| 1 |
dashley |
140 |
%$Header$ |
| 2 |
|
|
|
| 3 |
|
|
\chapter[\cedczeroshorttitle{}]{\cedczerolongtitle{}} |
| 4 |
|
|
|
| 5 |
|
|
\label{cedc0} |
| 6 |
|
|
|
| 7 |
|
|
\beginchapterquote{``True genius resides in the capacity for evaluation of uncertain, |
| 8 |
|
|
hazardous, and conflicting information.''} |
| 9 |
|
|
{Winston Churchill} |
| 10 |
|
|
\index{Churchill, Winston} |
| 11 |
|
|
|
| 12 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 13 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 14 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 15 |
|
|
\section{Introduction} |
| 16 |
|
|
%Section tag: INT0 |
| 17 |
|
|
\label{cedc0:sint0} |
| 18 |
|
|
|
| 19 |
|
|
In microcontroller work, it is frequently necessary to consider how |
| 20 |
|
|
best to add redundancy to data. The following design scenarios are |
| 21 |
|
|
common. |
| 22 |
|
|
|
| 23 |
|
|
\begin{enumerate} |
| 24 |
|
|
\item Immediately on powerup, a microcontroller product calculates |
| 25 |
|
|
the checksum of its program memory (usually ROM or FLASH) and compares this |
| 26 |
|
|
checksum to a stored value in order to detect possible corruption of program |
| 27 |
|
|
memory. What is the best way to calculate a checksum for this |
| 28 |
|
|
purpose? |
| 29 |
|
|
\item A storage medium that will tolerate a limited number of write cycles |
| 30 |
|
|
(such as EEPROM), will used to used to store data which will change |
| 31 |
|
|
and need to rewritten more times than the life of the medium will |
| 32 |
|
|
accomodate. As a result, a strategy which wears out a portion of the medium |
| 33 |
|
|
and then uses another portion is employed. When a portion of the medium |
| 34 |
|
|
wears out (as evidenced by corruption of bits), how can the data be |
| 35 |
|
|
reliably recovered before |
| 36 |
|
|
being transferred to the next portion? |
| 37 |
|
|
\item A microcontroller product stores data in battery-backed RAM while powered |
| 38 |
|
|
down. What type of checksum should be added to this data to provide the maximum |
| 39 |
|
|
protection against data corruption? |
| 40 |
|
|
\item Microcontrollers on the same circuit board communicate with each other |
| 41 |
|
|
using UARTs. What form of checksum should be used to add protection |
| 42 |
|
|
against electrical noise? |
| 43 |
|
|
\end{enumerate} |
| 44 |
|
|
|
| 45 |
|
|
|
| 46 |
|
|
This chapter deals with the mathematical basis for four |
| 47 |
|
|
questions. |
| 48 |
|
|
|
| 49 |
|
|
\begin{enumerate} |
| 50 |
|
|
\item What is the mathematical basis for redundancy to allow error |
| 51 |
|
|
detection and error correction? |
| 52 |
|
|
\item How can redundancy be added to data to enable detection of errors? |
| 53 |
|
|
\item How can redundancy be added to data to enable correction of |
| 54 |
|
|
errors? |
| 55 |
|
|
\item How can adding redundancy (encoding) and detecting and correcting |
| 56 |
|
|
errors (decoding) be performed efficiently in |
| 57 |
|
|
microcontroller software? |
| 58 |
|
|
\end{enumerate} |
| 59 |
|
|
|
| 60 |
|
|
Note that although the results presented in this chapter for the most part |
| 61 |
|
|
have their origins in the study of communication channels, the problem of |
| 62 |
|
|
protecting computer storage that may degrade (disc, tape, battery-backed RAM, |
| 63 |
|
|
EEPROM, etc.) is mathematically the same problem as protecting data transmitted |
| 64 |
|
|
through a communication channel. In either case $k$ data bits are protected |
| 65 |
|
|
by $n-k$ check bits (see Figure \ref{fig:cedc0:scon0:sccb0:01}), |
| 66 |
|
|
and the essence of the mathematical problem is how best to |
| 67 |
|
|
select the check bits. |
| 68 |
|
|
|
| 69 |
|
|
|
| 70 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 71 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 72 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 73 |
|
|
\section{Coding Concepts} |
| 74 |
|
|
%Section tag: con0 |
| 75 |
|
|
\label{cedc0:scon0} |
| 76 |
|
|
|
| 77 |
|
|
\index{coding theory}\emph{Coding theory} is the branch of mathematics |
| 78 |
|
|
concerned with transmitting data across noisy channels and recovering |
| 79 |
|
|
the data \cite{bibref:w:ctfirst50}. In this section we introduce the |
| 80 |
|
|
basic concepts and terminology which apply to microcontroller work. |
| 81 |
|
|
|
| 82 |
|
|
|
| 83 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 84 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 85 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 86 |
|
|
\subsection{Bits, Communication Channels, Messages, And Check Bits} |
| 87 |
|
|
%Subection tag: ccb0 |
| 88 |
|
|
\label{cedc0:scon0:sccb0} |
| 89 |
|
|
|
| 90 |
|
|
We assume that the data we wish to transmit is an ordered sequence of \index{bit}bits. |
| 91 |
|
|
Each bit is a symbol of the \index{binary alphabet}binary alphabet, |
| 92 |
|
|
$\mathbb{B} = \{0,1\}$. Many results in coding theory have been generalized to |
| 93 |
|
|
alphabets with more than two symbols, but for microcontroller work it is adequate |
| 94 |
|
|
to consider only $\mathbb{B}$, and in this chapter only |
| 95 |
|
|
$\mathbb{B}$ is considered. |
| 96 |
|
|
|
| 97 |
|
|
Bits are transmitted through a \index{communication channel}\index{channel}% |
| 98 |
|
|
\emph{communication channel} (or simply \emph{channel}), which may with probability $p$ |
| 99 |
|
|
corrupt a transmitted bit from 0 to 1 or vice-versa; or with |
| 100 |
|
|
probability $q=1-p$ fail to corrupt a bit. For analysis, |
| 101 |
|
|
we make the simplest mathematical assumptions and assume that |
| 102 |
|
|
the probability of corruption from 0 to 1 is the same as the probability |
| 103 |
|
|
of corruption from 1 to 0 (i.e. $p_{0\rightarrow{}1} = p_{1\rightarrow{}0} = p$), |
| 104 |
|
|
and that corruption of each bit is independent. Alternately, we may imagine that rather |
| 105 |
|
|
than being potentially corrupted during transmission, each bit is potentially |
| 106 |
|
|
corrupted by the degradation of computer storage. |
| 107 |
|
|
|
| 108 |
|
|
We assume that data is transmitted in blocks of |
| 109 |
|
|
$n$ bits, consisting of $k$ data bits with $n-k$ check bits |
| 110 |
|
|
(redundancy bits) appended (Figure \ref{fig:cedc0:scon0:sccb0:01}). This concatenation of |
| 111 |
|
|
$k$ data bits and $n-k$ check bits is called a \index{message}\emph{message}. |
| 112 |
|
|
Most commonly |
| 113 |
|
|
in practice, $8 \vworkdivides n,k$ (and consequently |
| 114 |
|
|
$8 \vworkdivides (n-k)$), although this is not required. |
| 115 |
|
|
If data is stored rather than transmitted, we may assume that |
| 116 |
|
|
the check bits are stored at the last addresses of ROM or EEPROM. |
| 117 |
|
|
As explained in Section \ref{cedc0:scon0:scco0}, |
| 118 |
|
|
in this chapter only codes where the checkbits are appended to the unmodified |
| 119 |
|
|
data bits are considered. |
| 120 |
|
|
|
| 121 |
|
|
Notationally, we treat the $n$-bit message as an ordered collection of |
| 122 |
|
|
bits, represented by a row vector |
| 123 |
|
|
|
| 124 |
|
|
\begin{equation} |
| 125 |
|
|
\label{eq:cedc0:scon0:sccb0:01} |
| 126 |
|
|
[m_0, m_1, \ldots{}, m_{n-1}] . |
| 127 |
|
|
\end{equation} |
| 128 |
|
|
|
| 129 |
|
|
\noindent{}(Figure \ref{fig:cedc0:scon0:sccb0:01}, |
| 130 |
|
|
includes bit notational conventions.) $m_0$ through $m_{k-1}$ are data bits, and |
| 131 |
|
|
$m_k$ through $m_{n-1}$ are check bits. We may also |
| 132 |
|
|
treat the vector in (\ref{eq:cedc0:scon0:sccb0:01}) as |
| 133 |
|
|
the concatenation of data bits $d_0$ through $d_{k-1}$ and |
| 134 |
|
|
check bits $c_0$ through $c_{n-k-1}$, in which case we use |
| 135 |
|
|
either of the following notations: |
| 136 |
|
|
|
| 137 |
|
|
\begin{eqnarray} |
| 138 |
|
|
\label{eq:cedc0:scon0:sccb0:02} |
| 139 |
|
|
& [d_0, d_1, \ldots{}, d_{k-1}, c_0, c_1, \ldots{}, c_{n-k-1}] , & \\ |
| 140 |
|
|
\label{eq:cedc0:scon0:sccb0:02b} |
| 141 |
|
|
& [d_0, d_1, \ldots{}, d_{k-1}] | [c_0, c_1, \ldots{}, c_{n-k-1}] . & |
| 142 |
|
|
\end{eqnarray} |
| 143 |
|
|
|
| 144 |
|
|
Implicit in |
| 145 |
|
|
this model is the assumption that a framing error (where communication hardware or |
| 146 |
|
|
software misidentifies a block of data in time) is much less probable than |
| 147 |
|
|
a collection of bit errors which overwhelm the detection/correction |
| 148 |
|
|
capability of the $n-k$ check bits. There are in fact some |
| 149 |
|
|
scenarios\footnote{One classic example is the CAN bit-stuffing vulnerability which can |
| 150 |
|
|
with some data patterns lower the Hamming distance of CAN to 2.} |
| 151 |
|
|
where mechanisms exist to circumvent the function of the check bits by creating |
| 152 |
|
|
framing errors. |
| 153 |
|
|
By their nature, such scenarios involve the corruption of a small number of bits |
| 154 |
|
|
(or samples) in a way so as to generate a framing error and shift a large number of bits |
| 155 |
|
|
right or left. We assume for analytic convenience that the probability of |
| 156 |
|
|
a framing error is much less than the probability of the corruption of enough bits |
| 157 |
|
|
to overwhelm the capability of the check bits. However, experience has shown that |
| 158 |
|
|
this assumption needs to be verified, as many practical communication protocols have |
| 159 |
|
|
framing weaknesses.\footnote{Note that the notion of a framing error does not apply |
| 160 |
|
|
to a medium that does not use start and end markers that might be misinterpreted. |
| 161 |
|
|
For example, ROM or EEPROM have no notion of a framing error.} |
| 162 |
|
|
|
| 163 |
|
|
\begin{figure} |
| 164 |
|
|
\centering |
| 165 |
|
|
\includegraphics[width=4.6in]{c_edc0/cword01.eps} |
| 166 |
|
|
\caption{Message Consisting Of The Concatenation Of $k$ Data Bits And $n-k$ |
| 167 |
|
|
Check Bits, With Bit Notational Conventions} |
| 168 |
|
|
\label{fig:cedc0:scon0:sccb0:01} |
| 169 |
|
|
\end{figure} |
| 170 |
|
|
|
| 171 |
|
|
We have referred to \emph{check bits} without describing the ways in which they |
| 172 |
|
|
might be calculated. We use the term \index{checksum}\emph{checksum} to refer |
| 173 |
|
|
to the contiguous group of $n-k$ check bits; whether or not the bits are calculated |
| 174 |
|
|
through summation. In general, we impose only the requirement that the $n-k$-bit |
| 175 |
|
|
checksum is a deterministic function of the $k$ data bits. |
| 176 |
|
|
|
| 177 |
|
|
We often refer to a message or a portion of a message as a |
| 178 |
|
|
\index{vector}\emph{vector}. This nomenclature is appropriate because it is |
| 179 |
|
|
convenient to treat a message as a row vector of bits. |
| 180 |
|
|
An 80-bit message might |
| 181 |
|
|
be viewed as a $1 \times 80$ matrix (i.e. a row vector) with each matrix element |
| 182 |
|
|
$\in \mathbb{B}$. We use \emph{message} and \emph{vector} somewhat interchangeably. |
| 183 |
|
|
|
| 184 |
|
|
We define the \index{weight}\emph{weight} of a message or vector as the number of |
| 185 |
|
|
1's in the message or vector. We denote the weight of a vector or message $v$ as |
| 186 |
|
|
$wt(v)$. |
| 187 |
|
|
|
| 188 |
|
|
|
| 189 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 190 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 191 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 192 |
|
|
\subsection[Codewords, Codes, And \protect\mbox{\protect$(n,k)$} Block Codes] |
| 193 |
|
|
{Codewords, Codes And \protect\mbox{\protect\boldmath$(n,k)$} Block Codes} |
| 194 |
|
|
%Subection tag: cco0 |
| 195 |
|
|
\label{cedc0:scon0:scco0} |
| 196 |
|
|
|
| 197 |
|
|
A \index{codeword}\emph{codeword} (as we define it here) is a message in which |
| 198 |
|
|
the $n-k$ check bits are consistent with the $k$ data bits. |
| 199 |
|
|
Under this definition, all codewords are messages, but not all possible messages |
| 200 |
|
|
are codewords. |
| 201 |
|
|
|
| 202 |
|
|
A common cognitive misconception is that it matters in transmission or |
| 203 |
|
|
storage whether the $k$ data bits or the $n-k$ check bits are corrupted. |
| 204 |
|
|
It matters not. We seek mathematical properties that apply to the messages |
| 205 |
|
|
and codewords, not to the $k$ data bits or $n-k$ check bits separately. |
| 206 |
|
|
|
| 207 |
|
|
In the most general terms, a \index{code}\emph{code} is \emph{any} system |
| 208 |
|
|
of information representation for transmission, not necessarily requiring |
| 209 |
|
|
transmission in fixed-length blocks. However, in this discussion, by |
| 210 |
|
|
\emph{code} we mean the set of all bit |
| 211 |
|
|
patterns with data and check bits consistent (i.e. all codewords) |
| 212 |
|
|
which can be transmitted over a communication channel or stored |
| 213 |
|
|
in computer memory. For example, |
| 214 |
|
|
$\{000, 011, 101, 110\}$ is a code. |
| 215 |
|
|
|
| 216 |
|
|
A code may be specified either by enumeration or by rule. For example, |
| 217 |
|
|
we might also specify the code of the previous paragraph as |
| 218 |
|
|
$\{ABC: C=A \oplus B\}$. With larger codes, enumeration is naturally not practical and |
| 219 |
|
|
also not necessary to study the properties of interest. |
| 220 |
|
|
|
| 221 |
|
|
An |
| 222 |
|
|
\index{(n,k) block code@$(n,k)$ block code}\index{n,k block code@$(n,k)$ block code}% |
| 223 |
|
|
$(n,k)$ \emph{block code} is a code where $n$ bits are transmitted (or stored) at a |
| 224 |
|
|
time, and characterized by a function which maps from $k$ data bits to $n$ bits which |
| 225 |
|
|
are transmitted (or stored). |
| 226 |
|
|
|
| 227 |
|
|
In a general $(n,k)$ block code, the $n$ transmitted |
| 228 |
|
|
bits are not required to contain or resemble the $k$ data bits; and if the $k$ data bits |
| 229 |
|
|
are contained they are not required to have a specific order or placement within |
| 230 |
|
|
the $n$ transmitted bits. Because we are interested in adding |
| 231 |
|
|
redundancy to ROM and in other applications |
| 232 |
|
|
where the stored data must be contiguous and unmodified, we confine ourselves |
| 233 |
|
|
to $(n,k)$ block codes as depicted in Figure |
| 234 |
|
|
\ref{fig:cedc0:scon0:sccb0:01}, where the $k$ data bits are contiguous, unchanged, |
| 235 |
|
|
in their original order, and prepended to the $n-k$ check bits. |
| 236 |
|
|
|
| 237 |
|
|
|
| 238 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 239 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 240 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 241 |
|
|
\subsection{Hamming Distance, Minimum Hamming Distance, And Errors} |
| 242 |
|
|
%Subection tag: mhd0 |
| 243 |
|
|
\label{cedc0:scon0:smhd0} |
| 244 |
|
|
|
| 245 |
|
|
We define the \index{Hamming distance}\emph{Hamming distance} between |
| 246 |
|
|
two same-length blocks $c$ and $d$, denoted $d(c,d)$, as the number of bit positions |
| 247 |
|
|
in which the blocks differ. Note that $d(c,d)$ is necessarily the same as the number |
| 248 |
|
|
of 1's in $c \oplus d$. Note also that $d(c,d)$ is the weight of the |
| 249 |
|
|
exclusive-OR of $c$ and $d$, i.e. $d(c,d) = wt(c \oplus d)$. (We discuss the properties |
| 250 |
|
|
of the exclusive-OR function later in Section \ref{cedc0:sfft0:dff0}.) |
| 251 |
|
|
|
| 252 |
|
|
We define the \index{minimum Hamming distance}\emph{minimum Hamming distance} |
| 253 |
|
|
of a code, denoted $\hat{d}$, as the smallest Hamming distance between any two |
| 254 |
|
|
members of the code. For example, the minimum Hamming distance of |
| 255 |
|
|
$\{000, 011, 101, 110\}$, |
| 256 |
|
|
denoted $\hat{d}(\{000, 011, 101, 110\})$, |
| 257 |
|
|
is 2, and the minimum Hamming distance of |
| 258 |
|
|
$\{0001, 0110, 1010, 1101\}$, |
| 259 |
|
|
denoted $\hat{d}(\{0001, 0110, 1010, 1101\})$, |
| 260 |
|
|
is also 2.\footnote{See Exercise |
| 261 |
|
|
\ref{exe:cedc0:sexe0:01}.} |
| 262 |
|
|
|
| 263 |
|
|
We define an \index{error}\emph{error} (or alternatively, a |
| 264 |
|
|
\emph{bit corruption} or simply a \emph{corruption}) as the corruption |
| 265 |
|
|
of a transmitted or stored |
| 266 |
|
|
bit from 0 to 1 or from 1 to 0. As mentioned in |
| 267 |
|
|
Section \ref{cedc0:scon0:sccb0}, we assume that a corruption may occur |
| 268 |
|
|
with probability $p$ or fail to occur with probability $q=1-p$. |
| 269 |
|
|
|
| 270 |
|
|
We define a \index{message corruption}\emph{message corruption} or simply |
| 271 |
|
|
\emph{corruption} as the corruption of one or more bits within the message |
| 272 |
|
|
during transmission or storage. |
| 273 |
|
|
Note that the minimum Hamming distance $\hat{d}$ of a code |
| 274 |
|
|
guarantees that at least $\hat{d}$ errors are required to transform |
| 275 |
|
|
one codeword into another, thus guaranteeing that any corruption |
| 276 |
|
|
of $\hat{d}-1$ or fewer bits is detectable. |
| 277 |
|
|
|
| 278 |
|
|
If the errors within a message are distributed in a special way, we may be |
| 279 |
|
|
able to devise codes that are more resistant to these special distributions |
| 280 |
|
|
than to an arbitrary distribution of errors. One such special distribution |
| 281 |
|
|
is a \index{burst error}\emph{burst error}. A \emph{burst error of length $b$} |
| 282 |
|
|
is defined as any number of errors in a span of $b$ bits. For example, corruption of |
| 283 |
|
|
00001111 to 00011001 represents a burst error of length 4 (the corruptions are in |
| 284 |
|
|
the 4th, 6th, and 7th bits, which span 4 bits inclusive). A burst error may naturally |
| 285 |
|
|
span no fewer than 1 bit and no more than $n$ bits. |
| 286 |
|
|
|
| 287 |
|
|
We are very careful \emph{not} to define a codeword as an |
| 288 |
|
|
uncorrupted message. No code except a code consisting of only one codeword |
| 289 |
|
|
can sustain an unlimited number of bit corruptions while still guaranteeing |
| 290 |
|
|
that the message corruption will be detectable.\footnote{This observation that |
| 291 |
|
|
a single-codeword code can sustain an unlimited number of bit corruptions is a |
| 292 |
|
|
mathematical fallacy and a semantic parlor trick. An $(n,k)$ block code with only |
| 293 |
|
|
one code word effectively has a maximum Hamming distance $\hat{d}$ of $n$ plus the number |
| 294 |
|
|
of framing bits, stop bits, etc. in the message as transmitted. Sufficient noise |
| 295 |
|
|
in a communication channel may cause communication hardware to believe the |
| 296 |
|
|
codeword was transmitted when in fact it was not. See the remarks regarding |
| 297 |
|
|
framing weaknesses in Section \ref{cedc0:scon0:sccb0}.} A codeword may in fact |
| 298 |
|
|
be a corrupted message where the number of bit corruptions has overwhelmed the |
| 299 |
|
|
minimum Hamming distance $\hat{d}$ of the code so as to transform one codeword |
| 300 |
|
|
into another. |
| 301 |
|
|
|
| 302 |
|
|
Generally, error-detecting and error-correcting codes |
| 303 |
|
|
(Section \ref{cedc0:scon0:secv0}) must be selected with some knowledge |
| 304 |
|
|
of the error |
| 305 |
|
|
rates of the |
| 306 |
|
|
communication channel or storage medium. Noisier communication channels |
| 307 |
|
|
or poorer storage mediums require codes with |
| 308 |
|
|
better error-detecting and/or error-correcting properties. Normally, the design goal |
| 309 |
|
|
is to achieve a very low probability of undetected corruption or uncorrectable corruption. |
| 310 |
|
|
|
| 311 |
|
|
|
| 312 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 313 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 314 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 315 |
|
|
\subsection{Error-Detecting Versus Error-Correcting Codes} |
| 316 |
|
|
%Subection tag: ecv0 |
| 317 |
|
|
\label{cedc0:scon0:secv0} |
| 318 |
|
|
|
| 319 |
|
|
An \index{error-detecting code}\emph{error-detecting code} is a code which is |
| 320 |
|
|
designed so that message errors |
| 321 |
|
|
(a message which is not a codeword) will be detected but not corrected. |
| 322 |
|
|
Error-detecting codes are attractive |
| 323 |
|
|
when there is the opportunity to request that the transmitter retransmit the |
| 324 |
|
|
corrupted data, or when obtaining a correct copy of the data is not important but |
| 325 |
|
|
detecting (and perhaps discarding) corrupted data is important. |
| 326 |
|
|
|
| 327 |
|
|
An \index{error-correcting code}\emph{error-correcting code} is a code designed |
| 328 |
|
|
so that message errors can be both detected and corrected. Error-correcting |
| 329 |
|
|
codes are attractive when |
| 330 |
|
|
there is no opportunity for retransmission of the corrupted data, but possessing |
| 331 |
|
|
a correct copy of the data is important. Example attractive |
| 332 |
|
|
applications of error-correcting codes are compact disc audio data (where the |
| 333 |
|
|
CD should play even with scratches, and there is no opportunity to obtain |
| 334 |
|
|
retransmission of the data) and data transmitted from space exploration satellites |
| 335 |
|
|
(where the signal-to-noise ratio is low, and there is not opportunity for retransmission |
| 336 |
|
|
or perhaps not even two-way communication). |
| 337 |
|
|
|
| 338 |
|
|
In this section we show the required relationship between minimum Hamming |
| 339 |
|
|
distance $\hat{d}$ and the error-detecting and error-correcting capabilities |
| 340 |
|
|
of a code. |
| 341 |
|
|
|
| 342 |
|
|
We define the \index{error-detecting capability of a code}\index{code!error-detecting capability}% |
| 343 |
|
|
\emph{error-detecting capability} $d_{ED}$ of a code as the largest number of bit errors |
| 344 |
|
|
in a message which will \emph{always} be detectable. It follows |
| 345 |
|
|
immediately and intuitively that |
| 346 |
|
|
|
| 347 |
|
|
\begin{equation} |
| 348 |
|
|
\label{eq:cedc0:scon0:secv0:01} |
| 349 |
|
|
d_{ED} = \hat{d} - 1 . |
| 350 |
|
|
\end{equation} |
| 351 |
|
|
|
| 352 |
|
|
\noindent{}If the minimum |
| 353 |
|
|
Hamming distance of a code is $\hat{d}$, then there exists at least |
| 354 |
|
|
one pair of codewords |
| 355 |
|
|
$c_1, c_2$ such that $d(c_1, c_2) = \hat{d}$. Thus it is possible to corrupt |
| 356 |
|
|
$c_1$ into $c_2$ with $\hat{d}$ corrupted bits and therefore |
| 357 |
|
|
$d_{ED} < \hat{d}$. On the other hand, the minimum Hamming distance |
| 358 |
|
|
$\hat{d}$ guarantees that it is \emph{not} possible to corrupt from one codeword to another |
| 359 |
|
|
with only $\hat{d}-1$ bit corruptions. Therefore |
| 360 |
|
|
(\ref{eq:cedc0:scon0:secv0:01}) is true. |
| 361 |
|
|
|
| 362 |
|
|
We define the \index{error correcting capability of a code}\index{code!error correcting capability}% |
| 363 |
|
|
\emph{error correcting capability} $d_{EC}$ of a code as the largest number of bit errors |
| 364 |
|
|
in a message which will \emph{always} be correctable. By \emph{correctable} we mean |
| 365 |
|
|
that we can recover the original $n$-bit codeword into which errors were introduced. |
| 366 |
|
|
|
| 367 |
|
|
To illustrate the relationship between Hamming distance and the error correcting |
| 368 |
|
|
capability of a code, consider the code $\{000, 111\}$ depicted in |
| 369 |
|
|
Figure \ref{fig:cedc0:scon0:secv0:01}. In the figure, each edge in the cube depicts |
| 370 |
|
|
a single bit error which may occur in a message. Each vertex in the cube |
| 371 |
|
|
represents a message. |
| 372 |
|
|
|
| 373 |
|
|
\begin{figure} |
| 374 |
|
|
\centering |
| 375 |
|
|
\includegraphics[height=2.5in]{c_edc0/cube01.eps} |
| 376 |
|
|
\caption{Three-Dimensional Cube Illustrating Error Correction With Code $\{000, 111\}$} |
| 377 |
|
|
\label{fig:cedc0:scon0:secv0:01} |
| 378 |
|
|
\end{figure} |
| 379 |
|
|
|
| 380 |
|
|
Note that the minimum Hamming $\hat{d}$ distance of the code $\{000, 111\}$ is 3: in |
| 381 |
|
|
Figure \ref{fig:cedc0:scon0:secv0:01} one must travel along three edges |
| 382 |
|
|
(corresponding to three bit errors) in order to travel from 000 to 111 or back. |
| 383 |
|
|
|
| 384 |
|
|
If we claim that a code has an error correcting capability of $d_{EC}$, |
| 385 |
|
|
then any corruption of a codeword by $d_{EC}$ errors must be correctable. |
| 386 |
|
|
To be \emph{correctable} means that if we guess based on the corrupted |
| 387 |
|
|
codeword what the original codeword is, we must always be able to guess |
| 388 |
|
|
correctly. This notion implies that the original codeword must be the |
| 389 |
|
|
closest codeword (as measured by number of bit corruptions) to the corrupted codeword. |
| 390 |
|
|
|
| 391 |
|
|
This notion of \emph{closest} codeword leads to the notion of a \emph{packing sphere}. |
| 392 |
|
|
A \emph{packing sphere of radius $\rho$} is the set of all messages |
| 393 |
|
|
at a distance of $\rho$ or less from a given codeword. In order for |
| 394 |
|
|
a code to have an error correcting capability of $d_{EC}=\rho$, |
| 395 |
|
|
the packing spheres or radius $\rho$ about all codewords must be disjoint. |
| 396 |
|
|
This ensures that any message at a distance $d_{EC}$ or less from a codeword |
| 397 |
|
|
does, in fact, have a \emph{nearest} codeword. |
| 398 |
|
|
|
| 399 |
|
|
Figure \ref{fig:cedc0:scon0:secv0:02} is |
| 400 |
|
|
Figure \ref{fig:cedc0:scon0:secv0:01} redrawn to show the packing spheres of |
| 401 |
|
|
radius $\rho=1$ about the two codewords 000 and 111. The code |
| 402 |
|
|
$\{000,111\}$ depicted in Figures \ref{fig:cedc0:scon0:secv0:01} and |
| 403 |
|
|
\ref{fig:cedc0:scon0:secv0:02} has an error correcting capability of |
| 404 |
|
|
$d_{EC}=1$. For error correction, any message in the packing sphere |
| 405 |
|
|
about 000 must be mapped back to 000, and any message in the packing sphere |
| 406 |
|
|
about 111 must be transformed back to 111. |
| 407 |
|
|
|
| 408 |
|
|
\begin{figure} |
| 409 |
|
|
\centering |
| 410 |
|
|
\includegraphics[height=2.5in]{c_edc0/cube02.eps} |
| 411 |
|
|
\caption{Packing Spheres Of Radius $\rho{}=1$ About Codewords 000 And 111} |
| 412 |
|
|
\label{fig:cedc0:scon0:secv0:02} |
| 413 |
|
|
\end{figure} |
| 414 |
|
|
|
| 415 |
|
|
The requirement for disjointness of packing spheres immediately leads to |
| 416 |
|
|
the constraint |
| 417 |
|
|
|
| 418 |
|
|
\begin{equation} |
| 419 |
|
|
\label{eq:cedc0:scon0:secv0:02} |
| 420 |
|
|
\hat{d} > 2 \rho |
| 421 |
|
|
\end{equation} |
| 422 |
|
|
|
| 423 |
|
|
\noindent{}or equivalently when considering only integers that |
| 424 |
|
|
|
| 425 |
|
|
\begin{equation} |
| 426 |
|
|
\label{eq:cedc0:scon0:secv0:03} |
| 427 |
|
|
\hat{d} \geq 2 \rho + 1 . |
| 428 |
|
|
\end{equation} |
| 429 |
|
|
|
| 430 |
|
|
\noindent{}Since the radius $\rho$ of the packing sphere is |
| 431 |
|
|
equivalent to the error correcting capability $d_{EC}$ of |
| 432 |
|
|
a code, we may equivalently write |
| 433 |
|
|
(\ref{eq:cedc0:scon0:secv0:02}) and (\ref{eq:cedc0:scon0:secv0:03}) |
| 434 |
|
|
as $\hat{d} > 2 d_{EC}$ and $\hat{d} \geq 2 d_{EC} + 1$, respectively. |
| 435 |
|
|
|
| 436 |
|
|
(\ref{eq:cedc0:scon0:secv0:02}) and (\ref{eq:cedc0:scon0:secv0:03}) |
| 437 |
|
|
treat minimum Hamming distance $\hat{d}$ as a function of |
| 438 |
|
|
the packing sphere radius $\rho$. With a known minimum Hamming distance |
| 439 |
|
|
$\hat{d}$, one may also calculate the largest disjoint |
| 440 |
|
|
packing spheres that can be constructed: |
| 441 |
|
|
|
| 442 |
|
|
\begin{equation} |
| 443 |
|
|
\label{eq:cedc0:scon0:secv0:04} |
| 444 |
|
|
d_{EC} = \rho = \left\lfloor {\frac{\hat{d}-1}{2}} \right\rfloor . |
| 445 |
|
|
\end{equation} |
| 446 |
|
|
|
| 447 |
|
|
This section has demonstrated the relationship between the minimum Hamming |
| 448 |
|
|
distance $\hat{d}$ of a code and the error detection capability of the code |
| 449 |
|
|
(Equation \ref{eq:cedc0:scon0:secv0:01}), as well as the relationship between the |
| 450 |
|
|
minimum Hamming |
| 451 |
|
|
distance $\hat{d}$ and the error correction capabilility |
| 452 |
|
|
(Equations \ref{eq:cedc0:scon0:secv0:02} through |
| 453 |
|
|
\ref{eq:cedc0:scon0:secv0:04}). |
| 454 |
|
|
|
| 455 |
|
|
Note that the relationships derived do apply to the example presented in |
| 456 |
|
|
Figures \ref{fig:cedc0:scon0:secv0:01} and \ref{fig:cedc0:scon0:secv0:02}. |
| 457 |
|
|
The code shown in the figures has a minimum Hamming distance $\hat{d}=3$. |
| 458 |
|
|
(\ref{eq:cedc0:scon0:secv0:01}) predicts that this code should have |
| 459 |
|
|
an error detection capability of $d_{ED}=2$, which is the case. |
| 460 |
|
|
(\ref{eq:cedc0:scon0:secv0:04}) predicts that this code should have an error correction |
| 461 |
|
|
capability $d_{EC}=1$, which is also the case and can be verified by |
| 462 |
|
|
examining Figure \ref{fig:cedc0:scon0:secv0:02}. |
| 463 |
|
|
|
| 464 |
|
|
In the code presented in Figures \ref{fig:cedc0:scon0:secv0:01} and |
| 465 |
|
|
\ref{fig:cedc0:scon0:secv0:02}, the union of all packing spheres of radius |
| 466 |
|
|
$\rho=1$ contains all messages (i.e. there are no messages which are not part of |
| 467 |
|
|
a packing sphere). Such a code is called a \emph{perfect code}. Most codes |
| 468 |
|
|
are not perfect codes, and this will be discussed later. |
| 469 |
|
|
|
| 470 |
|
|
|
| 471 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 472 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 473 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 474 |
|
|
\section[Finite Field Theory Applied To \protect\mbox{\protect$\mathbb{B}$}] |
| 475 |
|
|
{Finite Field Theory Applied To \protect\mbox{\protect\boldmath$\mathbb{B}$}} |
| 476 |
|
|
%Section tag: fft0 |
| 477 |
|
|
\label{cedc0:sfft0} |
| 478 |
|
|
|
| 479 |
|
|
This |
| 480 |
|
|
section deals with \index{finite field}finite field |
| 481 |
|
|
theory as applied to the binary alphabet, |
| 482 |
|
|
$\mathbb{B} = \{ 0, 1 \}$. |
| 483 |
|
|
This section is one of two sections in this chapter which deal with |
| 484 |
|
|
\index{finite field}finite field theory |
| 485 |
|
|
(the other section is Section \ref{cedc0:sfft1}, |
| 486 |
|
|
which deals with finite field theory as applied to polynomials). |
| 487 |
|
|
|
| 488 |
|
|
|
| 489 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 490 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 491 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 492 |
|
|
\subsection{\emph{Why} Field Theory?} |
| 493 |
|
|
%Subection tag: wft0 |
| 494 |
|
|
\label{cedc0:sfft0:wft0} |
| 495 |
|
|
|
| 496 |
|
|
The most important question to answer immediately (for engineers, anyway) |
| 497 |
|
|
is \emph{why} field theory is necessary at all. The answer is that |
| 498 |
|
|
there are two general approaches that can be used to approach coding |
| 499 |
|
|
theory: |
| 500 |
|
|
|
| 501 |
|
|
\begin{enumerate} |
| 502 |
|
|
\item \emph{Combinational:} |
| 503 |
|
|
approaching the problem by considering combinations and |
| 504 |
|
|
permutations (see Section \ref{cedc0:scob0}, for example). This approach |
| 505 |
|
|
can give some insight and produce useful bounds, but in general it is hard |
| 506 |
|
|
to approach the problem of generating codes with an arbitrarily large minimum |
| 507 |
|
|
Hamming distance $\hat{d}$ using a purely combinational approach. |
| 508 |
|
|
\item \emph{Field Theory:} approaching the problem by attempting to add algebraic |
| 509 |
|
|
structure to codes. This approach leads to classes of solutions that |
| 510 |
|
|
are unavailable using purely combinational approaches. To add |
| 511 |
|
|
\emph{algebraic structure} means to define operations so as to add useful |
| 512 |
|
|
algebraic properties that facilitate higher-level inferences |
| 513 |
|
|
and abstractions. For example, |
| 514 |
|
|
algebraic structure is ultimately what allows us to define the rank |
| 515 |
|
|
of a matrix with elements $\in \mathbb{B}$ in the same way we do with |
| 516 |
|
|
matrices with elements $\in \vworkrealset$. |
| 517 |
|
|
\end{enumerate} |
| 518 |
|
|
|
| 519 |
|
|
Note that combinational and field theory approaches are complementary: each |
| 520 |
|
|
approach gives some unique insight and solutions that the other approach cannot |
| 521 |
|
|
provide. |
| 522 |
|
|
|
| 523 |
|
|
Field theory is necessary in order to derive a framework in which to |
| 524 |
|
|
systematically generate codes with a large minimum Hamming distance $\hat{d}$. |
| 525 |
|
|
|
| 526 |
|
|
|
| 527 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 528 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 529 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 530 |
|
|
\subsection{Definition Of A Finite Field} |
| 531 |
|
|
%Subection tag: dff0 |
| 532 |
|
|
\label{cedc0:sfft0:dff0} |
| 533 |
|
|
|
| 534 |
|
|
We first define what a \index{finite field} \emph{finite field} is in general, and |
| 535 |
|
|
then we show how this definition is applied to $\mathbb{B} = \{ 0, 1 \}$. |
| 536 |
|
|
|
| 537 |
|
|
\begin{vworkdefinitionstatementpar}{Finite Field} |
| 538 |
|
|
A \emph{finite field} \cite{bibref:w:weissteinmathworld} |
| 539 |
|
|
is a finite set of elements (the cardinality of this |
| 540 |
|
|
set is called the \index{field order}\emph{field order}) which |
| 541 |
|
|
satisfies the field axioms |
| 542 |
|
|
listed in Table \ref{tbl:cedc0:sfft0:dff0:01} for both addition and |
| 543 |
|
|
multiplication. |
| 544 |
|
|
|
| 545 |
|
|
\begin{table} |
| 546 |
|
|
\caption{Field Axioms For A Finite Field (From \cite{bibref:w:weissteinmathworld})} |
| 547 |
|
|
\label{tbl:cedc0:sfft0:dff0:01} |
| 548 |
|
|
\begin{center} |
| 549 |
|
|
\begin{tabular}{|l|c|c|} |
| 550 |
|
|
\hline |
| 551 |
|
|
Name & Addition & Multiplication \\ |
| 552 |
|
|
\hline |
| 553 |
|
|
\hline |
| 554 |
|
|
Commutativity & $a+b = b+a$ & $ab = ba$ \\ |
| 555 |
|
|
\hline |
| 556 |
|
|
Associativity & $(a+b)+c=a+(b+c)$ & $(ab)c=a(bc)$ \\ |
| 557 |
|
|
\hline |
| 558 |
|
|
Distributivity & $a(b+c)=ab+ac$ & $(a+b)c=ac+bc$ \\ |
| 559 |
|
|
\hline |
| 560 |
|
|
Identity & $a+0=a=0+a$ & $a \cdot 1=a=1 \cdot a$ \\ |
| 561 |
|
|
\hline |
| 562 |
|
|
Inverses & $a+(-a)=0=(-a)+a$ & $aa^{-1}=1=a^{-1}a$ if $a \neq 0$ \\ |
| 563 |
|
|
\hline |
| 564 |
|
|
\end{tabular} |
| 565 |
|
|
\end{center} |
| 566 |
|
|
\end{table} |
| 567 |
|
|
|
| 568 |
|
|
Such a field is also called a \index{Galois field}\emph{Galois field}. |
| 569 |
|
|
In this chapter, we are concerned with the Galois field containing |
| 570 |
|
|
only two elements ($\mathbb{B}=\{ 0,1 \}$), and this field is denoted $GF(2)$. |
| 571 |
|
|
\end{vworkdefinitionstatementpar} |
| 572 |
|
|
\vworkdefinitionfooter{} |
| 573 |
|
|
|
| 574 |
|
|
The study of fields is a topic from \index{abstract algebra}\emph{abstract algebra}, |
| 575 |
|
|
a branch of mathematics. This chapter provides only the |
| 576 |
|
|
minimum amount of information about finite field theory to explain |
| 577 |
|
|
the presented application, and so there are many mathematical results |
| 578 |
|
|
not discussed. |
| 579 |
|
|
|
| 580 |
|
|
The definition of a finite field (Definition \ref{tbl:cedc0:sfft0:dff0:01}) |
| 581 |
|
|
does not specify how addition and multiplication are defined---it only |
| 582 |
|
|
specifies what properties must be met by whatever choice is made. |
| 583 |
|
|
We now present the only possible choices for addition, multiplication, |
| 584 |
|
|
formation of the additive inverse, and formation of the multiplicative inverse |
| 585 |
|
|
for the elements of $\mathbb{B}=\{ 0,1 \}$. |
| 586 |
|
|
|
| 587 |
|
|
Addition (Table \ref{tbl:cedc0:sfft0:dff0:02}) is performed modulo 2, and is |
| 588 |
|
|
identical to the exclusive-OR |
| 589 |
|
|
function. In computer software, this function is normally implemented using |
| 590 |
|
|
the XOR machine instruction, which operates on many bits in parallel. Although |
| 591 |
|
|
we would be justified in using `$+$' to denote this operation, instead we |
| 592 |
|
|
use `$\oplus$' because it corresponds more closely to the machine instruction |
| 593 |
|
|
actually used to implement this binary operation. |
| 594 |
|
|
|
| 595 |
|
|
\begin{table} |
| 596 |
|
|
\caption{Truth Table Of Addition Over $\mathbb{B}=\{ 0,1 \}$ (Denoted $\oplus$)} |
| 597 |
|
|
\label{tbl:cedc0:sfft0:dff0:02} |
| 598 |
|
|
\begin{center} |
| 599 |
|
|
\begin{tabular}{|c|c|c|} |
| 600 |
|
|
\hline |
| 601 |
|
|
$a$ & $b$ & $c = a \oplus b$ \\ |
| 602 |
|
|
\hline |
| 603 |
|
|
\hline |
| 604 |
|
|
0 & 0 & 0 \\ |
| 605 |
|
|
\hline |
| 606 |
|
|
0 & 1 & 1 \\ |
| 607 |
|
|
\hline |
| 608 |
|
|
1 & 0 & 1 \\ |
| 609 |
|
|
\hline |
| 610 |
|
|
1 & 1 & 0 \\ |
| 611 |
|
|
\hline |
| 612 |
|
|
\end{tabular} |
| 613 |
|
|
\end{center} |
| 614 |
|
|
\end{table} |
| 615 |
|
|
|
| 616 |
|
|
Subtraction is equivalent to adding the additive inverse. |
| 617 |
|
|
Table \ref{tbl:cedc0:sfft0:dff0:03} provides the |
| 618 |
|
|
additive inverses of the field elements 0 and 1. Table |
| 619 |
|
|
\ref{tbl:cedc0:sfft0:dff0:04} is the truth table for subtraction. |
| 620 |
|
|
|
| 621 |
|
|
\begin{table} |
| 622 |
|
|
\caption{Truth Table Of Additive Inverse Over $\mathbb{B}=\{ 0,1 \}$} |
| 623 |
|
|
\label{tbl:cedc0:sfft0:dff0:03} |
| 624 |
|
|
\begin{center} |
| 625 |
|
|
\begin{tabular}{|c|c|} |
| 626 |
|
|
\hline |
| 627 |
|
|
$a$ & $-a$ \\ |
| 628 |
|
|
\hline |
| 629 |
|
|
\hline |
| 630 |
|
|
0 & 0 \\ |
| 631 |
|
|
\hline |
| 632 |
|
|
1 & 1 \\ |
| 633 |
|
|
\hline |
| 634 |
|
|
\end{tabular} |
| 635 |
|
|
\end{center} |
| 636 |
|
|
\end{table} |
| 637 |
|
|
|
| 638 |
|
|
\begin{table} |
| 639 |
|
|
\caption{Truth Table Of Subtraction Over $\mathbb{B}=\{ 0,1 \}$ (Denoted $-$)} |
| 640 |
|
|
\label{tbl:cedc0:sfft0:dff0:04} |
| 641 |
|
|
\begin{center} |
| 642 |
|
|
\begin{tabular}{|c|c|c|} |
| 643 |
|
|
\hline |
| 644 |
|
|
$a$ & $b$ & $c = a - b = a + (-b)$ \\ |
| 645 |
|
|
\hline |
| 646 |
|
|
\hline |
| 647 |
|
|
0 & 0 & 0 \\ |
| 648 |
|
|
\hline |
| 649 |
|
|
0 & 1 & 1 \\ |
| 650 |
|
|
\hline |
| 651 |
|
|
1 & 0 & 1 \\ |
| 652 |
|
|
\hline |
| 653 |
|
|
1 & 1 & 0 \\ |
| 654 |
|
|
\hline |
| 655 |
|
|
\end{tabular} |
| 656 |
|
|
\end{center} |
| 657 |
|
|
\end{table} |
| 658 |
|
|
|
| 659 |
|
|
|
| 660 |
|
|
Table \ref{tbl:cedc0:sfft0:dff0:05} supplies the definition of the |
| 661 |
|
|
multiplication operation in $GF(2)$. |
| 662 |
|
|
|
| 663 |
|
|
\begin{table} |
| 664 |
|
|
\caption{Truth Table Of Multiplication Over $\mathbb{B}=\{ 0,1 \}$} |
| 665 |
|
|
\label{tbl:cedc0:sfft0:dff0:05} |
| 666 |
|
|
\begin{center} |
| 667 |
|
|
\begin{tabular}{|c|c|c|} |
| 668 |
|
|
\hline |
| 669 |
|
|
$a$ & $b$ & $c = a b$ \\ |
| 670 |
|
|
\hline |
| 671 |
|
|
\hline |
| 672 |
|
|
0 & 0 & 0 \\ |
| 673 |
|
|
\hline |
| 674 |
|
|
0 & 1 & 0 \\ |
| 675 |
|
|
\hline |
| 676 |
|
|
1 & 0 & 0 \\ |
| 677 |
|
|
\hline |
| 678 |
|
|
1 & 1 & 1 \\ |
| 679 |
|
|
\hline |
| 680 |
|
|
\end{tabular} |
| 681 |
|
|
\end{center} |
| 682 |
|
|
\end{table} |
| 683 |
|
|
|
| 684 |
|
|
Table \ref{tbl:cedc0:sfft0:dff0:06} supplies the definition of the |
| 685 |
|
|
multiplicative inverse over $GF(2)$. Note that division is assumed |
| 686 |
|
|
to be the same as multiplication by the multiplicative inverse. |
| 687 |
|
|
As required by the definition of a field, division by 0 is not |
| 688 |
|
|
defined. |
| 689 |
|
|
|
| 690 |
|
|
\begin{table} |
| 691 |
|
|
\caption{Truth Table Of Multiplicative Inverse Over $\mathbb{B}=\{ 0,1 \}$} |
| 692 |
|
|
\label{tbl:cedc0:sfft0:dff0:06} |
| 693 |
|
|
\begin{center} |
| 694 |
|
|
\begin{tabular}{|c|c|} |
| 695 |
|
|
\hline |
| 696 |
|
|
$a$ & $a^{-1}$ \\ |
| 697 |
|
|
\hline |
| 698 |
|
|
\hline |
| 699 |
|
|
0 & Undefined \\ |
| 700 |
|
|
\hline |
| 701 |
|
|
1 & 1 \\ |
| 702 |
|
|
\hline |
| 703 |
|
|
\end{tabular} |
| 704 |
|
|
\end{center} |
| 705 |
|
|
\end{table} |
| 706 |
|
|
|
| 707 |
|
|
There are unique properites of calculations within |
| 708 |
|
|
$GF(2)$. We summarize these unique properties here. |
| 709 |
|
|
|
| 710 |
|
|
\begin{enumerate} |
| 711 |
|
|
\item \label{prop:enum:cedc0:sfft0:dff0:01:01} |
| 712 |
|
|
Addition and subtraction |
| 713 |
|
|
are identical. This means that we can always replace `$-$' with `$\oplus$', |
| 714 |
|
|
and it also means we can break the usual rules of algebra and simply |
| 715 |
|
|
``drag'' terms joined by `$\oplus$' from one side of an equality to the other. |
| 716 |
|
|
Specifically, |
| 717 |
|
|
|
| 718 |
|
|
\begin{equation} |
| 719 |
|
|
\label{eq:cedc0:sfft0:dff0:01} |
| 720 |
|
|
(a = b \oplus c) \vworkequiv (a \oplus b = c) \vworkequiv (a \oplus b \oplus c = 0) . |
| 721 |
|
|
\end{equation} |
| 722 |
|
|
|
| 723 |
|
|
\item \label{prop:enum:cedc0:sfft0:dff0:01:02} |
| 724 |
|
|
Adding any value to itself |
| 725 |
|
|
yields $0$. This comes directly because $0 \oplus 0 = 1 \oplus 1=0$. |
| 726 |
|
|
This allows the removal of pairs of identical values joined by |
| 727 |
|
|
$\oplus$, i.e. |
| 728 |
|
|
|
| 729 |
|
|
\begin{equation} |
| 730 |
|
|
\label{eq:cedc0:sfft0:dff0:02} |
| 731 |
|
|
1 \oplus 1 \oplus a \oplus b \oplus a \oplus b \oplus a \oplus b \oplus a = b. |
| 732 |
|
|
\end{equation} |
| 733 |
|
|
\end{enumerate} |
| 734 |
|
|
|
| 735 |
|
|
|
| 736 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 737 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 738 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 739 |
|
|
\subsection[Properties Of Matrices Consisting Of Elements \mbox{\protect$\in \mathbb{B}$}] |
| 740 |
|
|
{Properties Of Matrices Consisting Of Elements \mbox{\protect\boldmath$\in \mathbb{B}$}} |
| 741 |
|
|
%Subection tag: rmc0 |
| 742 |
|
|
\label{cedc0:sfft0:rmc0} |
| 743 |
|
|
|
| 744 |
|
|
In high school and college, most engineers studied linear algebra using |
| 745 |
|
|
matrices with elements $\in \vworkrealset$. The set of real numbers combined |
| 746 |
|
|
with the traditional addition and multiplication operators is |
| 747 |
|
|
an \emph{infinite} field, whereas the set $\mathbb{B} = \{ 0, 1 \}$ combined |
| 748 |
|
|
with the addition and multiplication operators as defined in |
| 749 |
|
|
Section \ref{cedc0:sfft0:dff0} is a \emph{finite} field, namely |
| 750 |
|
|
$GF(2)$. It may not be clear to a practicing engineer whether the traditional notions |
| 751 |
|
|
from linear algebra apply to the finite field $GF(2)$ as |
| 752 |
|
|
defined here. |
| 753 |
|
|
|
| 754 |
|
|
It ends up that all of the traditional notions from linear algebra |
| 755 |
|
|
\emph{do} apply to finite fields and to $GF(2)$. Most undergraduate linear |
| 756 |
|
|
algebra texts, however, do not develop this. By |
| 757 |
|
|
\emph{traditional notions} we mean: |
| 758 |
|
|
|
| 759 |
|
|
\begin{itemize} |
| 760 |
|
|
\item The notion of the rank of a matrix. |
| 761 |
|
|
\item The notion of the determinant of a matrix (denoted $|A|$ or $det(A)$). |
| 762 |
|
|
\item The equivalence of all of the following statements: |
| 763 |
|
|
\begin{itemize} |
| 764 |
|
|
\item $|A_{n \times n}| = 0$. |
| 765 |
|
|
\item $A$ is not of full rank. |
| 766 |
|
|
\item Any linear combination of the rows or columns of $A$ can span |
| 767 |
|
|
only a subspace of $\mathbb{B}^n$. |
| 768 |
|
|
\end{itemize} |
| 769 |
|
|
\end{itemize} |
| 770 |
|
|
|
| 771 |
|
|
The notion of subspace, however, has a subtly different flavor with a finite |
| 772 |
|
|
field because such a subspace has a finite and countable number of elements. |
| 773 |
|
|
With that in mind, we present the following lemma. |
| 774 |
|
|
|
| 775 |
|
|
\begin{vworklemmastatement} |
| 776 |
|
|
\label{lem:cedc0:sfft0:rmc0:01} |
| 777 |
|
|
Linear combinations of the |
| 778 |
|
|
rows or columns from an |
| 779 |
|
|
$m \times n$ matrix $A$ with elements from $\mathbb{B}$ and with |
| 780 |
|
|
rank $r$ can span exactly $2^r$ vectors. |
| 781 |
|
|
\end{vworklemmastatement} |
| 782 |
|
|
\begin{vworklemmaproof} |
| 783 |
|
|
For simplicity assume a square matrix $A_{n \times n}$ with rank |
| 784 |
|
|
$r \leq n$ (the result applies also to non-square matrices and to |
| 785 |
|
|
the columns as well as the rows). |
| 786 |
|
|
Denote the rows of $A$ as $r_0 \ldots r_{n-1}$. |
| 787 |
|
|
Sort the rows of the matrix so that $r_0 \ldots{} r_{r-1}$ are linearly |
| 788 |
|
|
independent and rows $r_{r} \ldots{} r_{n-1}$ are each linear combinations |
| 789 |
|
|
of $r_0 \ldots{} r_{r-1}$. |
| 790 |
|
|
|
| 791 |
|
|
Consider the $2^n$ linear combinations of the |
| 792 |
|
|
$n$ rows, with each linear combination of the |
| 793 |
|
|
form $\alpha_0 r_0 + \alpha_1 r_1 + \ldots{} + \alpha_{n-1} r_{n-1}$, |
| 794 |
|
|
where $\alpha_i \in \mathbb{B}$. For those linear combinations |
| 795 |
|
|
where there are nonzero $\alpha_{r} \ldots{} \alpha_{n-1}$, since |
| 796 |
|
|
each $r_{r} \ldots{} r_{n-1}$ is a linear combination of |
| 797 |
|
|
$r_0 \ldots{} r_{r-1}$, a substitution can be made to express the |
| 798 |
|
|
linear combination as a sum of $r_0 \ldots{} r_{r-1}$ only, and then |
| 799 |
|
|
superfluous terms can be removed in pairs |
| 800 |
|
|
(Property \ref{prop:enum:cedc0:sfft0:dff0:01:02}, p. \pageref{prop:enum:cedc0:sfft0:dff0:01:02}) |
| 801 |
|
|
to give a linear combination of $r_0 \ldots{} r_{r-1}$ only. |
| 802 |
|
|
Thus, every $\alpha_0 r_0 + \alpha_1 r_1 + \ldots{} + \alpha_{n-1} r_{n-1}$ |
| 803 |
|
|
can be simplified to $\alpha_0 r_0 + \alpha_1 r_1 + \ldots{} + \alpha_{r-1} r_{r-1}$. |
| 804 |
|
|
Since no row $r_0 \ldots r_{r-1}$ is a linear combination of other rows |
| 805 |
|
|
$r_0 \ldots r_{r-1}$, each of the $2^r$ linear combinations |
| 806 |
|
|
is unique and thus all linear combinations of the rows |
| 807 |
|
|
sum to one of $2^r$ distinct $1 \times n$ vector values. |
| 808 |
|
|
\end{vworklemmaproof} |
| 809 |
|
|
\vworklemmafooter{} |
| 810 |
|
|
|
| 811 |
|
|
The ability to directly apply concepts from linear algebra to matrices |
| 812 |
|
|
with elements $\in \mathbb{B}$ is in fact the reason for employing finite field |
| 813 |
|
|
theory. We illustrate the applicability of standard linear algebra concepts to these |
| 814 |
|
|
types of matrices with the following example. |
| 815 |
|
|
|
| 816 |
|
|
\begin{vworkexamplestatement} |
| 817 |
|
|
\label{ex:cedc0:sfft0:rmc0:01} |
| 818 |
|
|
Consider the two matrices $A$ and $B$ with elements $\in \mathbb{B}$: |
| 819 |
|
|
|
| 820 |
|
|
\begin{equation} |
| 821 |
|
|
\label{eq:cedc0:sfft0:rmc0:01} |
| 822 |
|
|
A = \left[\begin{array}{ccc}1&1&0\\0&1&1\\1&0&1\end{array}\right], \;\; |
| 823 |
|
|
B = \left[\begin{array}{ccc}1&1&0\\0&1&1\\0&0&1\end{array}\right]. |
| 824 |
|
|
\end{equation} |
| 825 |
|
|
|
| 826 |
|
|
Determine the rank of $A$ and $B$ and the set of $1 \times 3$ vectors |
| 827 |
|
|
which is spanned by linear combination of their rows. |
| 828 |
|
|
\end{vworkexamplestatement} |
| 829 |
|
|
\begin{vworkexampleparsection}{Solution} |
| 830 |
|
|
Recall that for a $3 \times 3$ matrix |
| 831 |
|
|
$\left[\begin{array}{ccc}a&b&c\\d&e&f\\g&h&i\end{array}\right]$, |
| 832 |
|
|
the determinant is given by |
| 833 |
|
|
$a(ei-hf) - b(di-gf) + c(dh - ge)$. However, with |
| 834 |
|
|
elements from $GF(2)$, addition and subtraction are the same |
| 835 |
|
|
operation (Property \ref{prop:enum:cedc0:sfft0:dff0:01:01}, p. \pageref{prop:enum:cedc0:sfft0:dff0:01:01}), |
| 836 |
|
|
so we can replace `-' and '+' both with `$\oplus$' to give the |
| 837 |
|
|
simpler expression |
| 838 |
|
|
$a(ei \oplus hf) \oplus b(di \oplus gf) \oplus c(dh \oplus ge)$. The |
| 839 |
|
|
determinants of $A$ and $B$ are thus |
| 840 |
|
|
|
| 841 |
|
|
\begin{eqnarray} |
| 842 |
|
|
\nonumber |
| 843 |
|
|
|A| & = & 1 (1 \cdot 1 \oplus 0 \cdot 1) \oplus |
| 844 |
|
|
1 (0 \cdot 1 \oplus 1 \cdot 1) \oplus |
| 845 |
|
|
0 (0 \cdot 0 \oplus 1 \cdot 1) \\ |
| 846 |
|
|
\label{eq:cedc0:sfft0:rmc0:02} |
| 847 |
|
|
& = & 1 (1 \oplus 0) \oplus 1 (0 \oplus 1) \oplus 0 (0 \oplus 1) \\ |
| 848 |
|
|
\nonumber |
| 849 |
|
|
& = & 1 \oplus 1 \oplus 0 = 0 |
| 850 |
|
|
\end{eqnarray} |
| 851 |
|
|
|
| 852 |
|
|
\noindent{}and |
| 853 |
|
|
|
| 854 |
|
|
\begin{eqnarray} |
| 855 |
|
|
\nonumber |
| 856 |
|
|
|B| & = & 1 (1 \cdot 1 \oplus 0 \cdot 1) \oplus |
| 857 |
|
|
1 (0 \cdot 1 \oplus 0 \cdot 1) \oplus |
| 858 |
|
|
0 (0 \cdot 1 \oplus 0 \cdot 1) \\ |
| 859 |
|
|
\label{eq:cedc0:sfft0:rmc0:03} |
| 860 |
|
|
& = & 1 (1 \oplus 0) \oplus 1 (0 \oplus 0) \oplus 0 (0 \oplus 0) \\ |
| 861 |
|
|
\nonumber |
| 862 |
|
|
& = & 1 \oplus 0 \oplus 0 = 1 . |
| 863 |
|
|
\end{eqnarray} |
| 864 |
|
|
|
| 865 |
|
|
From the determinants, it follows that $B$ is of full rank ($rank(B)=3$) but $A$ is not. |
| 866 |
|
|
In fact, |
| 867 |
|
|
it can be seen on inspection of $A$ that the third row is the sum of the first |
| 868 |
|
|
two rows ($rank(A) = 2$). |
| 869 |
|
|
|
| 870 |
|
|
To enumerate the space spanned by the rows of $A$ and $B$, one can form the sum |
| 871 |
|
|
$\alpha_0 r_0 \oplus \alpha_1 r_1 \oplus \alpha_2 r_2$ and vary the parameters |
| 872 |
|
|
$\alpha_0, \alpha_1, \alpha_2 \in \mathbb{B}$. |
| 873 |
|
|
Table \ref{tbl:cedc0:sfft0:rmc0:01} supplies this range for |
| 874 |
|
|
$A$ and Table \ref{tbl:cedc0:sfft0:rmc0:02} supplies this range |
| 875 |
|
|
for $B$. |
| 876 |
|
|
|
| 877 |
|
|
\begin{table} |
| 878 |
|
|
\caption{Range Of $\alpha_0 r_0 \oplus \alpha_1 r_1 \oplus \alpha_2 r_2$ For $A$ Of Example \ref{ex:cedc0:sfft0:rmc0:01}} |
| 879 |
|
|
\label{tbl:cedc0:sfft0:rmc0:01} |
| 880 |
|
|
\begin{center} |
| 881 |
|
|
\begin{tabular}{|c|c|c|l|} |
| 882 |
|
|
\hline |
| 883 |
|
|
$\alpha_0$ & $\alpha_1$ & $\alpha_2$ & $\alpha_0 [1 \; 1 \; 0] \oplus \alpha_1 [0 \; 1 \; 1] \oplus \alpha_2 [1 \; 0 \; 1]$ \\ |
| 884 |
|
|
\hline |
| 885 |
|
|
\hline |
| 886 |
|
|
0 & 0 & 0 & $[0\;0\;0]$ \\ |
| 887 |
|
|
\hline |
| 888 |
|
|
0 & 0 & 1 & $[1\;0\;1]$ \\ |
| 889 |
|
|
\hline |
| 890 |
|
|
0 & 1 & 0 & $[0\;1\;1]$ \\ |
| 891 |
|
|
\hline |
| 892 |
|
|
0 & 1 & 1 & $[0\;1\;1] \oplus [1\;0\;1]$ \\ |
| 893 |
|
|
& & & $[0 \oplus 1 \;\; 1 \oplus 0\;\; 1 \oplus 1]$ \\ |
| 894 |
|
|
& & & $[1\;1\;0]$ \\ |
| 895 |
|
|
\hline |
| 896 |
|
|
1 & 0 & 0 & $[1\;1\;0]$ \\ |
| 897 |
|
|
\hline |
| 898 |
|
|
1 & 0 & 1 & $[1\;1\;0] \oplus [1\;0\;1]$ \\ |
| 899 |
|
|
& & & $[1 \oplus 1 \;\; 1 \oplus 0\;\; 0 \oplus 1]$ \\ |
| 900 |
|
|
& & & $[0\;1\;1]$ \\ |
| 901 |
|
|
\hline |
| 902 |
|
|
1 & 1 & 0 & $[1\;1\;0] \oplus [0\;1\;1]$ \\ |
| 903 |
|
|
& & & $[1 \oplus 0 \;\; 1 \oplus 1\;\; 0 \oplus 1]$ \\ |
| 904 |
|
|
& & & $[1\;0\;1]$ \\ |
| 905 |
|
|
\hline |
| 906 |
|
|
1 & 1 & 1 & $[1\;1\;0] \oplus [0\;1\;1] \oplus [1\;0\;1]$ \\ |
| 907 |
|
|
& & & $[1 \oplus 0 \oplus 1 \;\; 1 \oplus 1 \oplus 0\;\; 0 \oplus 1 \oplus 1]$ \\ |
| 908 |
|
|
& & & $[0\;0\;0]$ \\ |
| 909 |
|
|
\hline |
| 910 |
|
|
\end{tabular} |
| 911 |
|
|
\end{center} |
| 912 |
|
|
\end{table} |
| 913 |
|
|
|
| 914 |
|
|
\begin{table} |
| 915 |
|
|
\caption{Range Of $\alpha_0 r_0 \oplus \alpha_1 r_1 \oplus \alpha_2 r_2$ For $B$ Of Example \ref{ex:cedc0:sfft0:rmc0:01}} |
| 916 |
|
|
\label{tbl:cedc0:sfft0:rmc0:02} |
| 917 |
|
|
\begin{center} |
| 918 |
|
|
\begin{tabular}{|c|c|c|l|} |
| 919 |
|
|
\hline |
| 920 |
|
|
$\alpha_0$ & $\alpha_1$ & $\alpha_2$ & $\alpha_0 [1 \; 1 \; 0] \oplus \alpha_1 [0 \; 1 \; 1] \oplus \alpha_2 [0 \; 0 \; 1]$ \\ |
| 921 |
|
|
\hline |
| 922 |
|
|
\hline |
| 923 |
|
|
0 & 0 & 0 & $[0\;0\;0]$ \\ |
| 924 |
|
|
\hline |
| 925 |
|
|
0 & 0 & 1 & $[0\;0\;1]$ \\ |
| 926 |
|
|
\hline |
| 927 |
|
|
0 & 1 & 0 & $[0\;1\;1]$ \\ |
| 928 |
|
|
\hline |
| 929 |
|
|
0 & 1 & 1 & $[0\;1\;1] \oplus [0\;0\;1]$ \\ |
| 930 |
|
|
& & & $[0 \oplus 0 \;\; 1 \oplus 0\;\; 1 \oplus 1]$ \\ |
| 931 |
|
|
& & & $[0\;1\;0]$ \\ |
| 932 |
|
|
\hline |
| 933 |
|
|
1 & 0 & 0 & $[1\;1\;0]$ \\ |
| 934 |
|
|
\hline |
| 935 |
|
|
1 & 0 & 1 & $[1\;1\;0] \oplus [0\;0\;1]$ \\ |
| 936 |
|
|
& & & $[1 \oplus 0 \;\; 1 \oplus 0\;\; 0 \oplus 1]$ \\ |
| 937 |
|
|
& & & $[1\;1\;1]$ \\ |
| 938 |
|
|
\hline |
| 939 |
|
|
1 & 1 & 0 & $[1\;1\;0] \oplus [0\;1\;1]$ \\ |
| 940 |
|
|
& & & $[1 \oplus 0 \;\; 1 \oplus 1\;\; 0 \oplus 1]$ \\ |
| 941 |
|
|
& & & $[1\;0\;1]$ \\ |
| 942 |
|
|
\hline |
| 943 |
|
|
1 & 1 & 1 & $[1\;1\;0] \oplus [0\;1\;1] \oplus [0\;0\;1]$ \\ |
| 944 |
|
|
& & & $[1 \oplus 0 \oplus 0 \;\; 1 \oplus 1 \oplus 0\;\; 0 \oplus 1 \oplus 1]$ \\ |
| 945 |
|
|
& & & $[1\;0\;0]$ \\ |
| 946 |
|
|
\hline |
| 947 |
|
|
\end{tabular} |
| 948 |
|
|
\end{center} |
| 949 |
|
|
\end{table} |
| 950 |
|
|
|
| 951 |
|
|
Note from the tables that the rows of $A$ span 4 vectors |
| 952 |
|
|
(000, 011, 101, and 110), which is consistent |
| 953 |
|
|
by Lemma \ref{lem:cedc0:sfft0:rmc0:01} with a matrix of rank 2. |
| 954 |
|
|
Note also that the rows of $B$ span the full space of |
| 955 |
|
|
$2^3$ vectors (000, 001, 010, 011, 100, 101, 110, and 111), which |
| 956 |
|
|
is consistent with a full-rank matrix. |
| 957 |
|
|
\end{vworkexampleparsection} |
| 958 |
|
|
\vworkexamplefooter{} |
| 959 |
|
|
|
| 960 |
|
|
|
| 961 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 962 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 963 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 964 |
|
|
\section[Combinatoric Observations] |
| 965 |
|
|
{Combinatoric Observations About \protect\mbox{\protect\boldmath$(n,k)$} Block Codes} |
| 966 |
|
|
%Section tag: cob0 |
| 967 |
|
|
\label{cedc0:scob0} |
| 968 |
|
|
|
| 969 |
|
|
A surprising number of observations about $(n,k)$ block codes can be made by |
| 970 |
|
|
simply considering combinatoric aspects of the codes. In Section |
| 971 |
|
|
\ref{cedc0:scon0:sccb0} and Figure \ref{fig:cedc0:scon0:sccb0:01} |
| 972 |
|
|
(p. \pageref{fig:cedc0:scon0:sccb0:01}), no assumptions about the function which |
| 973 |
|
|
maps from the $k$ data bits to the $n-k$ checksum bits (other than determinism) |
| 974 |
|
|
were made. Even with only the assumption of determinism, a large number of properties |
| 975 |
|
|
can be derived or deduced, and we do this here. In the following |
| 976 |
|
|
subsections, it may be necessary to make slightly stronger assumptions in order |
| 977 |
|
|
to derive properties. |
| 978 |
|
|
|
| 979 |
|
|
|
| 980 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 981 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 982 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 983 |
|
|
\subsection[Packing Spheres Of Radius \protect\mbox{\protect$\rho$}] |
| 984 |
|
|
{Surface Area And Volume Of Packing Spheres Of Radius \protect\mbox{\protect\boldmath$\rho$}} |
| 985 |
|
|
%Subsection tag: psr0 |
| 986 |
|
|
\label{cedc0:scob0:psr0} |
| 987 |
|
|
|
| 988 |
|
|
As discussed in Section \ref{cedc0:scon0:sccb0}, we are interested in constructing |
| 989 |
|
|
messages consisting of $n$ symbols from the binary alphabet |
| 990 |
|
|
|
| 991 |
|
|
\begin{equation} |
| 992 |
|
|
\label{eq:cedc0:scob0:psr0:01} |
| 993 |
|
|
\mathbb{B} = \{ 0, 1 \} , |
| 994 |
|
|
\end{equation} |
| 995 |
|
|
|
| 996 |
|
|
\noindent{}with $k$ symbols being arbitrarily chosen (data), and the remaining |
| 997 |
|
|
$n-k$ symbols being check bits. |
| 998 |
|
|
|
| 999 |
|
|
As mentioned in Section \ref{cedc0:scon0:secv0}, the minimum Hamming distance |
| 1000 |
|
|
$\hat{d}$ |
| 1001 |
|
|
of a |
| 1002 |
|
|
code is related to its error detection capability (Eq. \ref{eq:cedc0:scon0:secv0:01}) |
| 1003 |
|
|
and to its error correction capability (Eq. \ref{eq:cedc0:scon0:secv0:04}). |
| 1004 |
|
|
It is most natural to think of the minimum Hamming distance $\hat{d}$ of a code |
| 1005 |
|
|
in terms of disjoint packing spheres or radius $\rho$, where $\hat{d} = 2 \rho + 1$, |
| 1006 |
|
|
rather than considering Hamming distance directly. In this section, we |
| 1007 |
|
|
derive the surface area\footnote{To use \emph{surface area} in this way is perhaps |
| 1008 |
|
|
a mild abuse of nomenclature.} and volume of packing spheres. |
| 1009 |
|
|
|
| 1010 |
|
|
We define the surface area of a packing sphere of radius $\rho$ to be the |
| 1011 |
|
|
number of messages which are exactly at Hamming distance $\rho$ from a message |
| 1012 |
|
|
being considered. To say that a message $c_2$ is exactly at distance |
| 1013 |
|
|
$\rho$ from $c_1$ is equivalent to saying that the error vector has weight $\rho$. |
| 1014 |
|
|
|
| 1015 |
|
|
Thus, for an $(n,k)$ block code, the number of messages that are precisely |
| 1016 |
|
|
at a distance $\rho$ from another message is given by |
| 1017 |
|
|
|
| 1018 |
|
|
\begin{equation} |
| 1019 |
|
|
\label{eq:cedc0:scob0:psr0:02} |
| 1020 |
|
|
S(n, \rho ) = \left({\begin{array}{cc}n\\\rho\end{array}}\right) . |
| 1021 |
|
|
\end{equation} |
| 1022 |
|
|
|
| 1023 |
|
|
\noindent{}This formula comes directly from considering the |
| 1024 |
|
|
number of $n$-bit error vectors of weight $\rho$ that can be constructed. |
| 1025 |
|
|
|
| 1026 |
|
|
We define the volume of a packing sphere of radius $\rho$ to be the |
| 1027 |
|
|
number of messages which are at a distance $\rho$ or less from a |
| 1028 |
|
|
message being considered. This volume can be obtained by |
| 1029 |
|
|
simply summing the number of messages at distances |
| 1030 |
|
|
$0 \leq d \leq \rho$ from the message being considered: |
| 1031 |
|
|
|
| 1032 |
|
|
\begin{eqnarray} |
| 1033 |
|
|
\label{eq:cedc0:scob0:psr0:03} |
| 1034 |
|
|
V(n, \rho ) & = & \sum_{d=0}^{\rho} \left({\begin{array}{cc}n\\d\end{array}}\right) \\ |
| 1035 |
|
|
\nonumber |
| 1036 |
|
|
& = & 1 |
| 1037 |
|
|
+ \left({\begin{array}{cc}n\\1\end{array}}\right) |
| 1038 |
|
|
+ \left({\begin{array}{cc}n\\2\end{array}}\right) |
| 1039 |
|
|
+ \ldots{} |
| 1040 |
|
|
+ \left({\begin{array}{cc}n\\\rho\end{array}}\right) |
| 1041 |
|
|
\end{eqnarray} |
| 1042 |
|
|
|
| 1043 |
|
|
\noindent{}Note in (\ref{eq:cedc0:scob0:psr0:03}) |
| 1044 |
|
|
that $d=0$ is included because the messsage being considered |
| 1045 |
|
|
(at distance 0) is also within the sphere. Note also that there is no |
| 1046 |
|
|
way to simplify the summation in (\ref{eq:cedc0:scob0:psr0:03}). |
| 1047 |
|
|
|
| 1048 |
|
|
|
| 1049 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1050 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1051 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1052 |
|
|
\subsection[Relationship Between Number Of Check Bits |
| 1053 |
|
|
\protect\mbox{\protect$n-k$} |
| 1054 |
|
|
And Minimum Hamming |
| 1055 |
|
|
Distance \protect\mbox{\protect$\hat{d}$}] |
| 1056 |
|
|
{Relationship Between Number Of Check Bits |
| 1057 |
|
|
\protect\mbox{\protect\boldmath$n-k$} |
| 1058 |
|
|
And Minimum Hamming |
| 1059 |
|
|
Distance \protect\mbox{\protect\boldmath$\hat{d}$}} |
| 1060 |
|
|
%Subsection tag: rbc0 |
| 1061 |
|
|
\label{cedc0:scob0:rbc0} |
| 1062 |
|
|
|
| 1063 |
|
|
Given that we wish to reliably transmit or store $k$ data bits, |
| 1064 |
|
|
we are interested in discovering how much protection (in terms of the |
| 1065 |
|
|
minimum Hamming distance $\hat{d}$) we can purchase with $n-k$ check bits. |
| 1066 |
|
|
In this section, |
| 1067 |
|
|
we develop |
| 1068 |
|
|
fundamental limiting |
| 1069 |
|
|
relationships between $n$, $k$, and $\hat{d}$ for $(n,k)$ block codes. |
| 1070 |
|
|
|
| 1071 |
|
|
|
| 1072 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1073 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1074 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1075 |
|
|
\subsubsection{Absolute Upper Limit} |
| 1076 |
|
|
%Subsubsection tag: aul0 |
| 1077 |
|
|
\label{cedc0:scob0:rbc0:saul0} |
| 1078 |
|
|
|
| 1079 |
|
|
The \index{Singleton bound}Singleton bound (Lemma \ref{lem:cedc0:slco0:spcd0:03}) |
| 1080 |
|
|
can also be proved combinationally using the |
| 1081 |
|
|
pigeonhole principle. |
| 1082 |
|
|
|
| 1083 |
|
|
It is obvious combinationally that \emph{no code can detect more than |
| 1084 |
|
|
$n-k$ corruptions} (this is a restatement of the Singleton bound given in |
| 1085 |
|
|
Lemma \ref{lem:cedc0:slco0:spcd0:03}). To understand why this must be true, |
| 1086 |
|
|
choose $m = n-k+1$ bits among the $k$ data bits to vary. Note that there |
| 1087 |
|
|
are $2^m$ patterns for the $m$ data bits, but only $2^{n-k}$ patterns for the |
| 1088 |
|
|
$n-k$ check bits. Thus, by the pigeonhole principle, at least one pair of patterns among the |
| 1089 |
|
|
data bits maps to the same pattern among the check bits. Thus, we can generate two |
| 1090 |
|
|
codewords having the same check bits by varying $m$ of the $k$ data bits, and thus we can |
| 1091 |
|
|
change one codeword to another with $n-k+1$ corruptions. |
| 1092 |
|
|
|
| 1093 |
|
|
|
| 1094 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1095 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1096 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1097 |
|
|
\subsubsection{Hamming (Sphere-Packing) Bound} |
| 1098 |
|
|
%Subsubsection tag: hsp0 |
| 1099 |
|
|
\label{cedc0:scob0:rbc0:shsp0} |
| 1100 |
|
|
|
| 1101 |
|
|
The most obvious bound comes about by considering that for a code with a |
| 1102 |
|
|
minimum Hamming distance $\hat{d}$ (assumed odd), the $2^k$ packing spheres each with |
| 1103 |
|
|
volume $V(n, \rho = (\hat{d}-1)/2 )$ must ``fit'' in the space |
| 1104 |
|
|
of $2^n$ messages that can be formed. This immediately leads to the |
| 1105 |
|
|
constraint |
| 1106 |
|
|
|
| 1107 |
|
|
\begin{equation} |
| 1108 |
|
|
\label{eq:cedc0:scob0:rbc0:shsp0:01} |
| 1109 |
|
|
2^k V(n, \rho) \leq 2^n . |
| 1110 |
|
|
\end{equation} |
| 1111 |
|
|
|
| 1112 |
|
|
\noindent{}(\ref{eq:cedc0:scob0:rbc0:shsp0:01}) states that the number of codewords |
| 1113 |
|
|
($2^k$ of them, one for each possible combination of the $k$ data bits) multiplied |
| 1114 |
|
|
by the number of messages required to populate a packing sphere around each codeword |
| 1115 |
|
|
adequate to guarantee |
| 1116 |
|
|
the minimum Hammming distance must be less than the number of message patterns |
| 1117 |
|
|
available ($2^n$ of them, one for each possible combination of the $n$ message bits). |
| 1118 |
|
|
Note that (\ref{eq:cedc0:scob0:rbc0:shsp0:01}) is a necessary condition for the existence |
| 1119 |
|
|
of a code with |
| 1120 |
|
|
a minimum Hamming distance of $\hat{d} = 2 \rho + 1$, but not a sufficient condition. |
| 1121 |
|
|
|
| 1122 |
|
|
|
| 1123 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1124 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1125 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1126 |
|
|
\subsection{Linear Codes} |
| 1127 |
|
|
%Subection tag: lco0 |
| 1128 |
|
|
\label{cedc0:scon0:slco0} |
| 1129 |
|
|
|
| 1130 |
|
|
|
| 1131 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1132 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1133 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1134 |
|
|
\subsection{Burst Errors} |
| 1135 |
|
|
%Subection tag: bhe0 |
| 1136 |
|
|
\label{cedc0:scon0:sbhe0} |
| 1137 |
|
|
|
| 1138 |
|
|
Need to define burst error capability $d_B$ as the size of the frame |
| 1139 |
|
|
in which unlimited errors may occur. |
| 1140 |
|
|
|
| 1141 |
|
|
|
| 1142 |
|
|
|
| 1143 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1144 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1145 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1146 |
|
|
\subsection{Metrics Of Goodness} |
| 1147 |
|
|
%Subection tag: mgo0 |
| 1148 |
|
|
\label{cedc0:scon0:smgo0} |
| 1149 |
|
|
|
| 1150 |
|
|
Given multiple possible strategies for implementing an error-detecting |
| 1151 |
|
|
or error-correcting code, how does one decide that one strategy is |
| 1152 |
|
|
better than another? What are the characteristics of merit |
| 1153 |
|
|
(or metrics of goodness) which should be used to rate strategies? This |
| 1154 |
|
|
question is especially relevant to microcontroller work, where strategies may |
| 1155 |
|
|
be chosen for efficiency and so may have some benefits but may not |
| 1156 |
|
|
have all mathematical properties normally associated with error detecting |
| 1157 |
|
|
and error correcting codes. |
| 1158 |
|
|
|
| 1159 |
|
|
We propose the following metrics of goodness for error detection and correction |
| 1160 |
|
|
strategies. |
| 1161 |
|
|
|
| 1162 |
|
|
\begin{enumerate} |
| 1163 |
|
|
\item \label{enum:cedc0:scon0:smgo0:01:01} |
| 1164 |
|
|
\textbf{Execution Time:} |
| 1165 |
|
|
Particularly for ROM checksum strategies that execute at product startup |
| 1166 |
|
|
or protect large blocks of data, execution time is critical. We |
| 1167 |
|
|
accept the TMS370C8 with a 12Mhz crystal as |
| 1168 |
|
|
a protypical inexpensive microcontroller, and |
| 1169 |
|
|
we express execution time as a linear model with offset. If |
| 1170 |
|
|
$m$ is the number of bytes to be protected (including the |
| 1171 |
|
|
checksum), we parameterize the performance by $t_s$ and $t_d$ so that |
| 1172 |
|
|
the time $t_{EX}$ to calculate the checksum is given by |
| 1173 |
|
|
|
| 1174 |
|
|
\begin{equation} |
| 1175 |
|
|
\label{eq:cedc0:scon0:smgo0:01} |
| 1176 |
|
|
t_{EX} = t_s + m t_d . |
| 1177 |
|
|
\end{equation} |
| 1178 |
|
|
|
| 1179 |
|
|
The parameter $t_s$ is included to properly characterize algorithms that have |
| 1180 |
|
|
a large setup or cleanup time. Note also that any differences between |
| 1181 |
|
|
algorithms in the size |
| 1182 |
|
|
of the checksum are accounted for by defining $m$ to include the checksum and |
| 1183 |
|
|
suitably adjusting $t_s$ (however, note that any such adjustments will be |
| 1184 |
|
|
\emph{very} small, as the checksum is typically very small in relation to the |
| 1185 |
|
|
data being protected). |
| 1186 |
|
|
|
| 1187 |
|
|
\item \label{enum:cedc0:scon0:smgo0:01:02} |
| 1188 |
|
|
\textbf{Minimum Hamming Distance \mbox{\boldmath$\hat{d}$} Of The Code:} |
| 1189 |
|
|
This is a very useful metric, and a larger $\hat{d}$ is better. However, |
| 1190 |
|
|
this metric can be misleading, and so the metric immediately below is also |
| 1191 |
|
|
applied. |
| 1192 |
|
|
|
| 1193 |
|
|
\item \label{enum:cedc0:scon0:smgo0:01:03} |
| 1194 |
|
|
\textbf{Probability Of Undetected Corruption As A Function Of \mbox{\boldmath$p$}:} |
| 1195 |
|
|
In microcontroller work, the minimum Hamming distance $\hat{d}$ of a |
| 1196 |
|
|
code may not give a complete metric for evaluation. For example, it |
| 1197 |
|
|
may be possible in practice to devise an efficient code such that nearly all |
| 1198 |
|
|
codewords are separated by a large Hamming distance but a small fraction |
| 1199 |
|
|
of codewords are separated by a small Hamming distance. In such a case, |
| 1200 |
|
|
the minimum Hamming distance $\hat{d}$ may not reflect the actual goodness |
| 1201 |
|
|
of the code. We are very interested in the actual probabilities of undetected |
| 1202 |
|
|
corruption as a function of $p$ when random bits are chosen to corrupt. |
| 1203 |
|
|
|
| 1204 |
|
|
\item \label{enum:cedc0:scon0:smgo0:01:04} |
| 1205 |
|
|
\textbf{Applicability Of The Code As An Error-Correcting Code:} |
| 1206 |
|
|
A code with a minimum Hamming distance $\hat{d}$ of at least 3 can be harnessed as |
| 1207 |
|
|
an error-correcting code. However, the cost of the decoding step needs to be |
| 1208 |
|
|
considered. Two questions are of interest: |
| 1209 |
|
|
|
| 1210 |
|
|
\begin{enumerate} |
| 1211 |
|
|
\item \textbf{Is a practical algorithm known for decoding (i.e. for mapping from the |
| 1212 |
|
|
message received to the nearest codeword)?} It may be possible to devise codes |
| 1213 |
|
|
with $\hat{d} \geq 3$ that are not practical to decode. |
| 1214 |
|
|
\item \textbf{What is the cost of this algorithm?} The cost would be parameterized |
| 1215 |
|
|
as in (\ref{eq:cedc0:scon0:smgo0:01}). |
| 1216 |
|
|
\end{enumerate} |
| 1217 |
|
|
\end{enumerate} |
| 1218 |
|
|
|
| 1219 |
|
|
|
| 1220 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1221 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1222 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1223 |
|
|
\section{Linear Codes} |
| 1224 |
|
|
%Section tag: lco0 |
| 1225 |
|
|
\label{cedc0:slco0} |
| 1226 |
|
|
|
| 1227 |
|
|
|
| 1228 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1229 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1230 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1231 |
|
|
\subsection{Definition} |
| 1232 |
|
|
\label{cedc0:slco0:sdef0} |
| 1233 |
|
|
|
| 1234 |
|
|
A linear code is simply a subspace of $\mathbb{B}^n$. In this definition, |
| 1235 |
|
|
by \emph{subspace} we mean subspace in the conventional linear algebra |
| 1236 |
|
|
sense where the subspace is spanned by linear combinations of a set of vectors, |
| 1237 |
|
|
and we operate within the finite field $GF(2)$ for each vector or matrix element. |
| 1238 |
|
|
|
| 1239 |
|
|
As an example of a linear code, consider the $(5,3)$ block code consisting |
| 1240 |
|
|
of vectors of the form $[a\;b\;c\;d\;e]$ where $d = a \oplus b$ and |
| 1241 |
|
|
$e = b \oplus c$. Such a code can be characterized by a generator |
| 1242 |
|
|
matrix |
| 1243 |
|
|
|
| 1244 |
|
|
\begin{equation} |
| 1245 |
|
|
\label{eq:cedc0:slco0:sdef0:01} |
| 1246 |
|
|
G = \left[ |
| 1247 |
|
|
\begin{array}{ccccc} |
| 1248 |
|
|
1&0&0&1&0 \\ |
| 1249 |
|
|
0&1&0&1&1 \\ |
| 1250 |
|
|
0&0&1&0&1 |
| 1251 |
|
|
\end{array} |
| 1252 |
|
|
\right] |
| 1253 |
|
|
\end{equation} |
| 1254 |
|
|
|
| 1255 |
|
|
\noindent{}where any codeword in the code is a linear combination of the rows |
| 1256 |
|
|
of $G$. |
| 1257 |
|
|
|
| 1258 |
|
|
We can calculate all of the codewords in the code defined by $G$ by |
| 1259 |
|
|
forming all of the linear combinations of the rows of $G$. |
| 1260 |
|
|
A linear combination of the rows of $G$ is of the form |
| 1261 |
|
|
|
| 1262 |
|
|
\begin{equation} |
| 1263 |
|
|
\label{eq:cedc0:slco0:sdef0:02} |
| 1264 |
|
|
\alpha_0 [1\;0\;0\;1\;0] |
| 1265 |
|
|
\oplus |
| 1266 |
|
|
\alpha_1 [0\;1\;0\;1\;1] |
| 1267 |
|
|
\oplus |
| 1268 |
|
|
\alpha_2 [0\;0\;1\;0\;1], |
| 1269 |
|
|
\end{equation} |
| 1270 |
|
|
|
| 1271 |
|
|
\noindent{}where $\alpha_0, \alpha_1, \alpha_2 \in \mathbb{B}$. |
| 1272 |
|
|
It can be verified that the codewords formed by varying |
| 1273 |
|
|
$\alpha_0, \alpha_1, \alpha_2$ in (\ref{eq:cedc0:slco0:sdef0:02}) |
| 1274 |
|
|
are 00000, 00101, 01011, 01110, 10010, 10111, 11001, and 11100. |
| 1275 |
|
|
|
| 1276 |
|
|
There are many properties of linear codes that follow immediately |
| 1277 |
|
|
from the definition of a linear code as a subspace. However, we |
| 1278 |
|
|
delay introducing these properties until Section \ref{cedc0:slco0:splc0}, |
| 1279 |
|
|
until after the parity check matrix (Section \ref{cedc0:slco0:spcm0}) and the |
| 1280 |
|
|
generator matrix (Section \ref{cedc0:slco0:sgma0}) have been introduced. |
| 1281 |
|
|
|
| 1282 |
|
|
|
| 1283 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1284 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1285 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1286 |
|
|
\subsection{The Parity Check Matrix} |
| 1287 |
|
|
\label{cedc0:slco0:spcm0} |
| 1288 |
|
|
|
| 1289 |
|
|
Any linear code can be characterized by a |
| 1290 |
|
|
\index{parity check matrix}\emph{parity check matrix} $H$ such that |
| 1291 |
|
|
for any codeword $m = [m_0, m_1, \ldots{}, m_{n-1}]$ in the |
| 1292 |
|
|
code, |
| 1293 |
|
|
|
| 1294 |
|
|
\begin{equation} |
| 1295 |
|
|
\label{eq:cedc0:slco0:spcm0:01} |
| 1296 |
|
|
H m^T = \mathbf{0} . |
| 1297 |
|
|
\end{equation} |
| 1298 |
|
|
|
| 1299 |
|
|
\noindent{}More explicitly, we may write (\ref{eq:cedc0:slco0:spcm0:01}) |
| 1300 |
|
|
as |
| 1301 |
|
|
|
| 1302 |
|
|
\begin{equation} |
| 1303 |
|
|
\label{eq:cedc0:slco0:spcm0:02} |
| 1304 |
|
|
\left[\begin{array}{llcl} |
| 1305 |
|
|
h_{0,0} & h_{0,1} & \cdots{} & h_{0,n-1} \\ |
| 1306 |
|
|
h_{1,0} & h_{1,1} & \cdots{} & h_{1,n-1} \\ |
| 1307 |
|
|
\;\;\vdots & \;\;\vdots & \ddots{} & \;\;\vdots \\ |
| 1308 |
|
|
h_{n-k-1,0} & h_{n-k-1,1} & \cdots{} & h_{n-k-1,n-1} \\ |
| 1309 |
|
|
\end{array}\right] |
| 1310 |
|
|
\left[\begin{array}{l}m_0\\m_1\\\;\;\vdots{}\\m_{n-1}\end{array}\right] |
| 1311 |
|
|
= \left[\begin{array}{c}0\\0\\\vdots{}\\0\end{array}\right] |
| 1312 |
|
|
\end{equation} |
| 1313 |
|
|
|
| 1314 |
|
|
\noindent{}where of course |
| 1315 |
|
|
|
| 1316 |
|
|
\begin{equation} |
| 1317 |
|
|
\label{eq:cedc0:slco0:spcm0:03} |
| 1318 |
|
|
H = \left[\begin{array}{llcl} |
| 1319 |
|
|
h_{0,0} & h_{0,1} & \cdots{} & h_{0,n-1} \\ |
| 1320 |
|
|
h_{1,0} & h_{1,1} & \cdots{} & h_{1,n-1} \\ |
| 1321 |
|
|
\;\;\vdots & \;\;\vdots & \ddots{} & \;\;\vdots \\ |
| 1322 |
|
|
h_{n-k-1,0} & h_{n-k-1,1} & \cdots{} & h_{n-k-1,n-1} \\ |
| 1323 |
|
|
\end{array}\right] |
| 1324 |
|
|
\end{equation} |
| 1325 |
|
|
|
| 1326 |
|
|
\noindent{}and |
| 1327 |
|
|
|
| 1328 |
|
|
\begin{equation} |
| 1329 |
|
|
\label{eq:cedc0:slco0:spcm0:04} |
| 1330 |
|
|
m^T = |
| 1331 |
|
|
\left[\begin{array}{l}m_0\\m_1\\\;\;\vdots{}\\m_{n-1}\end{array}\right] . |
| 1332 |
|
|
\end{equation} |
| 1333 |
|
|
|
| 1334 |
|
|
Note that $H$ has the same number of columns as message bits and |
| 1335 |
|
|
the same number of rows as check bits. |
| 1336 |
|
|
|
| 1337 |
|
|
Each row of $H$ specifies a required relationship between two or more |
| 1338 |
|
|
message bits. In the case of (\ref{eq:cedc0:slco0:spcm0:02}), these |
| 1339 |
|
|
$n-k$ relationships are |
| 1340 |
|
|
|
| 1341 |
|
|
\begin{eqnarray} |
| 1342 |
|
|
\nonumber h_{0,0} m_{0} + h_{0,1} m_{1} + \cdots{} h_{0,n-1} m_{n-1} & = & 0 \\ |
| 1343 |
|
|
\label{eq:cedc0:slco0:spcm0:05} |
| 1344 |
|
|
h_{1,0} m_{1} + h_{1,1} m_{1} + \cdots{} h_{1,n-1} m_{n-1} & = & 0 \\ |
| 1345 |
|
|
\nonumber & \vdots & \\ |
| 1346 |
|
|
\nonumber h_{n-k-1,0} m_{0} + h_{n-k-1,1} m_{1} + \cdots{} h_{n-k-1,n-1} m_{n-1} & = & 0 |
| 1347 |
|
|
\end{eqnarray} |
| 1348 |
|
|
|
| 1349 |
|
|
In the general case $H$ is arbitrary except that each row must |
| 1350 |
|
|
have at least two non-zero elements. However, because we are |
| 1351 |
|
|
interested only in codes where the check bits are concatenated |
| 1352 |
|
|
to the data bits (see Section \ref{cedc0:scon0:sccb0} and Figure |
| 1353 |
|
|
\ref{fig:cedc0:scon0:sccb0:01}), it is immediately |
| 1354 |
|
|
apparent that each row of $H$ must have at least one non-zero entry |
| 1355 |
|
|
in columns $n-k$ through $n-1$. If this condition were not met, $H$ would |
| 1356 |
|
|
specify a required |
| 1357 |
|
|
relationship between the $k$ data bits, which would mean that the $k$ data bits |
| 1358 |
|
|
could not be chosen freely. |
| 1359 |
|
|
|
| 1360 |
|
|
For the case where $n-k$ check bits are appended to $k$ data bits, we |
| 1361 |
|
|
seek to describe the code by a parity check matrix $H$ where the |
| 1362 |
|
|
rightmost $n-k$ columns are the identity matrix. If $H$ is arranged in this |
| 1363 |
|
|
way, each row of $H$ defines one of the $n-k$ check bits in terms of the $k$ data bits. |
| 1364 |
|
|
In other words, we generally seek to write $H$ as a concatenated matrix |
| 1365 |
|
|
|
| 1366 |
|
|
\begin{equation} |
| 1367 |
|
|
\label{eq:cedc0:slco0:spcm0:06} |
| 1368 |
|
|
H_{n-k \times n} = [H'_{n-k \times k} | I_{n-k \times n-k} ], |
| 1369 |
|
|
\end{equation} |
| 1370 |
|
|
|
| 1371 |
|
|
\noindent{}where the subscripts provide the dimensions of the matrices. |
| 1372 |
|
|
If $H$ is not arranged in this way, it can be arranged in this way by elementary |
| 1373 |
|
|
row operations. |
| 1374 |
|
|
|
| 1375 |
|
|
We illustrate the application of the a parity generation matrix $H$ with the following |
| 1376 |
|
|
example. |
| 1377 |
|
|
|
| 1378 |
|
|
\begin{vworkexamplestatement} |
| 1379 |
|
|
\label{ex:cedc0:slco0:spcm0:01} |
| 1380 |
|
|
For a $(7,4)$ code where each message is a row vector |
| 1381 |
|
|
|
| 1382 |
|
|
\begin{equation} |
| 1383 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:01} |
| 1384 |
|
|
[ d_0 \; d_1 \; d_2 \; d_3 \; c_0 \; c_1 \; c_2 ] |
| 1385 |
|
|
\end{equation} |
| 1386 |
|
|
|
| 1387 |
|
|
\noindent{}and where the parity check matrix is |
| 1388 |
|
|
|
| 1389 |
|
|
\begin{equation} |
| 1390 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:02} |
| 1391 |
|
|
H = \left[\begin{array}{ccccccc} |
| 1392 |
|
|
1 & 1 & 0 & 1 & 1 & 0 & 0 \\ |
| 1393 |
|
|
1 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 1394 |
|
|
0 & 1 & 1 & 1 & 0 & 0 & 1 |
| 1395 |
|
|
\end{array}\right], |
| 1396 |
|
|
\end{equation} |
| 1397 |
|
|
|
| 1398 |
|
|
\noindent{}find expressions for the check bits $c_0$, $c_1$, and $c_2$; and |
| 1399 |
|
|
enumerate the complete code. |
| 1400 |
|
|
\end{vworkexamplestatement} |
| 1401 |
|
|
\begin{vworkexampleparsection}{Solution} |
| 1402 |
|
|
Note that $H$ is already conditioned so that the rightmost $n-k$ columns |
| 1403 |
|
|
are the identity matrix. By the definition provided by |
| 1404 |
|
|
(\ref{eq:cedc0:slco0:spcm0:06}), |
| 1405 |
|
|
|
| 1406 |
|
|
\begin{equation} |
| 1407 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:02b} |
| 1408 |
|
|
H'_{(n-k \times k) = (3 \times 4)} = \left[\begin{array}{cccc} |
| 1409 |
|
|
1 & 1 & 0 & 1 \\ |
| 1410 |
|
|
1 & 0 & 1 & 1 \\ |
| 1411 |
|
|
0 & 1 & 1 & 1 |
| 1412 |
|
|
\end{array}\right] |
| 1413 |
|
|
\end{equation} |
| 1414 |
|
|
|
| 1415 |
|
|
\noindent{}and |
| 1416 |
|
|
|
| 1417 |
|
|
\begin{equation} |
| 1418 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:02c} |
| 1419 |
|
|
I_{(n-k \times n-k) = (3 \times 3)}= \left[\begin{array}{ccc} |
| 1420 |
|
|
1 & 0 & 0 \\ |
| 1421 |
|
|
0 & 1 & 0 \\ |
| 1422 |
|
|
0 & 0 & 1 |
| 1423 |
|
|
\end{array}\right]. |
| 1424 |
|
|
\end{equation} |
| 1425 |
|
|
|
| 1426 |
|
|
Applying (\ref{eq:cedc0:slco0:spcm0:01}) yields |
| 1427 |
|
|
|
| 1428 |
|
|
\begin{equation} |
| 1429 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:03} |
| 1430 |
|
|
\left[\begin{array}{ccccccc} |
| 1431 |
|
|
1 & 1 & 0 & 1 & 1 & 0 & 0 \\ |
| 1432 |
|
|
1 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 1433 |
|
|
0 & 1 & 1 & 1 & 0 & 0 & 1 |
| 1434 |
|
|
\end{array}\right] |
| 1435 |
|
|
\left[\begin{array}{c}d_0\\d_1\\d_2\\d_3\\c_0\\c_1\\c_2\end{array}\right] = |
| 1436 |
|
|
\left[\begin{array}{c}0\\0\\0\\0\\0\\0\\0\end{array}\right] , |
| 1437 |
|
|
\end{equation} |
| 1438 |
|
|
|
| 1439 |
|
|
\noindent{}or equivalently the system of equations |
| 1440 |
|
|
|
| 1441 |
|
|
\begin{eqnarray} |
| 1442 |
|
|
\nonumber |
| 1443 |
|
|
d_0 \oplus d_1 \oplus d_3 \oplus c_0 & = & 0 \\ |
| 1444 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:05} |
| 1445 |
|
|
d_0 \oplus d_2 \oplus d_3 \oplus c_1 & = & 0 \\ |
| 1446 |
|
|
\nonumber |
| 1447 |
|
|
d_1 \oplus d_2 \oplus d_3 \oplus c_2 & = & 0 . |
| 1448 |
|
|
\end{eqnarray} |
| 1449 |
|
|
|
| 1450 |
|
|
\noindent{}The system of equations (\ref{eq:ex:cedc0:slco0:spcm0:01:05}) |
| 1451 |
|
|
can be solved for $c_0$, $c_1$, and $c_2$ by using |
| 1452 |
|
|
Property \ref{prop:cedc0:scon0:sxor0:01:04} |
| 1453 |
|
|
from Section \ref{cedc0:scon0:sxor0}, which allows $c_0$, $c_1$ and $c_2$ to |
| 1454 |
|
|
be moved to the other side of the equations in (\ref{eq:ex:cedc0:slco0:spcm0:01:05}), |
| 1455 |
|
|
yielding |
| 1456 |
|
|
|
| 1457 |
|
|
\begin{eqnarray} |
| 1458 |
|
|
\nonumber |
| 1459 |
|
|
c_0 & = & d_0 \oplus d_1 \oplus d_3 \\ |
| 1460 |
|
|
\label{eq:ex:cedc0:slco0:spcm0:01:08} |
| 1461 |
|
|
c_1 & = & d_0 \oplus d_2 \oplus d_3 \\ |
| 1462 |
|
|
\nonumber |
| 1463 |
|
|
c_2 & = & d_1 \oplus d_2 \oplus d_3 . |
| 1464 |
|
|
\end{eqnarray} |
| 1465 |
|
|
|
| 1466 |
|
|
The full code can be enumerated by listing all $2^k = 2^4 = 16$ combinations of |
| 1467 |
|
|
the data bits $d_0\ldots{}d_3$ and then applying (\ref{eq:ex:cedc0:slco0:spcm0:01:08}) |
| 1468 |
|
|
to obtain $c_0$, $c_1$, and $c_2$. Table \ref{tbl:ex:cedc0:slco0:spcm0:01:01} |
| 1469 |
|
|
supplies the full code obtained in this way. |
| 1470 |
|
|
|
| 1471 |
|
|
\begin{table} |
| 1472 |
|
|
\caption{Fully Enumerated (7,4) Code (Solution To Example \ref{ex:cedc0:slco0:spcm0:01})} |
| 1473 |
|
|
\label{tbl:ex:cedc0:slco0:spcm0:01:01} |
| 1474 |
|
|
\begin{center} |
| 1475 |
|
|
\begin{tabular}{|c|c|c|c|c|c|c|} |
| 1476 |
|
|
\hline |
| 1477 |
|
|
$d_0$ & $d_1$ & $d_2$ & $d_3$ & $c_0$ & $c_1$ & $c_2$ \\ |
| 1478 |
|
|
& & & & $=d_0 \oplus d_1 \oplus d_3$ & $=d_0 \oplus d_2 \oplus d_3$ & $=d_1 \oplus d_2 \oplus d_3$ \\ |
| 1479 |
|
|
\hline |
| 1480 |
|
|
\hline |
| 1481 |
|
|
0 & 0 & 0 & 0 & 0 & 0 & 0 \\ |
| 1482 |
|
|
\hline |
| 1483 |
|
|
0 & 0 & 0 & 1 & 1 & 1 & 0 \\ |
| 1484 |
|
|
\hline |
| 1485 |
|
|
0 & 0 & 1 & 0 & 0 & 1 & 1 \\ |
| 1486 |
|
|
\hline |
| 1487 |
|
|
0 & 0 & 1 & 1 & 1 & 0 & 1 \\ |
| 1488 |
|
|
\hline |
| 1489 |
|
|
0 & 1 & 0 & 0 & 1 & 0 & 1 \\ |
| 1490 |
|
|
\hline |
| 1491 |
|
|
0 & 1 & 0 & 1 & 0 & 1 & 1 \\ |
| 1492 |
|
|
\hline |
| 1493 |
|
|
0 & 1 & 1 & 0 & 1 & 1 & 0 \\ |
| 1494 |
|
|
\hline |
| 1495 |
|
|
0 & 1 & 1 & 1 & 0 & 0 & 0 \\ |
| 1496 |
|
|
\hline |
| 1497 |
|
|
1 & 0 & 0 & 0 & 1 & 1 & 1 \\ |
| 1498 |
|
|
\hline |
| 1499 |
|
|
1 & 0 & 0 & 1 & 0 & 0 & 1 \\ |
| 1500 |
|
|
\hline |
| 1501 |
|
|
1 & 0 & 1 & 0 & 1 & 0 & 0 \\ |
| 1502 |
|
|
\hline |
| 1503 |
|
|
1 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 1504 |
|
|
\hline |
| 1505 |
|
|
1 & 1 & 0 & 0 & 0 & 1 & 0 \\ |
| 1506 |
|
|
\hline |
| 1507 |
|
|
1 & 1 & 0 & 1 & 1 & 0 & 0 \\ |
| 1508 |
|
|
\hline |
| 1509 |
|
|
1 & 1 & 1 & 0 & 0 & 0 & 1 \\ |
| 1510 |
|
|
\hline |
| 1511 |
|
|
1 & 1 & 1 & 1 & 1 & 1 & 1 \\ |
| 1512 |
|
|
\hline |
| 1513 |
|
|
\end{tabular} |
| 1514 |
|
|
\end{center} |
| 1515 |
|
|
\end{table} |
| 1516 |
|
|
\end{vworkexampleparsection} |
| 1517 |
|
|
\vworkexamplefooter{} |
| 1518 |
|
|
|
| 1519 |
|
|
In the first paragraph of this section, we made the claim that \emph{any} linear |
| 1520 |
|
|
code can be represented by a parity check matrix. We substantiate that |
| 1521 |
|
|
claim with the following lemma. |
| 1522 |
|
|
|
| 1523 |
|
|
\begin{vworklemmastatement} |
| 1524 |
|
|
\label{lem:cedc0:slco0:spcm0:01} |
| 1525 |
|
|
Every linear code can be represented by a parity check matrix, and every |
| 1526 |
|
|
parity check matrix defines a linear code. |
| 1527 |
|
|
\end{vworklemmastatement} |
| 1528 |
|
|
\begin{vworklemmaproof} |
| 1529 |
|
|
We first prove that a code $C$ specified by a parity check matrix $H$ |
| 1530 |
|
|
is a linear code. Note that $\mathbf{0} \in C$ (which is required for a linear code), |
| 1531 |
|
|
since $H \mathbf{0}^T = \mathbf{0}$. If $m_1 \in C$ and $m_2 \in C$, then |
| 1532 |
|
|
by definition $H m_1^T = H m_2^T = \mathbf{0}$. It can be shown by linearity |
| 1533 |
|
|
that $H (m_3^T = (m_1 + m_2)^T) = \mathbf{0}$, and thus $m_3 \in C$. |
| 1534 |
|
|
|
| 1535 |
|
|
We then prove the implication in the other direction; that any linear code must be |
| 1536 |
|
|
describable by a parity matrix $H$. Although this is true in the general |
| 1537 |
|
|
case, we prove it only for the case of the type of code involving |
| 1538 |
|
|
$n-k$ check bits appended to $k$ data bits, as described in |
| 1539 |
|
|
Section \ref{cedc0:scon0:sccb0} and Figure |
| 1540 |
|
|
\ref{fig:cedc0:scon0:sccb0:01}. This type of code contains a codeword |
| 1541 |
|
|
for all possible values of the data bits $d_0 \ldots d_{k-1}$. We |
| 1542 |
|
|
consider only those codewords which have a single data bit set. Figure |
| 1543 |
|
|
\ref{tbl:lem:cedc0:slco0:spcm0:01:01} enumerates such codewords extracted |
| 1544 |
|
|
from Example \ref{ex:cedc0:slco0:spcm0:01} and Figure |
| 1545 |
|
|
\ref{tbl:ex:cedc0:slco0:spcm0:01:01}. |
| 1546 |
|
|
|
| 1547 |
|
|
\begin{table} |
| 1548 |
|
|
\caption{Codewords From Example \ref{ex:cedc0:slco0:spcm0:01} With Only A Single Data Bit Set} |
| 1549 |
|
|
\label{tbl:lem:cedc0:slco0:spcm0:01:01} |
| 1550 |
|
|
\begin{center} |
| 1551 |
|
|
\begin{tabular}{|c|c|c|c|c|c|c|} |
| 1552 |
|
|
\hline |
| 1553 |
|
|
$d_0$ & $d_1$ & $d_2$ & $d_3$ & $c_0$ & $c_1$ & $c_2$ \\ |
| 1554 |
|
|
\hline |
| 1555 |
|
|
\hline |
| 1556 |
|
|
1 & 0 & 0 & 0 & 1 & 1 & 1 \\ |
| 1557 |
|
|
\hline |
| 1558 |
|
|
0 & 1 & 0 & 0 & 1 & 0 & 1 \\ |
| 1559 |
|
|
\hline |
| 1560 |
|
|
0 & 0 & 1 & 0 & 0 & 1 & 1 \\ |
| 1561 |
|
|
\hline |
| 1562 |
|
|
0 & 0 & 0 & 1 & 1 & 1 & 0 \\ |
| 1563 |
|
|
\hline |
| 1564 |
|
|
\end{tabular} |
| 1565 |
|
|
\end{center} |
| 1566 |
|
|
\end{table} |
| 1567 |
|
|
|
| 1568 |
|
|
Because of the linearity of the code, we are able to construct any |
| 1569 |
|
|
codeword of the code from a set of codewords such as are |
| 1570 |
|
|
shown in Table \ref{tbl:lem:cedc0:slco0:spcm0:01:01}. Given |
| 1571 |
|
|
any four data bits $d_0 \ldots d_3$, we form the codeword |
| 1572 |
|
|
by adding together the rows corresponding to the 1's in the |
| 1573 |
|
|
data. For example, to form the codeword corresponding to |
| 1574 |
|
|
$[d_0 d_1 d_2 d_3]$ $=$ $[1010]$, we would simply XOR together |
| 1575 |
|
|
the the first and third rows from Table \ref{tbl:lem:cedc0:slco0:spcm0:01:01}: |
| 1576 |
|
|
$[1000111] \oplus [0010011] = [1010100]$. |
| 1577 |
|
|
|
| 1578 |
|
|
However, the structure of Table \ref{tbl:lem:cedc0:slco0:spcm0:01:01} |
| 1579 |
|
|
gives us somewhat more information about the structure of a parity |
| 1580 |
|
|
generation matrix $H$. In the first row, with only $d_0$ set to 1, |
| 1581 |
|
|
$c_0$, $c_1$, and $c_2$ are all 1: this indicates that $d_0$ must appear in the |
| 1582 |
|
|
parity equations for $c_0$, $c_1$, and $c_2$. Similarly, the second row indicates |
| 1583 |
|
|
that $d_1$ appears in the parity equations for $c_0$ and $c_2$ only. |
| 1584 |
|
|
One can thus derive (\ref{eq:ex:cedc0:slco0:spcm0:01:08}) directly |
| 1585 |
|
|
from examining the last three columns of Table \ref{tbl:lem:cedc0:slco0:spcm0:01:01}. |
| 1586 |
|
|
Using the observations above, a parity check matrix which provides data consistent |
| 1587 |
|
|
with Table \ref{tbl:lem:cedc0:slco0:spcm0:01:01} can be constructed. Since |
| 1588 |
|
|
the code being considered and the code formed by the parity check matrix |
| 1589 |
|
|
constructed as described above are both linear, it follows that the two codes |
| 1590 |
|
|
are identical. Thus, using the procedure described above, |
| 1591 |
|
|
a parity check matrix can be constructed for any linear code consisting of |
| 1592 |
|
|
$n-k$ check bits appended to $k$ data bits. |
| 1593 |
|
|
\end{vworklemmaproof} |
| 1594 |
|
|
\vworklemmafooter{} |
| 1595 |
|
|
|
| 1596 |
|
|
|
| 1597 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1598 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1599 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1600 |
|
|
\subsection{The Generator Matrix} |
| 1601 |
|
|
\label{cedc0:slco0:sgma0} |
| 1602 |
|
|
|
| 1603 |
|
|
A second characterization of a linear code is |
| 1604 |
|
|
by a \index{generator matrix}generator matrix. A generator matrix is |
| 1605 |
|
|
a set of codewords chosen to be a minimal basis set for the code so that |
| 1606 |
|
|
all other codewords can be calculated by linearly combining codewords |
| 1607 |
|
|
in the generator matrix. |
| 1608 |
|
|
|
| 1609 |
|
|
The generator matrix for the code from Example \ref{ex:cedc0:slco0:spcm0:01} is |
| 1610 |
|
|
|
| 1611 |
|
|
\begin{equation} |
| 1612 |
|
|
\label{eq:cedc0:slco0:sgma0:01} |
| 1613 |
|
|
G = \left[ |
| 1614 |
|
|
\begin{array}{ccccccc} |
| 1615 |
|
|
1 & 0 & 0 & 0 & 1 & 1 & 1 \\ |
| 1616 |
|
|
0 & 1 & 0 & 0 & 1 & 0 & 1 \\ |
| 1617 |
|
|
0 & 0 & 1 & 0 & 0 & 1 & 1 \\ |
| 1618 |
|
|
0 & 0 & 0 & 1 & 1 & 1 & 0 |
| 1619 |
|
|
\end{array} |
| 1620 |
|
|
\right] . |
| 1621 |
|
|
\end{equation} |
| 1622 |
|
|
|
| 1623 |
|
|
\noindent{}Note that this generator matrix also appears as Table |
| 1624 |
|
|
\ref{tbl:lem:cedc0:slco0:spcm0:01:01}. |
| 1625 |
|
|
|
| 1626 |
|
|
As with a parity check matrix $H$, we prefer a certain form for |
| 1627 |
|
|
a generator matrix $G$. This form is exemplified by |
| 1628 |
|
|
(\ref{eq:cedc0:slco0:sgma0:01}), where $G$ consists of |
| 1629 |
|
|
the identity matrix with a second matrix concatenated: |
| 1630 |
|
|
|
| 1631 |
|
|
\begin{equation} |
| 1632 |
|
|
\label{eq:cedc0:slco0:sgma0:01b} |
| 1633 |
|
|
G_{k \times n} = [ I_{k \times k} | G'_{k \times n-k}] . |
| 1634 |
|
|
\end{equation} |
| 1635 |
|
|
|
| 1636 |
|
|
For the same linear code, there is a simple relationship between the |
| 1637 |
|
|
parity check matrix $H$ and the generator matrix $G$, assuming that |
| 1638 |
|
|
$H$ and $G$ are in the forms suggested by equations |
| 1639 |
|
|
(\ref{eq:cedc0:slco0:spcm0:06}) and (\ref{eq:cedc0:slco0:sgma0:01b}), |
| 1640 |
|
|
respectively (the forms containing the identity matrix). This |
| 1641 |
|
|
simple relationship is |
| 1642 |
|
|
|
| 1643 |
|
|
\begin{equation} |
| 1644 |
|
|
\label{eq:cedc0:slco0:sgma0:02} |
| 1645 |
|
|
G' = (H')^T, |
| 1646 |
|
|
\end{equation} |
| 1647 |
|
|
|
| 1648 |
|
|
\noindent{}or equivalently |
| 1649 |
|
|
|
| 1650 |
|
|
\begin{equation} |
| 1651 |
|
|
\label{eq:cedc0:slco0:sgma0:03} |
| 1652 |
|
|
H' = (G')^T . |
| 1653 |
|
|
\end{equation} |
| 1654 |
|
|
|
| 1655 |
|
|
It is not difficult to intuitively understand |
| 1656 |
|
|
(\ref{eq:cedc0:slco0:sgma0:02}) and (\ref{eq:cedc0:slco0:sgma0:03}) |
| 1657 |
|
|
with the aid of Example \ref{ex:cedc0:slco0:spcm0:01} and the definition |
| 1658 |
|
|
of $H$ and $G$ in |
| 1659 |
|
|
(\ref{eq:ex:cedc0:slco0:spcm0:01:02}) and |
| 1660 |
|
|
(\ref{eq:cedc0:slco0:sgma0:01b}), respectively. To go from $H$ to $G$, |
| 1661 |
|
|
imagine applying the parity check relationship (Eq. \ref{eq:ex:cedc0:slco0:spcm0:01:03}, |
| 1662 |
|
|
for example) to the unit vector $[d_0 d_1 d_2 d_3] = [1 0 0 0]$. It is easy to see that |
| 1663 |
|
|
to satisfy the parity check relationship, $c_0$, $c_1$, and $c_2$ will need to be |
| 1664 |
|
|
set to the values of the first column in $H$, i.e. |
| 1665 |
|
|
$\left[\begin{array}{c}c_0\\c_1\\c_2\end{array}\right] = \left[\begin{array}{c}1\\1\\0\end{array}\right]$. |
| 1666 |
|
|
With $[d_0 d_1 d_2 d_3] = [0 1 0 0]$, $c_0$, $c_1$, and $c_2$ will need to be set |
| 1667 |
|
|
to the values of the second column in $H$, and so on. To go from $G$ to |
| 1668 |
|
|
$H$, the argument supplied in the proof of Lemma |
| 1669 |
|
|
\ref{lem:cedc0:slco0:spcm0:01} applies. |
| 1670 |
|
|
|
| 1671 |
|
|
Thus, as long as they are conditioned properly, the parity check matrix $H$ and the |
| 1672 |
|
|
generator matrix $G$ are equivalent, and one can translate between the two forms |
| 1673 |
|
|
by inspection. |
| 1674 |
|
|
|
| 1675 |
|
|
|
| 1676 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1677 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1678 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1679 |
|
|
\subsection{Properties Of Linear Codes} |
| 1680 |
|
|
\label{cedc0:slco0:splc0} |
| 1681 |
|
|
|
| 1682 |
|
|
In this section we present many important properties of linear codes. |
| 1683 |
|
|
Although most of these properties follow immediately from the observation |
| 1684 |
|
|
that a linear code is a subspace of $\mathbb{B}^n$ and could have been |
| 1685 |
|
|
presented in Section \ref{cedc0:slco0:sdef0}, the presentation of these properties |
| 1686 |
|
|
is best made in terms of the parity check matrix and the generator matrix, |
| 1687 |
|
|
and so the presentation of these properties was postponed until after the |
| 1688 |
|
|
parity check matrix and generator matrix were discussed. |
| 1689 |
|
|
|
| 1690 |
|
|
\begin{vworklemmastatement} |
| 1691 |
|
|
\label{lem:cedc0:slco0:splc0:01} |
| 1692 |
|
|
The sum of two or more codewords in a linear code is also a codeword. (This also includes |
| 1693 |
|
|
adding a codeword to itself.) |
| 1694 |
|
|
\end{vworklemmastatement} |
| 1695 |
|
|
\begin{vworklemmaproof} |
| 1696 |
|
|
This property follows immediately from the definition of a code as a subspace and |
| 1697 |
|
|
from Lemma \ref{lem:cedc0:sfft0:rmc0:01}. The generator matrix $G$ of a code |
| 1698 |
|
|
is a $k \times n$ matrix and will always have rank $k$. If we denote the rows of |
| 1699 |
|
|
the generator matrix as $r_0, r_1, \ldots, r_{k-1}$, then any codeword will be the |
| 1700 |
|
|
parameterized sum $\alpha_0 r_0 + \alpha_1 r_1 + \ldots + \alpha_{k-1} r_{k-1}$. |
| 1701 |
|
|
Any sum of codewords will be a sum of this form, and |
| 1702 |
|
|
superfluous repeated terms can be removed |
| 1703 |
|
|
(Property \ref{prop:enum:cedc0:sfft0:dff0:01:02}, p. \pageref{prop:enum:cedc0:sfft0:dff0:01:02}), |
| 1704 |
|
|
leaving only a simple parameterized sum of the form |
| 1705 |
|
|
$\alpha_0 r_0 + \alpha_1 r_1 + \ldots + \alpha_{k-1} r_{k-1}$, |
| 1706 |
|
|
with $\alpha_0, \ldots, \alpha_{k-1} \in \mathbb{B}$. |
| 1707 |
|
|
\end{vworklemmaproof} |
| 1708 |
|
|
|
| 1709 |
|
|
\begin{vworklemmastatement} |
| 1710 |
|
|
\label{lem:cedc0:slco0:splc0:02} |
| 1711 |
|
|
Any linear code includes $\mathbf{0_{1 \times n}}$ as a codeword. |
| 1712 |
|
|
\end{vworklemmastatement} |
| 1713 |
|
|
\begin{vworklemmaproof} |
| 1714 |
|
|
This property is inherent in the traditional linear algebra definition |
| 1715 |
|
|
of a subspace. As an alternative, we may simply add any codeword to itself |
| 1716 |
|
|
to obtain $\mathbf{0_{1 \times n}}$, which will then be a codeword |
| 1717 |
|
|
by Lemma \ref{lem:cedc0:slco0:splc0:01}. |
| 1718 |
|
|
\end{vworklemmaproof} |
| 1719 |
|
|
|
| 1720 |
|
|
\begin{vworklemmastatement} |
| 1721 |
|
|
\label{lem:cedc0:slco0:splc0:03} |
| 1722 |
|
|
In a linear code, the weight $w$ of a minimum weight codeword (excluding |
| 1723 |
|
|
$\mathbf{0_{1 \times n}}$) is the minimum Hamming distance |
| 1724 |
|
|
$\hat{d}$ of the code. |
| 1725 |
|
|
\end{vworklemmastatement} |
| 1726 |
|
|
\begin{vworklemmaproof} |
| 1727 |
|
|
Assume that there are two codewords $c_1, c_2$ such that |
| 1728 |
|
|
$d(c_1, c_2) < w$. The exclusive-OR of $c_1$ and $c_2$, |
| 1729 |
|
|
$c_1 \oplus c_2$, |
| 1730 |
|
|
must also be a codeword (by Lemma \ref{lem:cedc0:slco0:splc0:01}). |
| 1731 |
|
|
However, note also that $wt(c_1 \oplus c_2)$ is the number of bit |
| 1732 |
|
|
positions in which $c_1$ and $c_2$ differ, thus |
| 1733 |
|
|
$c_1 \oplus c_2$ is a codeword in the code with |
| 1734 |
|
|
$wt(c_1 \oplus c_2) < w$, which contradicts our initial assumption of |
| 1735 |
|
|
knowing a minimum-weight codeword in the code. |
| 1736 |
|
|
\end{vworklemmaproof} |
| 1737 |
|
|
|
| 1738 |
|
|
|
| 1739 |
|
|
|
| 1740 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1741 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1742 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1743 |
|
|
\subsection{Syndrome Decoding} |
| 1744 |
|
|
\label{cedc0:slco0:ssdc0} |
| 1745 |
|
|
|
| 1746 |
|
|
A defining equation for linear code membership is given by |
| 1747 |
|
|
(\ref{eq:cedc0:slco0:spcm0:01}), $H m^T = \mathbf{0}$. For codes harnessed |
| 1748 |
|
|
for error-detection only, this equation is adequate, as calculating |
| 1749 |
|
|
$H m^T$ and comparing against $\mathbf{0}$ (i.e. decoding) is an economical operation. |
| 1750 |
|
|
However, for codes harnessed for error-correction, we seek a way to ``round'' back to the |
| 1751 |
|
|
nearest codeword. |
| 1752 |
|
|
|
| 1753 |
|
|
|
| 1754 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1755 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1756 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1757 |
|
|
\subsection[Relationship Between The Parity Check Matrix And \protect\mbox{\protect$\hat{d}$}] |
| 1758 |
|
|
{Relationship Between The Parity Check Matrix And \protect\mbox{\protect\boldmath$\hat{d}$}} |
| 1759 |
|
|
\label{cedc0:slco0:spcd0} |
| 1760 |
|
|
|
| 1761 |
|
|
One of the most important properties of a code is its minimum Hamming distance |
| 1762 |
|
|
$\hat{d}$. Here we demonstrate the relationship between the parity check matrix |
| 1763 |
|
|
$H$, the generator matrix $G$, and the minimum Hamming distance $\hat{d}$ of a |
| 1764 |
|
|
linear code. |
| 1765 |
|
|
|
| 1766 |
|
|
Upon inspection of the mechanics of the membership condition for a linear |
| 1767 |
|
|
code, (\ref{eq:cedc0:slco0:spcm0:01}), it is apparent that |
| 1768 |
|
|
$Hm^T$ is the sum of all columns from $H$ corresponding to a `1' in |
| 1769 |
|
|
$m$. Thus code membership is tied to the ways in which columns of |
| 1770 |
|
|
$H$ can be added to give $\mathbf{0}$. |
| 1771 |
|
|
|
| 1772 |
|
|
The following lemma is immediately apparent. |
| 1773 |
|
|
|
| 1774 |
|
|
\begin{vworklemmastatement} |
| 1775 |
|
|
\label{lem:cedc0:slco0:spcd0:01} |
| 1776 |
|
|
If no fewer than $d$ columns of $H$ can be summed to give $\mathbf{0}$, |
| 1777 |
|
|
the code has a minimum Hamming distance of $\hat{d}=d$. |
| 1778 |
|
|
\end{vworklemmastatement} |
| 1779 |
|
|
\begin{vworklemmaproof} |
| 1780 |
|
|
Choose any codeword $m \in C$. By definition, |
| 1781 |
|
|
$Hm^T = \mathbf{0}$, as this is the membership |
| 1782 |
|
|
condition (\ref{eq:cedc0:slco0:spcm0:01}) for a linear code. We desire |
| 1783 |
|
|
to modify $m \in C$ by bit corruptions to form a second codeword $m' \in C$, |
| 1784 |
|
|
and again by definition |
| 1785 |
|
|
$H(m')^T = \mathbf{0}$. Each bit corruption of $m$ will either include (if a 0 is corrupted |
| 1786 |
|
|
to a 1) or exclude (if a 1 is corrupted to 0) a |
| 1787 |
|
|
column of $H$ from the sum which is the $n-k$ check bits. If $Hm^T = \mathbf{0}$, |
| 1788 |
|
|
then in order for $H(m')^T = \mathbf{0}$, the sum of the included or excluded columns |
| 1789 |
|
|
must be $\mathbf{0}$. If no fewer than $d$ columns of $H$ sum to $\mathbf{0}$, then |
| 1790 |
|
|
no fewer than $d$ bit corruptions can change any $m \in C$ to some $m' \in C$. |
| 1791 |
|
|
\end{vworklemmaproof} |
| 1792 |
|
|
\vworklemmafooter{} |
| 1793 |
|
|
|
| 1794 |
|
|
A second lemma is also obvious by examining the form of the |
| 1795 |
|
|
parity check matrix given in (\ref{eq:cedc0:slco0:spcm0:06}), although |
| 1796 |
|
|
the result can be proved without this specific form. |
| 1797 |
|
|
|
| 1798 |
|
|
\begin{vworklemmastatementpar}{Singleton Bound} |
| 1799 |
|
|
\label{lem:cedc0:slco0:spcd0:03} |
| 1800 |
|
|
\index{Singleton bound}No code can have a maximum Hamming distance $\hat{d}$ larger than |
| 1801 |
|
|
$n-k+1$. |
| 1802 |
|
|
\end{vworklemmastatementpar} |
| 1803 |
|
|
\begin{vworklemmaparsection}{Proof \#1 (For Linear Codes)} |
| 1804 |
|
|
Choose any codeword $m \in C$. By definition, |
| 1805 |
|
|
$Hm^T = \mathbf{0}$, as this is the membership |
| 1806 |
|
|
condition (\ref{eq:cedc0:slco0:spcm0:01}) for a linear code. We desire |
| 1807 |
|
|
to modify $m \in C$ by bit corruptions to form a second codeword $m' \in C$, |
| 1808 |
|
|
and again by definition |
| 1809 |
|
|
$H(m')^T = \mathbf{0}$. Each bit corruption of $m$ will either include (if a 0 is corrupted |
| 1810 |
|
|
to a 1) or exclude (if a 1 is corrupted to 0) a |
| 1811 |
|
|
column of $H$ from the sum which is the $n-k$ check bits. If $Hm^T = \mathbf{0}$, |
| 1812 |
|
|
then in order for $H(m')^T = \mathbf{0}$, the sum of the included or excluded columns |
| 1813 |
|
|
must be $\mathbf{0}$. If no fewer than $d$ columns of $H$ sum to $\mathbf{0}$, then |
| 1814 |
|
|
no fewer than $d$ bit corruptions can change any $m \in C$ to some $m' \in C$. |
| 1815 |
|
|
\end{vworklemmaparsection} |
| 1816 |
|
|
\begin{vworklemmaparsection}{Proof \#2 (For Any Code, Not Necessarily Linear)} |
| 1817 |
|
|
Choose any codeword $m \in C$. Choose any second codeword $m' \in C$, where |
| 1818 |
|
|
only one bit among the $k$ data bits is different between $m$ and $m'$. Note that we can |
| 1819 |
|
|
change $m$ into $m'$ through at most $n-k+1$ bit corruptions: one corruption among the $k$ |
| 1820 |
|
|
data bits and at most $n-k$ corruptions of all check bits. |
| 1821 |
|
|
\end{vworklemmaparsection} |
| 1822 |
|
|
\vworklemmafooter{} |
| 1823 |
|
|
|
| 1824 |
|
|
|
| 1825 |
|
|
|
| 1826 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1827 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1828 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1829 |
|
|
\subsection{Relationship Between The Parity Check Matrix And Burst Error Detection Capability} |
| 1830 |
|
|
\label{cedc0:slco0:spcb0} |
| 1831 |
|
|
|
| 1832 |
|
|
For any code, linear or non-linear, the Singleton bound |
| 1833 |
|
|
(Section \ref{cedc0:scob0:rbc0:saul0} and Lemma \ref{lem:cedc0:slco0:spcd0:03}) |
| 1834 |
|
|
assures us that $n-k$ check bits cannot always detect a burst error of |
| 1835 |
|
|
$n-k+1$ bits. This is an upper limit that cannot be violated. |
| 1836 |
|
|
|
| 1837 |
|
|
However, intuitively, it seems plausible that $n-k$ check bits could detect a |
| 1838 |
|
|
burst error of length $n-k$. Imagine that the burst error occurs within a span of |
| 1839 |
|
|
$n-k$ bits among the $k$ data bits. If each of the $2^{n-k}$ combinations of the |
| 1840 |
|
|
$n-k$ bits involved in the burst error maps to a different pattern among the $n-k$ |
| 1841 |
|
|
check bits, then every burst error of length $n-k$ among the data bits |
| 1842 |
|
|
would be detectable. Intuitively, a one-to-one mapping seems to be the criterion |
| 1843 |
|
|
for detection of a burst error of length $n-k$. |
| 1844 |
|
|
|
| 1845 |
|
|
For a linear code, the necessary condition for detection of a burst error |
| 1846 |
|
|
of length $n-k$ comes directly from Lemma |
| 1847 |
|
|
\ref{lem:cedc0:sfft0:rmc0:01}, and we present this necessary condition as the |
| 1848 |
|
|
following lemma. |
| 1849 |
|
|
|
| 1850 |
|
|
\begin{vworklemmastatement} |
| 1851 |
|
|
\label{lem:cedc0:slco0:spcb0:01} |
| 1852 |
|
|
A code can detect burst errors of length $b$ iff every $b$ contiguous |
| 1853 |
|
|
columns from the code's parity check matrix $H$ are linearly independent. |
| 1854 |
|
|
(For a code to detect burst errors of length $n-k$, any $n-k$ contiguous |
| 1855 |
|
|
columns from the code's parity check matrix must form a full-rank matrix.) |
| 1856 |
|
|
\end{vworklemmastatement} |
| 1857 |
|
|
\begin{vworklemmaproof} |
| 1858 |
|
|
Assume a codeword $c$ in the code $C$: then $Hc^T=\mathbf{0}$. |
| 1859 |
|
|
We desire to introduce a burst error of length $b$ into $c$, and we can |
| 1860 |
|
|
do this by summing an error vector $e$ with $c$, with the understanding that |
| 1861 |
|
|
$e$ may contain 1's only in the range of columns corresponding to the burst |
| 1862 |
|
|
error and 0's everywhere else. In order for the burst error to be undetected, we |
| 1863 |
|
|
require $H(c \oplus e)^T=\mathbf{0}$, or equivalently that |
| 1864 |
|
|
$He^T=\mathbf{0}$. In order for $He^T=\mathbf{0}$, either |
| 1865 |
|
|
$e = \mathbf{0}$ or else the columns of $H$ corresponding to the |
| 1866 |
|
|
1's in $e$ are linearly dependent and can sum to $\mathbf{0}$. |
| 1867 |
|
|
The case of $e=\mathbf{0}$ corresponds to no error, and the case |
| 1868 |
|
|
of $e \neq \mathbf{0}$ but $He^T=\mathbf{0}$ can happen only if |
| 1869 |
|
|
$b$ contiguous columns of $H$ corresponding to the location of the burst error |
| 1870 |
|
|
are not linearly independent. |
| 1871 |
|
|
\end{vworklemmaproof} |
| 1872 |
|
|
\vworklemmafooter{} |
| 1873 |
|
|
|
| 1874 |
|
|
|
| 1875 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1876 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1877 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1878 |
|
|
\subsection{Automatic Generation Of The Parity Check Matrix} |
| 1879 |
|
|
\label{cedc0:slco0:sagp0} |
| 1880 |
|
|
|
| 1881 |
|
|
|
| 1882 |
|
|
|
| 1883 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1884 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1885 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1886 |
|
|
\section{Hamming Codes} |
| 1887 |
|
|
%Section tag: hco0 |
| 1888 |
|
|
\label{cedc0:shco0} |
| 1889 |
|
|
|
| 1890 |
|
|
\index{Hamming code}\emph{Hamming codes} are a family of $\hat{d}=3$ (double |
| 1891 |
|
|
error detecting, single error correcting) codes which were discovered/developed |
| 1892 |
|
|
by Hamming. |
| 1893 |
|
|
|
| 1894 |
|
|
Consider the code represented by the parity check matrix |
| 1895 |
|
|
|
| 1896 |
|
|
\begin{equation} |
| 1897 |
|
|
\label{eq:cedc0:shco0:01} |
| 1898 |
|
|
H = \left[ |
| 1899 |
|
|
\begin{array}{ccccccc} |
| 1900 |
|
|
1 & 0 & 1 & 0 & 1 & 0 & 1 \\ |
| 1901 |
|
|
0 & 1 & 1 & 0 & 0 & 1 & 1 \\ |
| 1902 |
|
|
0 & 0 & 0 & 1 & 1 & 1 & 1 |
| 1903 |
|
|
\end{array} |
| 1904 |
|
|
\right] , |
| 1905 |
|
|
\end{equation} |
| 1906 |
|
|
|
| 1907 |
|
|
\noindent{}which is known as the Hamming $(7, 4)$ code. Notice that |
| 1908 |
|
|
the columns of $H$, if one considers the first row the least significant bit, are the |
| 1909 |
|
|
binary equivalents of the integers 1 through 7, arranged in order from left to right. Notice |
| 1910 |
|
|
also that $H$ is not in standard form |
| 1911 |
|
|
suggested by |
| 1912 |
|
|
(\ref{eq:cedc0:slco0:spcm0:06}), although the columns can be rearranged to |
| 1913 |
|
|
place it in standard form. |
| 1914 |
|
|
|
| 1915 |
|
|
One interesting feature of the code suggested by (\ref{eq:cedc0:shco0:01}) |
| 1916 |
|
|
is when one considers the syndrome of a received message $m$, $syn(m) = Hm^T$. |
| 1917 |
|
|
If the message is received correctly, $syn(m) = Hm^T = \mathbf{0}$. If the |
| 1918 |
|
|
message is received with one corrupted bit, the syndrome will give the ordinal |
| 1919 |
|
|
index of the corrupted bit: for example, a message with the third bit corrupted will |
| 1920 |
|
|
generate a syndrome of $\left[\begin{array}{c}1\\1\\0\end{array}\right]$, which is the |
| 1921 |
|
|
third column of $H$ and is the binary representation of 3 (and this leads to |
| 1922 |
|
|
convenient correction either in digital logic or in software). A message with two bits |
| 1923 |
|
|
corrupted will always represent a detectable corruption, but would be corrected |
| 1924 |
|
|
erroneously. A message with three or more corrupted bits may or may not be |
| 1925 |
|
|
detected and |
| 1926 |
|
|
can never be corrected. Specifically note that an error involving 3 or more bits |
| 1927 |
|
|
will not be detected if the sum of the columns of $H$ corresponding to the errors |
| 1928 |
|
|
is $\mathbf{0}$. |
| 1929 |
|
|
|
| 1930 |
|
|
However, by far the most interesting feature of the code suggested by |
| 1931 |
|
|
(\ref{eq:cedc0:shco0:01}) is that it provides a ``formula'' or ``pattern'' |
| 1932 |
|
|
approach for the construction of a code with $\hat{d}=3$. Note that |
| 1933 |
|
|
the code can be scaled up by choosing an $H$ with $i$ rows and populating |
| 1934 |
|
|
it with columns containing the binary representations of the integers |
| 1935 |
|
|
from 1 through $2^i - 1$, in order. The code suggested by (\ref{eq:cedc0:shco0:01}) |
| 1936 |
|
|
gives a pattern for the construction of a $(2^i - 1, 2^i - i - 1, 3)$ code |
| 1937 |
|
|
with as large a length as desired. |
| 1938 |
|
|
|
| 1939 |
|
|
The Hamming codes with $\hat{d}=3$ represent the codes with the largest $\hat{d}$ that |
| 1940 |
|
|
can be constructed without more sophisticated mathematical tools. We |
| 1941 |
|
|
develop these tools in Sections \ref{cedc0:sfft1} and |
| 1942 |
|
|
\ref{cedc0:scco0}. |
| 1943 |
|
|
|
| 1944 |
|
|
Hamming codes are perfect codes. If $i \in \vworkintsetpos$ is a parameter, |
| 1945 |
|
|
choose $n=2^i - 1$ and $k = 2^n - n - 1$ to form an |
| 1946 |
|
|
$(n,k,3) = (2^i - 1, 2^i - i - 1, 3)$ Hamming code. In order to give |
| 1947 |
|
|
a minimum Hamming distance $\hat{d}$ of 3, we require a packing radius $\rho$ of |
| 1948 |
|
|
1. The number of messages per packing sphere multiplied by the number of codewords gives the |
| 1949 |
|
|
total number of messages, i.e. |
| 1950 |
|
|
|
| 1951 |
|
|
\begin{equation} |
| 1952 |
|
|
\label{eq:cedc0:shco0:02} |
| 1953 |
|
|
\left[ \left(\begin{array}{c}2^i - 1\\0\end{array}\right) |
| 1954 |
|
|
+ \left(\begin{array}{c}2^i - 1\\1\end{array}\right) \right] |
| 1955 |
|
|
2^{2^i-i-1} = 2^{2^i-1}, |
| 1956 |
|
|
\end{equation} |
| 1957 |
|
|
|
| 1958 |
|
|
\noindent{}which the reader is encouraged to verify (Exercise \ref{exe:cedc0:sexe0:02}). |
| 1959 |
|
|
|
| 1960 |
|
|
The observation that Hamming codes exists for all values of the parameter |
| 1961 |
|
|
$i \in \vworkintsetpos$ and are perfect codes leads to a very easy-to-remember |
| 1962 |
|
|
rule of thumb which we present as a lemma. |
| 1963 |
|
|
|
| 1964 |
|
|
\begin{vworklemmastatement} |
| 1965 |
|
|
\label{lem:cedc0:shco0:01} |
| 1966 |
|
|
A block of $n=2^i$ requires $n-k=i+1$ check bits to protect at $\hat{d}=3$. |
| 1967 |
|
|
\end{vworklemmastatement} |
| 1968 |
|
|
\begin{vworklemmaproof} |
| 1969 |
|
|
A block of $n=2^i-1$ bits requires $n-k=i$ check bits to protect at $\hat{d}=3$, and |
| 1970 |
|
|
can be protected with a perfect Hamming code. At $n=2^i$ bits, $i$ check bits |
| 1971 |
|
|
are no longer adequate, because the code at $n=2^i-1$ is a perfect code and all |
| 1972 |
|
|
messages are consumed by the necessary packing space; thus at least $i+1$ check bits |
| 1973 |
|
|
are required. However, $i+1$ check bits will protect $n=2^{i+1}-1$ bits using a |
| 1974 |
|
|
perfect Hamming code, so $i+1$ bits are enough to protect $n=2^i$ bits. |
| 1975 |
|
|
\end{vworklemmaproof} |
| 1976 |
|
|
\vworklemmafooter{} |
| 1977 |
|
|
|
| 1978 |
|
|
We illustrate the application of Lemma \ref{lem:cedc0:shco0:01} with the following |
| 1979 |
|
|
example. |
| 1980 |
|
|
|
| 1981 |
|
|
\begin{vworkexamplestatement} |
| 1982 |
|
|
\label{ex:cedc0:shco0:01} |
| 1983 |
|
|
Estimate the number of check bits required |
| 1984 |
|
|
to protect a 128K ROM at $\hat{d}=3$. |
| 1985 |
|
|
\end{vworkexamplestatement} |
| 1986 |
|
|
\begin{vworkexampleparsection}{Solution} |
| 1987 |
|
|
128K $=2^{17}$ bytes $=2^{20}$ bits, thus $n=2^i=2^{20}$ in applying |
| 1988 |
|
|
Lemma \ref{lem:cedc0:shco0:01}. $i+1=21$ check bits are required to protect |
| 1989 |
|
|
the ROM at $\hat{d}=3$ (although there may be practical reasons for using more check bits). |
| 1990 |
|
|
\end{vworkexampleparsection} |
| 1991 |
|
|
\vworkexamplefooter{} |
| 1992 |
|
|
|
| 1993 |
|
|
|
| 1994 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1995 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1996 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 1997 |
|
|
\section{Finite Field Theory Applied To Polynomials} |
| 1998 |
|
|
%Section tag: fft1 |
| 1999 |
|
|
\label{cedc0:sfft1} |
| 2000 |
|
|
|
| 2001 |
|
|
|
| 2002 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2003 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2004 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2005 |
|
|
\section{Cyclic Codes} |
| 2006 |
|
|
%Section tag: cco0 |
| 2007 |
|
|
\label{cedc0:scco0} |
| 2008 |
|
|
|
| 2009 |
|
|
Cyclic codes are the workhorses of linear codes, and are the codes used |
| 2010 |
|
|
most often in practice. Cyclic codes are attractive because: |
| 2011 |
|
|
|
| 2012 |
|
|
\begin{itemize} |
| 2013 |
|
|
\item Mathematically, they are best understood. |
| 2014 |
|
|
\item They have a convenient implementation in digital logic using shift |
| 2015 |
|
|
registers (which can be mimicked in software, but not especially |
| 2016 |
|
|
efficiently). |
| 2017 |
|
|
\end{itemize} |
| 2018 |
|
|
|
| 2019 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2020 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2021 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2022 |
|
|
\subsection{Definition And Properties Of Cyclic Codes} |
| 2023 |
|
|
%Subsection tag: dpo0 |
| 2024 |
|
|
\label{cedc0:scco0:sdpo0} |
| 2025 |
|
|
|
| 2026 |
|
|
The discussion of cyclic codes necessarily entails polynomial math, and |
| 2027 |
|
|
it is most convenient to think of the terms of a polynomial arranged with |
| 2028 |
|
|
the highest-order term first (and to think of the ``leftmost'' part of |
| 2029 |
|
|
a message as being transmitted first). For this reason, for the discussion of cyclic |
| 2030 |
|
|
codes, we prefer to think of a message as an ordered collection of bits |
| 2031 |
|
|
|
| 2032 |
|
|
\begin{equation} |
| 2033 |
|
|
\label{eq:cedc0:scco0:sdpo0:a01} |
| 2034 |
|
|
[m_{n-1}, m_{n-2}, \ldots{}, m_{0}] |
| 2035 |
|
|
\end{equation} |
| 2036 |
|
|
|
| 2037 |
|
|
\noindent{}rather than the ordered collection given in (\ref{eq:cedc0:scon0:sccb0:01}). |
| 2038 |
|
|
Similarly, we may also use the following notations for messages |
| 2039 |
|
|
|
| 2040 |
|
|
\begin{eqnarray} |
| 2041 |
|
|
\label{eq:cedc0:scco0:sdpo0:a02} |
| 2042 |
|
|
& [d_{k-1}, d_{k-2}, \ldots{}, d_{0}, c_{n-k-1}, c_{n-k-2}, \ldots{}, c_{0}] & \\ |
| 2043 |
|
|
\label{eq:cedc0:scco0:sdpo0:a02b} |
| 2044 |
|
|
& [d_{k-1}, d_{k-2}, \ldots{}, d_{0}] | [c_{n-k-1}, c_{n-k-2}, \ldots{}, c_{0}] & |
| 2045 |
|
|
\end{eqnarray} |
| 2046 |
|
|
|
| 2047 |
|
|
\noindent{}rather than the notations given in (\ref{eq:cedc0:scon0:sccb0:02}) |
| 2048 |
|
|
and (\ref{eq:cedc0:scon0:sccb0:02b}). Figure \ref{fig:cedc0:scon0:sccb0:01} |
| 2049 |
|
|
graphically illustrates this notation with bit nomenclature reversed. |
| 2050 |
|
|
|
| 2051 |
|
|
\begin{figure} |
| 2052 |
|
|
\centering |
| 2053 |
|
|
\includegraphics[width=4.6in]{c_edc0/cword02.eps} |
| 2054 |
|
|
\caption{Message Consisting Of The Concatenation Of $k$ Data Bits And $n-k$ |
| 2055 |
|
|
Check Bits, With Bit Notational Conventions For Cyclic Code Discusssion} |
| 2056 |
|
|
\label{fig:cedc0:scon0:sdpo0:01} |
| 2057 |
|
|
\end{figure} |
| 2058 |
|
|
|
| 2059 |
|
|
A \index{cyclic code}\emph{cyclic code} is a linear code such that whenever |
| 2060 |
|
|
the vector $[m_0 \; m_1 \; m_2 \; \ldots{} \; m_{n-1}]$ is in the code, |
| 2061 |
|
|
$[m_1 \; m_2 \; m_3 \; \ldots{} \; m_0]$ is also in the code. When |
| 2062 |
|
|
this definition is applied recursively, it means that for any codeword, all |
| 2063 |
|
|
cyclic shifts of the codeword are also in the code (that is, in fact, why |
| 2064 |
|
|
a \emph{cyclic} code is called a \emph{cyclic} code). For example, if |
| 2065 |
|
|
10001 is a codeword; then 00011, 00110, 01100, and 11000 must also be |
| 2066 |
|
|
codewords (notice that these last four codewords are left cyclic shifts of the |
| 2067 |
|
|
first codeword). Note that since the code is linear, all sums of codewords |
| 2068 |
|
|
must also be codewords. |
| 2069 |
|
|
|
| 2070 |
|
|
A cyclic code is characterized by a generator polynomial, which we call |
| 2071 |
|
|
$g(x)$, of the form |
| 2072 |
|
|
|
| 2073 |
|
|
\begin{equation} |
| 2074 |
|
|
\label{eq:cedc0:scco0:sdpo0:01} |
| 2075 |
|
|
g(x) = g_{n-k} x_{n-k} + g_{n-k-1} x_{n-k-1} + \; \ldots \; + g_1 x + g_0, |
| 2076 |
|
|
\end{equation} |
| 2077 |
|
|
|
| 2078 |
|
|
\noindent{}a polynomial of degree $n-k$, naturally containing up to $n-k+1$ terms. |
| 2079 |
|
|
Each coefficient $g_{n-k} \ldots g_{0}$ is chosen from $GF(2)$, so that |
| 2080 |
|
|
$g_{n-k} \ldots g_{0} \in \mathbb{B} = \{ 0 , 1 \}$. We assume that |
| 2081 |
|
|
$g_{n-k}$ and $g_{0}$ are both 1. We explain how the generator polynomial |
| 2082 |
|
|
specifies the code beginning in Section \ref{cedc0:scco0:ssut0}. |
| 2083 |
|
|
|
| 2084 |
|
|
Cyclic codes are harnessed in two distinct ways, which we will call |
| 2085 |
|
|
the \emph{strong} and \emph{weak} ways. |
| 2086 |
|
|
|
| 2087 |
|
|
In \emph{strong} utilization of cyclic codes |
| 2088 |
|
|
(Section \ref{cedc0:scco0:ssut0}), we must choose $g(x)$ in a very |
| 2089 |
|
|
special way with respect to $n$, and we cannot increase |
| 2090 |
|
|
$n$ arbitrarily (i.e. we are confined to messages of $n$ or |
| 2091 |
|
|
fewer bits). If we choose $g(x)$ in this way, we can |
| 2092 |
|
|
control the minimum Hamming distance $\hat{d}$ of the cyclic code we specify. |
| 2093 |
|
|
We call this utilization \emph{strong} because we are able to preserve a |
| 2094 |
|
|
strong property, the minimum Hamming distance $\hat{d}$ of the resulting code |
| 2095 |
|
|
(this is a very desirable feature, as it is in general not easy to construct a code |
| 2096 |
|
|
with a desirable large $\hat{d}$, and the theory of cyclic codes provides a way to do |
| 2097 |
|
|
this). |
| 2098 |
|
|
A typical ``strong'' utilization of a cyclic code may be in a communication peripheral |
| 2099 |
|
|
which can only accomodate a message of maximum length $\leq n$, and in this case |
| 2100 |
|
|
we can preserve strong properties of the cyclic code. |
| 2101 |
|
|
|
| 2102 |
|
|
In \emph{weak} utilization of cyclic codes |
| 2103 |
|
|
(Section \ref{cedc0:scco0:swut0}), $n$ is unconstrained, and the minimum Hamming |
| 2104 |
|
|
distance of the code may degrade as far as $\hat{d}=2$ as $n$ is |
| 2105 |
|
|
increased. We call such a utilization |
| 2106 |
|
|
\emph{weak} because only a \emph{weak} set of desirable properties can be preserved |
| 2107 |
|
|
in the resulting code. A typical example of a weak utilization would be the CRC-32 (a |
| 2108 |
|
|
32-bit checksum) used to signature large files. Such a utilization usually cannot |
| 2109 |
|
|
achieve even $\hat{d} = 3$, but can still preserve a low probability of undetected corruption |
| 2110 |
|
|
and protection against certain types of burst errors. |
| 2111 |
|
|
|
| 2112 |
|
|
Note that the choice of generator polynomial $g(x)$ |
| 2113 |
|
|
affects the properties of the code in both |
| 2114 |
|
|
the strong and weak utilizations, but in different ways. |
| 2115 |
|
|
|
| 2116 |
|
|
|
| 2117 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2118 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2119 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2120 |
|
|
\subsection{\emph{Strong} Utilization Of Cyclic Codes} |
| 2121 |
|
|
%Subsection tag: sut0 |
| 2122 |
|
|
\label{cedc0:scco0:ssut0} |
| 2123 |
|
|
|
| 2124 |
|
|
In the strong utilization of a cyclic code, |
| 2125 |
|
|
the vector corresponding to the generator polynomial $g(x)$, |
| 2126 |
|
|
$[0 \; \ldots \; 0 \; g_{n-k} \; g_{n-k-1} \; \ldots \; g_{0}]$ must |
| 2127 |
|
|
be in the code, as must all of its cyclic shifts and sums of its |
| 2128 |
|
|
cyclic shifts. A generator |
| 2129 |
|
|
matrix (not in standard form, and of course not the only generator |
| 2130 |
|
|
matrix) for a cyclic code is of the form |
| 2131 |
|
|
|
| 2132 |
|
|
\begin{equation} |
| 2133 |
|
|
\label{eq:cedc0:scco0:ssut0:02} |
| 2134 |
|
|
G = \left[ |
| 2135 |
|
|
\begin{array}{lllllllll} |
| 2136 |
|
|
g_{n-k} & g_{n-k-1} & g_{n-k-2} & \cdots & g_{0} & 0 & 0 & \cdots{} & 0 \\ |
| 2137 |
|
|
0 & g_{n-k} & g_{n-k-1} & \cdots & g_{1} & g_{0} & 0 & \cdots{} & 0 \\ |
| 2138 |
|
|
0 & 0 & g_{n-k} & \cdots & g_{2} & g_{1} & g_{0} & \cdots{} & 0 \\ |
| 2139 |
|
|
\vdots{} & & & & & & & & \\ |
| 2140 |
|
|
0 & 0 & 0 & \cdots & & & & \cdots{} & g_{0} |
| 2141 |
|
|
\end{array} |
| 2142 |
|
|
\right]_{k \times n} \!\!\!\!\!\!\!\!\!\!. |
| 2143 |
|
|
\end{equation} |
| 2144 |
|
|
|
| 2145 |
|
|
\noindent{}Note that the generator matrix in (\ref{eq:cedc0:scco0:ssut0:02}) |
| 2146 |
|
|
has rows which are cyclic shifts of the coefficients of $g(x)$ (and |
| 2147 |
|
|
for reasons discussed later, the other cyclic |
| 2148 |
|
|
shifts are also in the code). Note also that $G$ is a |
| 2149 |
|
|
$k \times n$ matrix, consistent with (\ref{eq:cedc0:slco0:sgma0:01b}). |
| 2150 |
|
|
|
| 2151 |
|
|
It is apparent from (\ref{eq:cedc0:scco0:ssut0:02}) that G can be |
| 2152 |
|
|
transformed into the form of (\ref{eq:cedc0:slco0:sgma0:01}) by |
| 2153 |
|
|
elementary row operations. Two arguments can be |
| 2154 |
|
|
made. First, by theorem, the determinant of an upper triangular matrix |
| 2155 |
|
|
(the first $k$ columns of $G$) is the product of the diagonal elements, |
| 2156 |
|
|
and since we've assumed $g_0 = g_{n-k} = 1$, this determinant is necessarily 1. |
| 2157 |
|
|
Since the first $k$ columns of $G$ have full rank, they can be transformed |
| 2158 |
|
|
into $I_{k \times k}$. Second, it is clear using elementary row operations how |
| 2159 |
|
|
to transform the first $k$ columns of $G$ into |
| 2160 |
|
|
$I_{k \times k}$ (Exercise \ref{exe:cedc0:sexe0:03}). |
| 2161 |
|
|
|
| 2162 |
|
|
\begin{vworkexamplestatement} |
| 2163 |
|
|
\label{ex:cedc0:scco0:ssut0:01} |
| 2164 |
|
|
For the $(7,4)$ code characterized by the generator polynomial |
| 2165 |
|
|
$g(x) = 1 + x + x^3$, form the generator matrix of the code |
| 2166 |
|
|
as in (\ref{eq:cedc0:scco0:ssut0:02}), reduce it by elementary |
| 2167 |
|
|
row operations to the form of (\ref{eq:cedc0:slco0:sgma0:01}), |
| 2168 |
|
|
and enumerate the $2^k = 16$ codewords. |
| 2169 |
|
|
\end{vworkexamplestatement} |
| 2170 |
|
|
\begin{vworkexampleparsection}{Solution} |
| 2171 |
|
|
With generator polynomial $g(x) = 1 + x + x^3$, $g_0 = 0$, $g_1 = 1$, |
| 2172 |
|
|
$g_2 = 0$, and $g_3 = 1$. By (\ref{eq:cedc0:scco0:ssut0:02}), |
| 2173 |
|
|
|
| 2174 |
|
|
\begin{equation} |
| 2175 |
|
|
\label{eq:ex:cedc0:scco0:ssut0:01:01} |
| 2176 |
|
|
G = \left[ |
| 2177 |
|
|
\begin{array}{ccccccc} |
| 2178 |
|
|
g_0 & g_1 & g_2 & g_3 & 0 & 0 & 0 \\ |
| 2179 |
|
|
0 & g_0 & g_1 & g_2 & g_3 & 0 & 0 \\ |
| 2180 |
|
|
0 & 0 & g_0 & g_1 & g_2 & g_3 & 0 \\ |
| 2181 |
|
|
0 & 0 & 0 & g_0 & g_1 & g_2 & g_3 |
| 2182 |
|
|
\end{array} |
| 2183 |
|
|
\right] |
| 2184 |
|
|
= |
| 2185 |
|
|
\left[ |
| 2186 |
|
|
\begin{array}{ccccccc} |
| 2187 |
|
|
1 & 1 & 0 & 1 & 0 & 0 & 0 \\ |
| 2188 |
|
|
0 & 1 & 1 & 0 & 1 & 0 & 0 \\ |
| 2189 |
|
|
0 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 2190 |
|
|
0 & 0 & 0 & 1 & 1 & 0 & 1 |
| 2191 |
|
|
\end{array} |
| 2192 |
|
|
\right] . |
| 2193 |
|
|
\end{equation} |
| 2194 |
|
|
|
| 2195 |
|
|
Adding (in the sense of $GF(2)$, see Section \ref{cedc0:sfft0:dff0}) |
| 2196 |
|
|
the second row to the first yields |
| 2197 |
|
|
|
| 2198 |
|
|
\begin{equation} |
| 2199 |
|
|
\label{eq:ex:cedc0:scco0:ssut0:01:02} |
| 2200 |
|
|
G = \left[ |
| 2201 |
|
|
\begin{array}{ccccccc} |
| 2202 |
|
|
1 & 0 & 1 & 1 & 1 & 0 & 0 \\ |
| 2203 |
|
|
0 & 1 & 1 & 0 & 1 & 0 & 0 \\ |
| 2204 |
|
|
0 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 2205 |
|
|
0 & 0 & 0 & 1 & 1 & 0 & 1 |
| 2206 |
|
|
\end{array} |
| 2207 |
|
|
\right] . |
| 2208 |
|
|
\end{equation} |
| 2209 |
|
|
|
| 2210 |
|
|
Adding the third row to the first row and to the second row (two |
| 2211 |
|
|
row operations) yields |
| 2212 |
|
|
|
| 2213 |
|
|
\begin{equation} |
| 2214 |
|
|
\label{eq:ex:cedc0:scco0:ssut0:01:03} |
| 2215 |
|
|
G = \left[ |
| 2216 |
|
|
\begin{array}{ccccccc} |
| 2217 |
|
|
1 & 0 & 0 & 0 & 1 & 1 & 0 \\ |
| 2218 |
|
|
0 & 1 & 0 & 1 & 1 & 1 & 0 \\ |
| 2219 |
|
|
0 & 0 & 1 & 1 & 0 & 1 & 0 \\ |
| 2220 |
|
|
0 & 0 & 0 & 1 & 1 & 0 & 1 |
| 2221 |
|
|
\end{array} |
| 2222 |
|
|
\right] . |
| 2223 |
|
|
\end{equation} |
| 2224 |
|
|
|
| 2225 |
|
|
Finally, adding the fourth row to the second row and to the third row (two |
| 2226 |
|
|
row operations) yields |
| 2227 |
|
|
|
| 2228 |
|
|
\begin{equation} |
| 2229 |
|
|
\label{eq:ex:cedc0:scco0:ssut0:01:04} |
| 2230 |
|
|
G = \left[ |
| 2231 |
|
|
\begin{array}{ccccccc} |
| 2232 |
|
|
1 & 0 & 0 & 0 & 1 & 1 & 0 \\ |
| 2233 |
|
|
0 & 1 & 0 & 0 & 0 & 1 & 1 \\ |
| 2234 |
|
|
0 & 0 & 1 & 0 & 1 & 1 & 1 \\ |
| 2235 |
|
|
0 & 0 & 0 & 1 & 1 & 0 & 1 |
| 2236 |
|
|
\end{array} |
| 2237 |
|
|
\right] . |
| 2238 |
|
|
\end{equation} |
| 2239 |
|
|
|
| 2240 |
|
|
The $2^4 = 16$ codewords can be enumerated by forming all linear combinations |
| 2241 |
|
|
of the rows of any of the matrices |
| 2242 |
|
|
(\ref{eq:ex:cedc0:scco0:ssut0:01:01}) |
| 2243 |
|
|
through (\ref{eq:ex:cedc0:scco0:ssut0:01:04}). These 16 codewords are |
| 2244 |
|
|
enumerated in Table \ref{tbl:ex:cedc0:scco0:ssut0:01:01}. |
| 2245 |
|
|
|
| 2246 |
|
|
\begin{table} |
| 2247 |
|
|
\caption{$2^4 = 16$ Codewords For Code Of Example \ref{ex:cedc0:scco0:ssut0:01}} |
| 2248 |
|
|
\label{tbl:ex:cedc0:scco0:ssut0:01:01} |
| 2249 |
|
|
\begin{center} |
| 2250 |
|
|
\begin{tabular}{|c|c|} |
| 2251 |
|
|
\hline |
| 2252 |
|
|
Data & Codeword \\ |
| 2253 |
|
|
(Value Of $k$ Data Bits) & \\ |
| 2254 |
|
|
\hline |
| 2255 |
|
|
\hline |
| 2256 |
|
|
0 & 0000 000 \\ |
| 2257 |
|
|
\hline |
| 2258 |
|
|
1 & 0001 101 \\ |
| 2259 |
|
|
\hline |
| 2260 |
|
|
2 & 0010 111 \\ |
| 2261 |
|
|
\hline |
| 2262 |
|
|
3 & 0011 010 \\ |
| 2263 |
|
|
\hline |
| 2264 |
|
|
4 & 0100 011 \\ |
| 2265 |
|
|
\hline |
| 2266 |
|
|
5 & 0101 110 \\ |
| 2267 |
|
|
\hline |
| 2268 |
|
|
6 & 0110 100 \\ |
| 2269 |
|
|
\hline |
| 2270 |
|
|
7 & 0111 001 \\ |
| 2271 |
|
|
\hline |
| 2272 |
|
|
8 & 1000 110 \\ |
| 2273 |
|
|
\hline |
| 2274 |
|
|
9 & 1001 011 \\ |
| 2275 |
|
|
\hline |
| 2276 |
|
|
10 & 1010 001 \\ |
| 2277 |
|
|
\hline |
| 2278 |
|
|
11 & 1011 100 \\ |
| 2279 |
|
|
\hline |
| 2280 |
|
|
12 & 1100 101 \\ |
| 2281 |
|
|
\hline |
| 2282 |
|
|
13 & 1101 000 \\ |
| 2283 |
|
|
\hline |
| 2284 |
|
|
14 & 1110 010 \\ |
| 2285 |
|
|
\hline |
| 2286 |
|
|
15 & 1111 111 \\ |
| 2287 |
|
|
\hline |
| 2288 |
|
|
\end{tabular} |
| 2289 |
|
|
\end{center} |
| 2290 |
|
|
\end{table} |
| 2291 |
|
|
\end{vworkexampleparsection} |
| 2292 |
|
|
\vworkexamplefooter{} |
| 2293 |
|
|
|
| 2294 |
|
|
|
| 2295 |
|
|
|
| 2296 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2297 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2298 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2299 |
|
|
\subsection{\emph{Weak} Utilization Of Cyclic Codes} |
| 2300 |
|
|
%Subsection tag: wut0 |
| 2301 |
|
|
\label{cedc0:scco0:swut0} |
| 2302 |
|
|
|
| 2303 |
|
|
|
| 2304 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2305 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2306 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2307 |
|
|
\subsection{Perfect Codes} |
| 2308 |
|
|
%Subsection tag: pfc0 |
| 2309 |
|
|
\label{cedc0:scob0:spfc0} |
| 2310 |
|
|
|
| 2311 |
|
|
We define a \index{perfect code}\emph{perfect code} as a code |
| 2312 |
|
|
where (\ref{eq:cedc0:scob0:rbc0:shsp0:01}) |
| 2313 |
|
|
is an equality---that is, where the volume of the $2^k$ packing spheres precisely |
| 2314 |
|
|
consumes the $2^n$ messages available. A perfect code has no ``waste'': that is, |
| 2315 |
|
|
there are no messages which do not participate in maintaining the required separation |
| 2316 |
|
|
between codewords. |
| 2317 |
|
|
|
| 2318 |
|
|
In this section, we address two issues: |
| 2319 |
|
|
|
| 2320 |
|
|
\begin{itemize} |
| 2321 |
|
|
\item The existence of integer solutions to |
| 2322 |
|
|
|
| 2323 |
|
|
\begin{equation} |
| 2324 |
|
|
\label{eq:cedc0:scob0:spfc0:01} |
| 2325 |
|
|
2^k V(n, \rho) = 2^n , |
| 2326 |
|
|
\end{equation} |
| 2327 |
|
|
|
| 2328 |
|
|
which is a question from number theory. |
| 2329 |
|
|
|
| 2330 |
|
|
\item Given $n$,$k$ which satisfy (\ref{eq:cedc0:scob0:spfc0:01}), the existence |
| 2331 |
|
|
of the codes whose possible existence is predicted. It should be remembered |
| 2332 |
|
|
that (\ref{eq:cedc0:scob0:spfc0:01}) is a necessary but not sufficient |
| 2333 |
|
|
condition. |
| 2334 |
|
|
\end{itemize} |
| 2335 |
|
|
|
| 2336 |
|
|
|
| 2337 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2338 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2339 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2340 |
|
|
\subsubsection[Existence Of Integer Solutions To |
| 2341 |
|
|
\protect\mbox{\protect$2^k V(n, \rho) = 2^n$}] |
| 2342 |
|
|
{Existence Of Integer Solutions To |
| 2343 |
|
|
\protect\mbox{\protect\boldmath$2^k V(n, \rho) = 2^n$}} |
| 2344 |
|
|
%Subsubsection tag: pfc0 |
| 2345 |
|
|
\label{cedc0:scob0:spfc0:seis0} |
| 2346 |
|
|
|
| 2347 |
|
|
|
| 2348 |
|
|
|
| 2349 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2350 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2351 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2352 |
|
|
\subsubsection{Existence Of Predicted Perfect Codes} |
| 2353 |
|
|
%Subsubsection tag: epc0 |
| 2354 |
|
|
\label{cedc0:scob0:spfc0:sepc0} |
| 2355 |
|
|
|
| 2356 |
|
|
|
| 2357 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2358 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2359 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2360 |
|
|
\section{Economical Implementation Of Linear Codes In Software} |
| 2361 |
|
|
%Section tag: eim0 |
| 2362 |
|
|
\label{cedc0:seim0} |
| 2363 |
|
|
|
| 2364 |
|
|
|
| 2365 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2366 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2367 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2368 |
|
|
\section[\protect\mbox{\protect$\hat{d}=2$} Codes Useful In Microcontroller Work] |
| 2369 |
|
|
{\protect\mbox{\protect\boldmath$\hat{d}=2$} Codes Useful In Microcontroller Work} |
| 2370 |
|
|
%Section tag: dtc0 |
| 2371 |
|
|
\label{cedc0:sdtc0} |
| 2372 |
|
|
|
| 2373 |
|
|
|
| 2374 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2375 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2376 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2377 |
|
|
\section[\protect\mbox{\protect$\hat{d}=3$} Codes Useful In Microcontroller Work] |
| 2378 |
|
|
{\protect\mbox{\protect\boldmath$\hat{d}=3$} Codes Useful In Microcontroller Work} |
| 2379 |
|
|
%Section tag: dhc0 |
| 2380 |
|
|
\label{cedc0:sdhc0} |
| 2381 |
|
|
|
| 2382 |
|
|
|
| 2383 |
|
|
|
| 2384 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2385 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2386 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2387 |
|
|
\section{Acknowledgements} |
| 2388 |
|
|
\label{cedc0:sack0} |
| 2389 |
|
|
|
| 2390 |
|
|
I'm very grateful to the following individuals who contributed insight |
| 2391 |
|
|
about error-detecting and error-correcting |
| 2392 |
|
|
codes on \index{comp.arch.embedded@\texttt{comp.arch.embedded}}\texttt{comp.arch.embedded} |
| 2393 |
|
|
and other |
| 2394 |
|
|
newsgroups: |
| 2395 |
|
|
Alan Coppola, |
| 2396 |
|
|
Eric Doenges, |
| 2397 |
|
|
Glen Herrmannsfeldt, |
| 2398 |
|
|
Dan Kotlow, |
| 2399 |
|
|
John Larkin, |
| 2400 |
|
|
Steven Murray, |
| 2401 |
|
|
Sphero Pefhany, |
| 2402 |
|
|
Jan-Hinnerk Reichert, |
| 2403 |
|
|
Thad Smith, |
| 2404 |
|
|
and |
| 2405 |
|
|
Jim Stewart. |
| 2406 |
|
|
|
| 2407 |
|
|
I'm grateful to |
| 2408 |
|
|
\index{Sperber, Ron} Ron Sperber \cite{bibref:i:ronsperber} and |
| 2409 |
|
|
\index{Chapman, Robin} Robin Chapman \cite{bibref:i:robinchapman} |
| 2410 |
|
|
for assistance with field theory offered on the |
| 2411 |
|
|
\texttt{sci.math} newsgroup \cite{bibref:n:scimathnewsgroup}. |
| 2412 |
|
|
|
| 2413 |
|
|
I'm also grateful to Mr. Michael J. Downes of the |
| 2414 |
|
|
\index{comp.text.tex@\texttt{comp.text.tex}}\texttt{comp.text.tex} |
| 2415 |
|
|
newsgroup, who assisted me with a technical difficulty involving |
| 2416 |
|
|
the \LaTeX ``$\backslash$\texttt{protect}'' command. |
| 2417 |
|
|
|
| 2418 |
|
|
|
| 2419 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2420 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2421 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2422 |
|
|
\section{Exercises} |
| 2423 |
|
|
\label{cedc0:sexe0} |
| 2424 |
|
|
|
| 2425 |
|
|
\begin{vworkexercisestatement} |
| 2426 |
|
|
\label{exe:cedc0:sexe0:01} |
| 2427 |
|
|
Show that the minimum Hamming distance of the code $\{0001, 0110, 1010, 1101\}$ |
| 2428 |
|
|
is 2. |
| 2429 |
|
|
\end{vworkexercisestatement} |
| 2430 |
|
|
|
| 2431 |
|
|
\begin{vworkexercisestatement} |
| 2432 |
|
|
\label{exe:cedc0:sexe0:02} |
| 2433 |
|
|
Verify Equation \ref{eq:cedc0:shco0:02}. |
| 2434 |
|
|
\end{vworkexercisestatement} |
| 2435 |
|
|
|
| 2436 |
|
|
\begin{vworkexercisestatement} |
| 2437 |
|
|
\label{exe:cedc0:sexe0:03} |
| 2438 |
|
|
Outline a procedure for transforming the $G$ of |
| 2439 |
|
|
(\ref{eq:cedc0:scco0:sdpo0:02}) into |
| 2440 |
|
|
the form of (\ref{eq:cedc0:slco0:sgma0:01}). |
| 2441 |
|
|
\end{vworkexercisestatement} |
| 2442 |
|
|
\vworkexercisefooter{} |
| 2443 |
|
|
|
| 2444 |
|
|
\vworkexercisefooter{} |
| 2445 |
|
|
|
| 2446 |
|
|
|
| 2447 |
|
|
|
| 2448 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2449 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2450 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2451 |
|
|
|
| 2452 |
|
|
\noindent\begin{figure}[!b] |
| 2453 |
|
|
\noindent\rule[-0.25in]{\textwidth}{1pt} |
| 2454 |
|
|
\begin{tiny} |
| 2455 |
|
|
\begin{verbatim} |
| 2456 |
|
|
$RCSfile: c_edc0.tex,v $ |
| 2457 |
|
|
$Source: /home/dashley/cvsrep/e3ft_gpl01/e3ft_gpl01/dtaipubs/esrgubka/c_edc0/c_edc0.tex,v $ |
| 2458 |
|
|
$Revision: 1.22 $ |
| 2459 |
|
|
$Author: dtashley $ |
| 2460 |
|
|
$Date: 2003/11/03 02:14:24 $ |
| 2461 |
|
|
\end{verbatim} |
| 2462 |
|
|
\end{tiny} |
| 2463 |
|
|
\noindent\rule[0.25in]{\textwidth}{1pt} |
| 2464 |
|
|
\end{figure} |
| 2465 |
|
|
|
| 2466 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2467 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2468 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% |
| 2469 |
|
|
% $Log: c_edc0.tex,v $ |
| 2470 |
|
|
% Revision 1.22 2003/11/03 02:14:24 dtashley |
| 2471 |
|
|
% All duplicate labels as flagged by LaTeX removed. Additional files added |
| 2472 |
|
|
% to Microsoft Visual Studio edit context. |
| 2473 |
|
|
% |
| 2474 |
|
|
% Revision 1.21 2002/12/14 07:28:46 dtashley |
| 2475 |
|
|
% Safety checkin. |
| 2476 |
|
|
% |
| 2477 |
|
|
% Revision 1.20 2002/12/10 08:00:44 dtashley |
| 2478 |
|
|
% Safety checkin. |
| 2479 |
|
|
% |
| 2480 |
|
|
% Revision 1.19 2002/12/02 06:29:47 dtashley |
| 2481 |
|
|
% Checking before resuming work at home. |
| 2482 |
|
|
% |
| 2483 |
|
|
% Revision 1.18 2002/12/01 21:29:08 dtashley |
| 2484 |
|
|
% Safety checkin. |
| 2485 |
|
|
% |
| 2486 |
|
|
% Revision 1.17 2002/12/01 02:55:02 dtashley |
| 2487 |
|
|
% Safety checkin. |
| 2488 |
|
|
% |
| 2489 |
|
|
% Revision 1.16 2002/11/29 04:01:38 dtashley |
| 2490 |
|
|
% Safety checkin, before engineering building power outage. |
| 2491 |
|
|
% |
| 2492 |
|
|
% Revision 1.15 2002/11/27 02:34:10 dtashley |
| 2493 |
|
|
% Safety checkin after substantial edits. |
| 2494 |
|
|
% |
| 2495 |
|
|
% Revision 1.14 2002/11/25 04:32:25 dtashley |
| 2496 |
|
|
% Substantial edits. |
| 2497 |
|
|
% |
| 2498 |
|
|
% Revision 1.13 2002/11/24 18:44:21 dtashley |
| 2499 |
|
|
% Substantial edits. Preparing for major reorganization of sections, and |
| 2500 |
|
|
% am checking this in to prevent accidental loss of information. |
| 2501 |
|
|
% |
| 2502 |
|
|
% Revision 1.12 2002/11/22 02:21:30 dtashley |
| 2503 |
|
|
% Substantial edits. |
| 2504 |
|
|
% |
| 2505 |
|
|
% Revision 1.11 2002/11/21 18:02:49 dtashley |
| 2506 |
|
|
% Safety checkin. Substantial edits. |
| 2507 |
|
|
% |
| 2508 |
|
|
% Revision 1.10 2002/11/19 22:08:42 dtashley |
| 2509 |
|
|
% Safety checkin before resuming work. |
| 2510 |
|
|
% |
| 2511 |
|
|
% Revision 1.9 2002/11/03 02:37:07 dtashley |
| 2512 |
|
|
% Substantial edits. Preparing to derive and incorporate material about |
| 2513 |
|
|
% upper limit on Hamming distance that can be achieved with a given number |
| 2514 |
|
|
% of check bits. |
| 2515 |
|
|
% |
| 2516 |
|
|
% Revision 1.8 2002/11/02 02:27:03 dtashley |
| 2517 |
|
|
% Weekly safety checkin. |
| 2518 |
|
|
% |
| 2519 |
|
|
% Revision 1.7 2002/10/31 04:02:23 dtashley |
| 2520 |
|
|
% Evening safety checkin. |
| 2521 |
|
|
% |
| 2522 |
|
|
% Revision 1.6 2002/10/30 02:06:12 dtashley |
| 2523 |
|
|
% Substantial edits of error-detecting and error-correcting codes chapter. |
| 2524 |
|
|
% |
| 2525 |
|
|
% Revision 1.5 2002/10/18 05:50:48 dtashley |
| 2526 |
|
|
% Substantial edits and progress. |
| 2527 |
|
|
% |
| 2528 |
|
|
% Revision 1.4 2002/10/16 01:28:24 dtashley |
| 2529 |
|
|
% Evening safety checkin. |
| 2530 |
|
|
% |
| 2531 |
|
|
% Revision 1.3 2002/10/14 23:32:48 dtashley |
| 2532 |
|
|
% Substantial edits. Resuming work on coding theory chapter. |
| 2533 |
|
|
% |
| 2534 |
|
|
% Revision 1.2 2002/09/25 08:01:09 dtashley |
| 2535 |
|
|
% Evening safety checkin after substantial work on coding chapter. |
| 2536 |
|
|
% |
| 2537 |
|
|
% Revision 1.1 2002/09/25 05:23:29 dtashley |
| 2538 |
|
|
% Initial checkin. |
| 2539 |
|
|
% |
| 2540 |
|
|
%End of file C_EDC0.TEX |
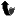 Parent Directory
|
Parent Directory
|  Revision Log
Revision Log