| 2535 |
% Edits.
|
| 2536 |
%
|
| 2537 |
% Revision 1.21 2002/08/22 00:33:33 dtashley
|
| 2538 |
% Have made aesthetic changes in CFRY0 and CCFR0. Checking in all before
|
| 2539 |
% rebuild of book.
|
| 2540 |
%
|
| 2541 |
% Revision 1.20 2002/08/21 09:12:11 dtashley
|
| 2542 |
% Safety checkin.
|
| 2543 |
%
|
| 2544 |
% Revision 1.19 2002/08/19 05:06:45 dtashley
|
| 2545 |
% Substantial progress in integer numerics chapter. Preparing to
|
| 2546 |
% work at home.
|
| 2547 |
%
|
| 2548 |
% Revision 1.18 2002/08/10 07:34:48 dtashley
|
| 2549 |
% Checkin before resuming work on a lemma at home.
|
| 2550 |
%
|
| 2551 |
% Revision 1.17 2002/08/09 03:13:42 dtashley
|
| 2552 |
% Significant lemma proved, and other progress.
|
| 2553 |
%
|
| 2554 |
% Revision 1.16 2002/08/06 22:15:24 dtashley
|
| 2555 |
% Substantial lemma proof progress.
|
| 2556 |
%
|
| 2557 |
% Revision 1.15 2002/08/05 01:28:33 dtashley
|
| 2558 |
% Lemma demonstrating that 0 \leq \hat{q}-q \leq 2 completed.
|
| 2559 |
%
|
| 2560 |
% Revision 1.14 2002/08/03 23:04:57 dtashley
|
| 2561 |
% Safety checkin. Having difficulty: may have solved the wrong
|
| 2562 |
% problem.
|
| 2563 |
%
|
| 2564 |
% Revision 1.13 2002/08/01 01:31:24 dtashley
|
| 2565 |
% Safety checkin. Having difficulty completing an alternate version of
|
| 2566 |
% Knuth's proof about the accuracy of quotient estimates based on first
|
| 2567 |
% digits of dividend and divisor.
|
| 2568 |
%
|
| 2569 |
% Revision 1.12 2002/07/31 04:38:31 dtashley
|
| 2570 |
% Edits to basic integer algorithms chapter, safety checkin.
|
| 2571 |
%
|
| 2572 |
% Revision 1.11 2002/07/29 16:30:08 dtashley
|
| 2573 |
% Safety checkin before moving work back to WSU server Kalman.
|
| 2574 |
%
|
| 2575 |
% Revision 1.10 2002/07/26 20:39:43 dtashley
|
| 2576 |
% Safety checkin.
|
| 2577 |
%
|
| 2578 |
% Revision 1.9 2002/07/26 14:58:01 dtashley
|
| 2579 |
% Safety checkin.
|
| 2580 |
%
|
| 2581 |
% Revision 1.8 2002/07/21 16:19:28 dtashley
|
| 2582 |
% Finalization of material about integer division when dividend is
|
| 2583 |
% long but divisor is same as data size that machine can use as
|
| 2584 |
% divisor natively.
|
| 2585 |
%
|
| 2586 |
% Revision 1.7 2002/07/20 23:01:45 dtashley
|
| 2587 |
% Adding material about division with large dividend and machine-native
|
| 2588 |
% divisor.
|
| 2589 |
%
|
| 2590 |
% Revision 1.6 2002/06/11 04:34:19 dtashley
|
| 2591 |
% Information for David Baker added.
|
| 2592 |
%
|
| 2593 |
% Revision 1.5 2002/06/08 05:50:25 dtashley
|
| 2594 |
% Added missing tilde. Can't get it to be same size as other
|
| 2595 |
% characters--need to research that.
|
| 2596 |
%
|
| 2597 |
% Revision 1.4 2002/06/07 02:08:32 dtashley
|
| 2598 |
% Section added for integer mappings and tests. Mapping for lowest-order
|
| 2599 |
% bit set from Raul Selgado and Dave (last name presently unknown)
|
| 2600 |
% at Visteon added. Test for power of 2 added.
|
| 2601 |
%
|
| 2602 |
% Revision 1.3 2001/08/31 23:11:17 dtashley
|
| 2603 |
% End of August 2001 safety check-in.
|
| 2604 |
%
|
| 2605 |
% Revision 1.2 2001/08/27 20:06:08 dtashley
|
| 2606 |
% Edits and substantial re-organization.
|
| 2607 |
%
|
| 2608 |
% Revision 1.1 2001/08/25 22:51:25 dtashley
|
| 2609 |
% Complex re-organization of book.
|
| 2610 |
%
|
| 2611 |
%End of file C_CIL0.TEX
|
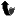 Parent Directory
|
Parent Directory
|  Revision Log
Revision Log