| 1 |
dashley |
8 |
%$Header: /home/dashley/cvsrep/e3ft_gpl01/e3ft_gpl01/dtaipubs/cron/2006/phdtopicpropa/phdtopicpropa.tex,v 1.20 2006/03/27 00:10:30 dashley Exp $
|
| 2 |
|
|
\documentclass[letterpaper,10pt,titlepage]{article}
|
| 3 |
|
|
%
|
| 4 |
|
|
%\pagestyle{headings}
|
| 5 |
|
|
%
|
| 6 |
|
|
\usepackage{amsmath}
|
| 7 |
|
|
\usepackage{amsfonts}
|
| 8 |
|
|
\usepackage{amssymb}
|
| 9 |
|
|
\usepackage[ansinew]{inputenc}
|
| 10 |
|
|
\usepackage[OT1]{fontenc}
|
| 11 |
|
|
\usepackage{graphicx}
|
| 12 |
|
|
%
|
| 13 |
|
|
\begin{document}
|
| 14 |
|
|
%-----------------------------------------------------------------------------------
|
| 15 |
|
|
\title{Ph.D. Topic Proposal}
|
| 16 |
|
|
\author{\vspace{2cm}\\David T. Ashley\\\texttt{dta@e3ft.com}\\\vspace{2cm}}
|
| 17 |
|
|
\date{\vspace*{8mm}\small{Version Control $ $Revision: 1.20 $ $ \\
|
| 18 |
|
|
Version Control $ $Date: 2006/03/27 00:10:30 $ $ (UTC) \\
|
| 19 |
|
|
$ $RCSfile: phdtopicpropa.tex,v $ $ \\
|
| 20 |
|
|
\LaTeX{} Compilation Date: \today{}}}
|
| 21 |
|
|
\maketitle
|
| 22 |
|
|
|
| 23 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 24 |
|
|
%
|
| 25 |
|
|
\begin{abstract}
|
| 26 |
|
|
This document describes my Ph.D. research interests and provides
|
| 27 |
|
|
supporting information. The interests
|
| 28 |
|
|
(described in \S{}\ref{srin0}) revolve around the mathematical
|
| 29 |
|
|
basis of timed automata systems and code generation
|
| 30 |
|
|
from timed automata models.
|
| 31 |
|
|
\end{abstract}
|
| 32 |
|
|
|
| 33 |
|
|
\clearpage{}
|
| 34 |
|
|
\pagenumbering{roman} %No page number on table of contents.
|
| 35 |
|
|
\tableofcontents{}
|
| 36 |
|
|
\clearpage{}
|
| 37 |
|
|
\listoffigures
|
| 38 |
|
|
\clearpage{}
|
| 39 |
|
|
|
| 40 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 41 |
|
|
%Force the page number to 1. We don't want to number the table of contents
|
| 42 |
|
|
%page.
|
| 43 |
|
|
%
|
| 44 |
|
|
\setcounter{page}{1}
|
| 45 |
|
|
\pagenumbering{arabic}
|
| 46 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 47 |
|
|
|
| 48 |
|
|
\section{The Timed Automata Framework}
|
| 49 |
|
|
\label{staf0}
|
| 50 |
|
|
|
| 51 |
|
|
The framework of timed automata isn't commonplace in electrical
|
| 52 |
|
|
engineering, so this section provides
|
| 53 |
|
|
a description.
|
| 54 |
|
|
|
| 55 |
|
|
|
| 56 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 57 |
|
|
|
| 58 |
|
|
\subsection{The Framework}
|
| 59 |
|
|
\label{staf0:stfw0}
|
| 60 |
|
|
|
| 61 |
|
|
The formal framework of timed automata consists of systems of
|
| 62 |
|
|
automatons, each with discrete states, transitions, and
|
| 63 |
|
|
timers that can be reset to zero on transitions.
|
| 64 |
|
|
|
| 65 |
|
|
The framework includes synchronization mechanisms between automatons (i.e.
|
| 66 |
|
|
automatons may interact in well-defined ways)\@. Synchronization mechanisms
|
| 67 |
|
|
consist of ``soft'' synchronization mechanisms and ``hard'' synchronization
|
| 68 |
|
|
mechanisms.
|
| 69 |
|
|
|
| 70 |
|
|
\begin{itemize}
|
| 71 |
|
|
\item \emph{Soft} synchronization mechanisms involve one automaton having transition
|
| 72 |
|
|
functions that involve the discrete state or timers of another automaton.
|
| 73 |
|
|
\item \emph{Hard} synchronization mechanisms involve events. The semantics
|
| 74 |
|
|
of an event require two or more
|
| 75 |
|
|
automatons to make corresponding transitions at exactly the same time.
|
| 76 |
|
|
\end{itemize}
|
| 77 |
|
|
|
| 78 |
|
|
The details of the framework aren't especially important,
|
| 79 |
|
|
and there are several
|
| 80 |
|
|
variations on the framework\footnote{Variations include
|
| 81 |
|
|
substates, differences in the semantics of events, and dynamics that go beyond
|
| 82 |
|
|
$\dot{t} = 1$ (i.e. hybrid systems).} that don't change the essential properties.
|
| 83 |
|
|
|
| 84 |
|
|
The essential properties of the framework (that don't change with the variations) are:
|
| 85 |
|
|
|
| 86 |
|
|
\begin{itemize}
|
| 87 |
|
|
\item A system of timed automata that interact via synchronization
|
| 88 |
|
|
mechanisms can be mathematically combined into a single
|
| 89 |
|
|
larger automaton with a single
|
| 90 |
|
|
discrete state space.
|
| 91 |
|
|
\item There is some symbolic method of reasoning about what values
|
| 92 |
|
|
timers can attain in each discrete state (polytopes, DBMs, etc.).
|
| 93 |
|
|
\item The symbolic reasoning about timer values often allows reasoning about
|
| 94 |
|
|
properties of the system (reachability, liveness, etc.).
|
| 95 |
|
|
\end{itemize}
|
| 96 |
|
|
|
| 97 |
|
|
Timed automata are recognizeable to any embedded software engineer as
|
| 98 |
|
|
``state machines''. A typical automotive embedded system consists of many
|
| 99 |
|
|
features and software components involving discrete state. For example,
|
| 100 |
|
|
software to control an automobile drivetrain with features like automatic 4-wheel drive
|
| 101 |
|
|
as well as sensor and actuator failure modes tends to have a very large discrete
|
| 102 |
|
|
space.
|
| 103 |
|
|
|
| 104 |
|
|
As a contrived example of a system of timed automata, consider the problem of
|
| 105 |
|
|
controlling a drawbridge with one motor and two limit switches so that it goes up and down
|
| 106 |
|
|
with period $K_D + K_U$ (Fig. \ref{fig:staf0:stfw0:000}).
|
| 107 |
|
|
|
| 108 |
|
|
\begin{figure}
|
| 109 |
|
|
\centering
|
| 110 |
|
|
\includegraphics[width=4.0in]{system01.eps}
|
| 111 |
|
|
\caption{Example Timed Automata System (Drawbridge Control)}
|
| 112 |
|
|
\label{fig:staf0:stfw0:000}
|
| 113 |
|
|
\end{figure}
|
| 114 |
|
|
|
| 115 |
|
|
Assume that when raising the drawbridge, it is adequate to energize the motor
|
| 116 |
|
|
until the limit switch $U$ closes. However, when closing the drawbridge,
|
| 117 |
|
|
it is necessary to energize the motor for time $K_L$ beyond
|
| 118 |
|
|
when the limit switch $D$ closes (the $B_{DOWNLOCK}$ state in
|
| 119 |
|
|
Fig. \ref{fig:staf0:stfw0:01}).
|
| 120 |
|
|
|
| 121 |
|
|
One way to design such a system is with two automata
|
| 122 |
|
|
(Fig. \ref{fig:staf0:stfw0:00} and Fig. \ref{fig:staf0:stfw0:01}) interacting via
|
| 123 |
|
|
synchronization mechnisms.
|
| 124 |
|
|
|
| 125 |
|
|
The automaton of Fig. \ref{fig:staf0:stfw0:00} alternates between two
|
| 126 |
|
|
states with period $K_D + K_U$. At any point in time, the state of this
|
| 127 |
|
|
automaton indicates whether the drawbridge should be down or up.
|
| 128 |
|
|
|
| 129 |
|
|
\begin{figure}
|
| 130 |
|
|
\centering
|
| 131 |
|
|
\includegraphics[height=2.5in]{exta01.eps}
|
| 132 |
|
|
\caption{Example Timed Automaton (Drawbridge Target Position Determination)}
|
| 133 |
|
|
\label{fig:staf0:stfw0:00}
|
| 134 |
|
|
\end{figure}
|
| 135 |
|
|
|
| 136 |
|
|
The automaton of Fig. \ref{fig:staf0:stfw0:01} directly
|
| 137 |
|
|
determines the energization of the bridge motor as a function of
|
| 138 |
|
|
the limit switches $D$ and $U$, the discrete state of the automaton
|
| 139 |
|
|
of Fig. \ref{fig:staf0:stfw0:00}, and time.
|
| 140 |
|
|
In the $B_{IDLE}$ state, the motor is deenergized.
|
| 141 |
|
|
In the $B_{UP}$ state, the motor is energized to move the
|
| 142 |
|
|
drawbridge up. In the $B_{DOWN}$ and $B_{DOWNLOCK}$ states,
|
| 143 |
|
|
the motor is energized to move the drawbridge down.
|
| 144 |
|
|
|
| 145 |
|
|
\begin{figure}
|
| 146 |
|
|
\centering
|
| 147 |
|
|
\includegraphics[width=4.6in]{exta02.eps}
|
| 148 |
|
|
\caption{Example Timed Automaton (Drawbridge Motor Control)}
|
| 149 |
|
|
\label{fig:staf0:stfw0:01}
|
| 150 |
|
|
\end{figure}
|
| 151 |
|
|
|
| 152 |
|
|
Mathematically, the automata of Figs.
|
| 153 |
|
|
\ref{fig:staf0:stfw0:00}
|
| 154 |
|
|
and
|
| 155 |
|
|
\ref{fig:staf0:stfw0:01} can be combined to give the automaton of
|
| 156 |
|
|
Fig. \ref{fig:staf0:stfw0:02}\@. This mathematical operation is sometimes called the
|
| 157 |
|
|
``shuffle'' operation.
|
| 158 |
|
|
|
| 159 |
|
|
\begin{figure}
|
| 160 |
|
|
\centering
|
| 161 |
|
|
\includegraphics[width=4.6in]{exta03.eps}
|
| 162 |
|
|
\caption{Example Timed Automaton (Shuffle of Fig. \ref{fig:staf0:stfw0:00} and Fig. \ref{fig:staf0:stfw0:01})}
|
| 163 |
|
|
\label{fig:staf0:stfw0:02}
|
| 164 |
|
|
\end{figure}
|
| 165 |
|
|
|
| 166 |
|
|
In Fig. \ref{fig:staf0:stfw0:02}, each of the eight discrete states
|
| 167 |
|
|
corresponds to one discrete state from Fig. \ref{fig:staf0:stfw0:00}
|
| 168 |
|
|
and one discrete state from In Fig. \ref{fig:staf0:stfw0:01}.
|
| 169 |
|
|
The initial state $A_{D}B_{IDLE}$ corresponds to the initial state
|
| 170 |
|
|
from In Fig. \ref{fig:staf0:stfw0:00} paired with the initial state
|
| 171 |
|
|
from Fig. \ref{fig:staf0:stfw0:01}.
|
| 172 |
|
|
|
| 173 |
|
|
The noteworthy features of Fig. \ref{fig:staf0:stfw0:02} are:
|
| 174 |
|
|
|
| 175 |
|
|
\begin{itemize}
|
| 176 |
|
|
\item It is the result of a mathematical algorithm applied to
|
| 177 |
|
|
Figs. \ref{fig:staf0:stfw0:00} and \ref{fig:staf0:stfw0:01}.
|
| 178 |
|
|
If the underlying system consisted of more than two automata, the
|
| 179 |
|
|
algorithm could be applied repeatedly to generate a single automaton with
|
| 180 |
|
|
a single large discrete state space.
|
| 181 |
|
|
\item The upper bound on the number of discrete states in the shuffle
|
| 182 |
|
|
of two automata is the product of the number of discrete states
|
| 183 |
|
|
in each. Note, however, that $A_{D}B_{UP}$ and $A_{U}B_{DOWN}$
|
| 184 |
|
|
don't ``truly'' exist. The reason is that the synchronization
|
| 185 |
|
|
mechanisms between the two automata ensure that these states
|
| 186 |
|
|
are instantly exited as soon as they are entered. Thus, a system
|
| 187 |
|
|
of equivalent functionality can be constructed with six discrete
|
| 188 |
|
|
states rather than eight.
|
| 189 |
|
|
\end{itemize}
|
| 190 |
|
|
|
| 191 |
|
|
Although the preceding example is contrived, it illustrates the flavor
|
| 192 |
|
|
of the framework and how separate automata with synchronization mechanisms can be
|
| 193 |
|
|
combined (and perhaps also ``separated'' or ``factored'', \S{}\ref{srin0:star0}).
|
| 194 |
|
|
|
| 195 |
|
|
It should also be apparent that tools can verify a great deal about
|
| 196 |
|
|
the system through symbolic manipulation. Properties that can be verified
|
| 197 |
|
|
include:
|
| 198 |
|
|
|
| 199 |
|
|
\begin{itemize}
|
| 200 |
|
|
\item \emph{Reachability:} it can be symbolically determined whether
|
| 201 |
|
|
or not each state is reachable (the algorithms involve determining
|
| 202 |
|
|
symbolically which values timers can achieve in each discrete state and
|
| 203 |
|
|
comparing that information against transition functions---some transitions
|
| 204 |
|
|
cannot ever be taken).
|
| 205 |
|
|
\item \emph{Liveness:} it can be symbolically determined whether the system
|
| 206 |
|
|
can enter a state where no inputs to the system can cause all of a
|
| 207 |
|
|
set of states to be reachable.
|
| 208 |
|
|
\end{itemize}
|
| 209 |
|
|
|
| 210 |
|
|
The example comes \emph{very} close to the way practical
|
| 211 |
|
|
software systems are constructed. Generally, state machines in
|
| 212 |
|
|
software have transition functions that involve time and the states of
|
| 213 |
|
|
other state machines.
|
| 214 |
|
|
|
| 215 |
|
|
|
| 216 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 217 |
|
|
|
| 218 |
|
|
\subsection{Human Tendencies}
|
| 219 |
|
|
\label{staf0:shtd0}
|
| 220 |
|
|
|
| 221 |
|
|
My experience in industry is that human beings do badly with the
|
| 222 |
|
|
design of stateful controllers. Typical tendencies:
|
| 223 |
|
|
|
| 224 |
|
|
\begin{itemize}
|
| 225 |
|
|
\item \textbf{Bloating of the controller state space:}
|
| 226 |
|
|
\;It is very common for engineers to design a controller with
|
| 227 |
|
|
a discrete state space that is too large. The prototypical
|
| 228 |
|
|
example is an engineer who finds a way to implement a purely combinational
|
| 229 |
|
|
function using sequential logic.
|
| 230 |
|
|
|
| 231 |
|
|
In the most humorous case (purely combinational logic implemented as
|
| 232 |
|
|
sequential logic),
|
| 233 |
|
|
the system usually behaves correctly. Serious software defects
|
| 234 |
|
|
most typically come about through \emph{subtle} design mistakes. A typical software defect
|
| 235 |
|
|
involves two or more software components with some interaction that enter
|
| 236 |
|
|
states such that the software can't recover.
|
| 237 |
|
|
\item \textbf{Inability to comprehend all possible behaviors of the system:}
|
| 238 |
|
|
Very stateful systems tend to be incompatible with human cognitive
|
| 239 |
|
|
ability. Even when the problem is well-defined and when the controller and
|
| 240 |
|
|
plant are operating perfectly, human beings don't do
|
| 241 |
|
|
well at considering every possible behavior.
|
| 242 |
|
|
\item \textbf{Inability to comprehend how the system may behave in the presence
|
| 243 |
|
|
of failures:}
|
| 244 |
|
|
Very stateful systems are often designed to be tolerant of certain types
|
| 245 |
|
|
of sensor and actuator failures (usually in the sense that the failures will
|
| 246 |
|
|
be detected and the system will employ a different algorithm to operate without
|
| 247 |
|
|
a specific sensor or actuator)\@. Such fault detection and tolerance
|
| 248 |
|
|
normally complicates the software design substantially.
|
| 249 |
|
|
|
| 250 |
|
|
However, even without designed-in fault tolerance, there is the need to
|
| 251 |
|
|
design controllers to tolerate the faults that can occur in any practical system.
|
| 252 |
|
|
Specific scenarios that must be tolerated:
|
| 253 |
|
|
|
| 254 |
|
|
\begin{itemize}
|
| 255 |
|
|
\item Spurious reset of the controller (which will normally reset the controller
|
| 256 |
|
|
to its initial state but leave the plant undisturbed). (This directly implies that
|
| 257 |
|
|
the system must recover from the initial state of the controller combined with
|
| 258 |
|
|
any state of the plant.)
|
| 259 |
|
|
\item State upset of the controller (due to electrical noise, internal software errors,
|
| 260 |
|
|
etc.). (This directly implies that the system must recover from any state of
|
| 261 |
|
|
the controller combined with any state of the plant.)
|
| 262 |
|
|
\end{itemize}
|
| 263 |
|
|
|
| 264 |
|
|
Except in simple cases, human beings don't have the cognitive capacity to consider
|
| 265 |
|
|
all possible behaviors when both the controller and the plant may start in any state.
|
| 266 |
|
|
\end{itemize}
|
| 267 |
|
|
|
| 268 |
|
|
One example that comes to mind from product development is an automobile transfer case controller
|
| 269 |
|
|
where it was discovered that if the electrical connector was removed, the transfer case mechanical
|
| 270 |
|
|
components repositioned, and the electrical connection restored; the controller would not
|
| 271 |
|
|
recover into normal operation. Human beings are not good at mentally exploring all possibilities, and even
|
| 272 |
|
|
a disciplined manual process can't be used because the combinations sometimes number in the thousands
|
| 273 |
|
|
or more. A mathematical framework and tool support are required.
|
| 274 |
|
|
|
| 275 |
|
|
|
| 276 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 277 |
|
|
|
| 278 |
|
|
\subsection{Code Generation}
|
| 279 |
|
|
\label{staf0:scgn0}
|
| 280 |
|
|
|
| 281 |
|
|
In most engineering environments, software is generated
|
| 282 |
|
|
from software designs that involve timed automata. (Some of the techniques
|
| 283 |
|
|
used to create compact code are described in \S{}\ref{sfrr0}.)
|
| 284 |
|
|
|
| 285 |
|
|
For some types of systems, there has been success in using
|
| 286 |
|
|
existing tools to generate code directly from the software design
|
| 287 |
|
|
(using tool chains from \emph{The Math Works} or \emph{I-Logix}). It is,
|
| 288 |
|
|
however, known from experience that a clever human programmer can generate
|
| 289 |
|
|
more compact code than any existing tool; so code generation tools have
|
| 290 |
|
|
not penetrated cost-sensitive automotive products involving 32K of FLASH or less.
|
| 291 |
|
|
|
| 292 |
|
|
There are two primary arguments against manual generation of code:
|
| 293 |
|
|
|
| 294 |
|
|
\begin{itemize}
|
| 295 |
|
|
\item Code is redundant with respect to a software design.
|
| 296 |
|
|
In general, it does not make economic sense to maintain redundant
|
| 297 |
|
|
information using human labor.
|
| 298 |
|
|
\item The act of optimizing implementations typically destroys the
|
| 299 |
|
|
clear relationship between design and code. Furthermore, changes
|
| 300 |
|
|
to the design---sometimes even small ones---can invalidate the
|
| 301 |
|
|
mathematical basis for certain optimizations. Optimized code becomes
|
| 302 |
|
|
unmaintainable. It would be more economical to evaluate the viability
|
| 303 |
|
|
of optimizations and to generate code using software tools (rather than
|
| 304 |
|
|
human labor).
|
| 305 |
|
|
\end{itemize}
|
| 306 |
|
|
|
| 307 |
|
|
|
| 308 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 309 |
|
|
|
| 310 |
|
|
\subsection{Formal Verification of Properties}
|
| 311 |
|
|
\label{staf0:svpr0}
|
| 312 |
|
|
|
| 313 |
|
|
Typical design tools provide simulation capability, and there is a large
|
| 314 |
|
|
body of theory and best practice about how to design test cases based on
|
| 315 |
|
|
a stateful design.
|
| 316 |
|
|
|
| 317 |
|
|
Still, the following problems remain:
|
| 318 |
|
|
|
| 319 |
|
|
\begin{itemize}
|
| 320 |
|
|
\item Systems with a large discrete state space elude human
|
| 321 |
|
|
understanding.
|
| 322 |
|
|
\item It is very laborious to test systems with a large discrete
|
| 323 |
|
|
state space.
|
| 324 |
|
|
\item It isn't possible to fully test systems with a large
|
| 325 |
|
|
discrete state space.
|
| 326 |
|
|
\item It is possible (and common) to make a good faith effort at
|
| 327 |
|
|
comprehensively testing systems but still to overlook
|
| 328 |
|
|
unacceptable behavior.
|
| 329 |
|
|
\end{itemize}
|
| 330 |
|
|
|
| 331 |
|
|
\emph{Simulation and testing are not enough.} For complex safety-critical
|
| 332 |
|
|
systems, simulation and testing do not provide enough assurance about the
|
| 333 |
|
|
behavior of the system.
|
| 334 |
|
|
|
| 335 |
|
|
Formal verification of properties would involve making mathematical assertions
|
| 336 |
|
|
about how the system must and must not behave, and then allowing
|
| 337 |
|
|
tools to verify the properties.
|
| 338 |
|
|
|
| 339 |
|
|
Possible types of properties:
|
| 340 |
|
|
|
| 341 |
|
|
\begin{itemize}
|
| 342 |
|
|
\item \emph{Required behavior:}
|
| 343 |
|
|
For example: \emph{When the brake pedal switch is closed,
|
| 344 |
|
|
the brake lights must always come on within 200ms.}
|
| 345 |
|
|
\item \emph{Required absence of behavior:}
|
| 346 |
|
|
For example: \emph{The airbags can never deploy without at least one
|
| 347 |
|
|
body deformation sensor indicating body deformation.}
|
| 348 |
|
|
\item \emph{Liveness:}
|
| 349 |
|
|
For example: \emph{A certain set of states is always reachable by manipulating certain
|
| 350 |
|
|
inputs.}
|
| 351 |
|
|
\end{itemize}
|
| 352 |
|
|
|
| 353 |
|
|
The only tool I'm aware of that allows formal verification of properties
|
| 354 |
|
|
is UPPAAL. However, the modeling framework of
|
| 355 |
|
|
UPPAAL isn't rich enough to support practical embedded systems.\footnote{The
|
| 356 |
|
|
tool chains from \emph{The Math Works} and \emph{I-Logix} don't attempt
|
| 357 |
|
|
formal verification at all.}
|
| 358 |
|
|
|
| 359 |
|
|
I would tend to view formal verification of properties as a last line of defense
|
| 360 |
|
|
against egregious software defects (i.e. as a practice that cannot stand alone)\@.
|
| 361 |
|
|
Formal verification should be combined with all other known
|
| 362 |
|
|
best practices.
|
| 363 |
|
|
|
| 364 |
|
|
|
| 365 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 366 |
|
|
|
| 367 |
|
|
\section{FLASH/ROM Reduction Techniques}
|
| 368 |
|
|
\label{sfrr0}
|
| 369 |
|
|
|
| 370 |
|
|
In this section, I mention some of the FLASH/ROM reduction techniques
|
| 371 |
|
|
used by human programmers. Important points:
|
| 372 |
|
|
|
| 373 |
|
|
\begin{itemize}
|
| 374 |
|
|
\item All of the techniques have a mathematical basis.
|
| 375 |
|
|
\item The techniques are complex to apply and best carried out by tools.
|
| 376 |
|
|
\item The mathematical basis of the techniques is non-trivial. There are
|
| 377 |
|
|
many unexplored corners.
|
| 378 |
|
|
\item The techniques distort the correspondence (i.e. the resemblance)
|
| 379 |
|
|
between design and code, and make code unmaintainable (it would be
|
| 380 |
|
|
better only to generate code from designs and never to maintain
|
| 381 |
|
|
code directly).
|
| 382 |
|
|
\end{itemize}
|
| 383 |
|
|
|
| 384 |
|
|
The list of techniques presented is not exhaustive (far more techniques
|
| 385 |
|
|
exist).
|
| 386 |
|
|
|
| 387 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 388 |
|
|
|
| 389 |
|
|
\subsection{General Paradigm of Software Construction for Small Microcontrollers}
|
| 390 |
|
|
\label{sfrr0:sgsc0}
|
| 391 |
|
|
|
| 392 |
|
|
This discussion is confined entirely to systems where a stateful design is
|
| 393 |
|
|
implemented directly as code (with no tabulation or compression of the design).
|
| 394 |
|
|
Other paradigms are possible. For example, at least one tool on the market implements
|
| 395 |
|
|
stateful designs as state transition tables that are evaluated at runtime by
|
| 396 |
|
|
a table interpreter. My experience with these types of systems is that there
|
| 397 |
|
|
is always a real-time performance penalty (but certainly not always a
|
| 398 |
|
|
FLASH penalty). My research interests do also include event-driven systems
|
| 399 |
|
|
and systems where the design is not implemented directly as code; but these
|
| 400 |
|
|
systems are not mentioned for brevity.
|
| 401 |
|
|
|
| 402 |
|
|
The most common paradigm for small systems is ``\emph{a collection of cooperating
|
| 403 |
|
|
timed automatons}''. The most typical abstraction of these systems is a data-flow
|
| 404 |
|
|
diagram, with RAM variables (i.e. global variables) used as the interfaces.
|
| 405 |
|
|
|
| 406 |
|
|
There is a body of theory and best practice about what separates good software designs
|
| 407 |
|
|
and implementations from bad (Parnas and the classic coupling and cohesion spectrums
|
| 408 |
|
|
come to mind). However, in small systems, it simply isn't possible to
|
| 409 |
|
|
implement the systems using classic ``good'' programming practice---formal parameters,
|
| 410 |
|
|
pointer dereferencing, and access to variables in stack frames all bloat
|
| 411 |
|
|
FLASH size under the weak instruction sets typical of small microcontrollers.
|
| 412 |
|
|
|
| 413 |
|
|
It is helpful to take a step back and consider the possibility that global variables
|
| 414 |
|
|
(the second-strongest form of coupling in the classic coupling spectrum) aren't
|
| 415 |
|
|
inherently harmful; but rather that it is the way in which global variables are
|
| 416 |
|
|
typically used that causes harm. The harmful aspects of global variables
|
| 417 |
|
|
seem to be:
|
| 418 |
|
|
|
| 419 |
|
|
\begin{itemize}
|
| 420 |
|
|
\item If global variables are tested \emph{and assigned} in more than place,
|
| 421 |
|
|
the variable actually becomes an automaton and adds to the
|
| 422 |
|
|
state space of the system.
|
| 423 |
|
|
\item Global variables lead to unrestrained connectivity: \emph{any}
|
| 424 |
|
|
software component can access the variables. Additionally,
|
| 425 |
|
|
state is not ``shed'' as functions return (as happens with formal
|
| 426 |
|
|
parameters and local variables)\@. This leads to connectivity
|
| 427 |
|
|
that often skips levels of the calling tree (making it very
|
| 428 |
|
|
difficult to understand the software).
|
| 429 |
|
|
\end{itemize}
|
| 430 |
|
|
|
| 431 |
|
|
Small systems often have design rules to mitigate the harmful aspects of
|
| 432 |
|
|
global variables. The design rules tend to involve these restrictions:
|
| 433 |
|
|
|
| 434 |
|
|
\begin{itemize}
|
| 435 |
|
|
\item A global variable used as an interface can be assigned by only one
|
| 436 |
|
|
software component (a 1-writer, $n$-reader restriction).
|
| 437 |
|
|
\item A global variable used as an interface has its readers/writers
|
| 438 |
|
|
represented in design documentation (so that the connectivity
|
| 439 |
|
|
created by the global variable isn't accidental or unrestrained).
|
| 440 |
|
|
\end{itemize}
|
| 441 |
|
|
|
| 442 |
|
|
The design rules typically also include provisions for global variables
|
| 443 |
|
|
used as interfaces that are tested and assigned by more than one software
|
| 444 |
|
|
component (i.e. interface automatons). The simplest example of such an
|
| 445 |
|
|
interface is a semaphore that is
|
| 446 |
|
|
set \emph{T} by one software component and tested and set \emph{F} by
|
| 447 |
|
|
another software component, but the design rules are far more general.
|
| 448 |
|
|
|
| 449 |
|
|
Note that tools can be used to allow a system to be phrased in a way
|
| 450 |
|
|
consistent with the traditional coupling spectrum but implemented
|
| 451 |
|
|
efficiently for small microcontrollers. For example, some compilers
|
| 452 |
|
|
are able to analyze the calling tree and place variables of storage
|
| 453 |
|
|
class \emph{automatic} into statically overlaid\footnote{Statically overlaid
|
| 454 |
|
|
based on the calling tree: one function's automatic variables can be overlaid
|
| 455 |
|
|
with another only if an analysis of the calling tree determines that
|
| 456 |
|
|
the two functions cannot be active at the same time.} areas of memory rather than
|
| 457 |
|
|
in a stack frame. Similar tool support could be developed for the notion of
|
| 458 |
|
|
\emph{automatic} bitfields and to restrain the connectivity introduced
|
| 459 |
|
|
by global variables to be consistent with the product design.
|
| 460 |
|
|
|
| 461 |
|
|
|
| 462 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 463 |
|
|
|
| 464 |
|
|
\subsection{Near versus Far (Addressing Modes)}
|
| 465 |
|
|
\label{sfrr0:snvf0}
|
| 466 |
|
|
|
| 467 |
|
|
Most small microcontrollers (TMS370C8, 68HC05, etc.) have two
|
| 468 |
|
|
non-indexed addressing modes, typically called \emph{direct} and
|
| 469 |
|
|
\emph{extended}. Instructions using the direct addressing mode typically
|
| 470 |
|
|
have the address encoded as a single byte, and can address only locations
|
| 471 |
|
|
\$00 through \$FF\@. Instructions using the extended addressing mode
|
| 472 |
|
|
typically have the address encoded as two bytes, and can address
|
| 473 |
|
|
locations \$0000 through \$FFFF.
|
| 474 |
|
|
|
| 475 |
|
|
For lack of better nomenclature, I'll call the RAM locations that can be addressed
|
| 476 |
|
|
using short instructions \emph{near} RAM, and the RAM locations that require
|
| 477 |
|
|
long instructions \emph{far} RAM.
|
| 478 |
|
|
|
| 479 |
|
|
When fixed RAM locations are used as interfaces (\S{}\ref{sfrr0:sgsc0}),
|
| 480 |
|
|
one can save substantial FLASH by allocating the variables that are
|
| 481 |
|
|
referenced most often throughout the software into near RAM.
|
| 482 |
|
|
|
| 483 |
|
|
In automotive software, variables such as gearshift position and vehicle speed
|
| 484 |
|
|
are typically referenced many times throughout FLASH. Most programmers
|
| 485 |
|
|
would automatically place these into near RAM.
|
| 486 |
|
|
|
| 487 |
|
|
However, for most variables, it isn't obvious whether these should be placed
|
| 488 |
|
|
into near or far RAM.
|
| 489 |
|
|
|
| 490 |
|
|
Software developers often write small utility programs to scan all software
|
| 491 |
|
|
modules to determine the number of references to each variable. This information
|
| 492 |
|
|
is then used to allocate the variables with the most references into near RAM.
|
| 493 |
|
|
|
| 494 |
|
|
The FLASH savings from using this technique is typically large. As an example,
|
| 495 |
|
|
assume there are ten variables each referenced 50 times throughout the software.
|
| 496 |
|
|
The savings of placing these variables into near RAM versus far RAM is
|
| 497 |
|
|
typically about $50 \times 10 = 500$ bytes of FLASH (more than 1\% of a
|
| 498 |
|
|
32K FLASH).
|
| 499 |
|
|
|
| 500 |
|
|
|
| 501 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 502 |
|
|
|
| 503 |
|
|
\subsection{Treatment of Time}
|
| 504 |
|
|
\label{sfrr0:stot0}
|
| 505 |
|
|
|
| 506 |
|
|
The way that time is measured is usually the single most important decision
|
| 507 |
|
|
in a small embedded system. Typically, many software components have to
|
| 508 |
|
|
measure time intervals, so a suboptimal decision about the mechanisms
|
| 509 |
|
|
greatly increases FLASH consumption.
|
| 510 |
|
|
|
| 511 |
|
|
The best mechanism known is to arrange all software timers into
|
| 512 |
|
|
binary decades and to decrement the timers en masse
|
| 513 |
|
|
(Fig. \ref{fig:sfrr0:stot0:00}).
|
| 514 |
|
|
|
| 515 |
|
|
\begin{figure}
|
| 516 |
|
|
\begin{small}
|
| 517 |
|
|
\begin{verbatim}
|
| 518 |
|
|
unsigned char modulo_counter;
|
| 519 |
|
|
unsigned char timers_modulo_1[MOD1_COUNT];
|
| 520 |
|
|
unsigned char timers_modulo_2[MOD2_COUNT];
|
| 521 |
|
|
unsigned char timers_modulo_4[MOD4_COUNT];
|
| 522 |
|
|
|
| 523 |
|
|
void decrement_timers(void)
|
| 524 |
|
|
{
|
| 525 |
|
|
int i;
|
| 526 |
|
|
|
| 527 |
|
|
modulo_counter++;
|
| 528 |
|
|
|
| 529 |
|
|
for (i=0; i<sizeof(timers_modulo_1)/sizeof(timers_modulo_1[0]); i++)
|
| 530 |
|
|
{
|
| 531 |
|
|
if (timers_modulo_1[i])
|
| 532 |
|
|
timers_modulo_1[i]--;
|
| 533 |
|
|
}
|
| 534 |
|
|
|
| 535 |
|
|
if (modulo_counter & 0x01)
|
| 536 |
|
|
{
|
| 537 |
|
|
for (i=0; i<sizeof(timers_modulo_2)/sizeof(timers_modulo_2[0]); i++)
|
| 538 |
|
|
{
|
| 539 |
|
|
if (timers_modulo_2[i])
|
| 540 |
|
|
timers_modulo_2[i]--;
|
| 541 |
|
|
}
|
| 542 |
|
|
}
|
| 543 |
|
|
|
| 544 |
|
|
if (modulo_counter & 0x02)
|
| 545 |
|
|
{
|
| 546 |
|
|
for (i=0; i<sizeof(timers_modulo_4)/sizeof(timers_modulo_4[0]); i++)
|
| 547 |
|
|
{
|
| 548 |
|
|
if (timers_modulo_4[i])
|
| 549 |
|
|
timers_modulo_4[i]--;
|
| 550 |
|
|
}
|
| 551 |
|
|
}
|
| 552 |
|
|
}
|
| 553 |
|
|
\end{verbatim}
|
| 554 |
|
|
\end{small}
|
| 555 |
|
|
\caption{Software Timers Decremented En Masse}
|
| 556 |
|
|
\label{fig:sfrr0:stot0:00}
|
| 557 |
|
|
\end{figure}
|
| 558 |
|
|
|
| 559 |
|
|
When software components must measure time, a byte
|
| 560 |
|
|
(\texttt{timers\_modulo\_4[2]}, for example) is set to a non-zero value.
|
| 561 |
|
|
A separate software component, usually resembling Fig. \ref{fig:sfrr0:stot0:00} but often
|
| 562 |
|
|
implemented in assembly-language,
|
| 563 |
|
|
decrements the byte, but not below zero.
|
| 564 |
|
|
A test against zero will determine if the time period has expired.
|
| 565 |
|
|
|
| 566 |
|
|
The single-byte mechanism combined with binary decades allows any time period
|
| 567 |
|
|
to be measured within 1:128. For example, assume that the binary decades are
|
| 568 |
|
|
$2^q \times 1ms$ (1ms, 2ms, 4ms, etc.) and then that
|
| 569 |
|
|
we wish to measure a time period of 30 minutes. Then
|
| 570 |
|
|
|
| 571 |
|
|
\begin{equation}
|
| 572 |
|
|
255 (2^q) \geq 1,800,000
|
| 573 |
|
|
\end{equation}
|
| 574 |
|
|
|
| 575 |
|
|
\begin{equation}
|
| 576 |
|
|
q = \left\lceil \log_2 \frac{1,800,000}{255} \right\rceil = 13
|
| 577 |
|
|
\end{equation}
|
| 578 |
|
|
|
| 579 |
|
|
A timer resolution of $2^{13} = 8,192$ms with a count of 219 or 220 would in practice be used.
|
| 580 |
|
|
For most automotive applications, measuring 30 minutes within 8 seconds is acceptable.
|
| 581 |
|
|
|
| 582 |
|
|
It is noteworthy that using coarse software timers introduces nondeterminism
|
| 583 |
|
|
into the system (although I've never seen a problem in practice) and probably requires
|
| 584 |
|
|
some adjustment to timed automata algorithms used for verification of properties.
|
| 585 |
|
|
|
| 586 |
|
|
|
| 587 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 588 |
|
|
|
| 589 |
|
|
\subsection{Bitfields of Size One}
|
| 590 |
|
|
\label{sfrr0:sbfi0}
|
| 591 |
|
|
|
| 592 |
|
|
Many small microcontrollers possess extremely efficient instructions
|
| 593 |
|
|
for clearing, setting, and testing individual bits of RAM (especially near
|
| 594 |
|
|
bits). It isn't uncommon for a microcontroller to have an instruction that
|
| 595 |
|
|
will test a bit and conditionally branch.
|
| 596 |
|
|
|
| 597 |
|
|
Note that economies apply only to bitfields of size one. Bitfields of
|
| 598 |
|
|
other sizes require the compiler to mask and shift to obtain the value of the
|
| 599 |
|
|
bitfield, then to shift and mask to store the value back.
|
| 600 |
|
|
|
| 601 |
|
|
The economy of bitfields of size one has several implications for the construction
|
| 602 |
|
|
of embedded software.
|
| 603 |
|
|
|
| 604 |
|
|
\begin{itemize}
|
| 605 |
|
|
\item Variables that are conceptually Boolean should never be
|
| 606 |
|
|
maintained as full bytes. Bitfields are more efficient, both
|
| 607 |
|
|
in FLASH and RAM.
|
| 608 |
|
|
\item In many cases, it is most efficient to maintain discrete state as
|
| 609 |
|
|
bitfields rather than as a byte. A state machine with three
|
| 610 |
|
|
discrete states is often most effectively implemented as two
|
| 611 |
|
|
bitfields with state assignments 0/0, 0/1, and 1/X.
|
| 612 |
|
|
\item It is often most effective to evaluate common Boolean subexpressions and store
|
| 613 |
|
|
the results in bitfields (\S{}\ref{sfrr0:scse0}).
|
| 614 |
|
|
\end{itemize}
|
| 615 |
|
|
|
| 616 |
|
|
|
| 617 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 618 |
|
|
|
| 619 |
|
|
\subsection{Equivalence Classing of Discrete States}
|
| 620 |
|
|
\label{sfrr0:secd0}
|
| 621 |
|
|
|
| 622 |
|
|
The most obvious way to construct a state machine in software is shown in
|
| 623 |
|
|
Fig. \ref{fig:sfrr0:secd0:00}. Discrete state is maintained
|
| 624 |
|
|
as a byte, and each state has a value $\in \{0, \ldots{}, 255\}$.
|
| 625 |
|
|
|
| 626 |
|
|
\begin{figure}
|
| 627 |
|
|
\begin{small}
|
| 628 |
|
|
\begin{verbatim}
|
| 629 |
|
|
switch (state)
|
| 630 |
|
|
{
|
| 631 |
|
|
default:
|
| 632 |
|
|
case 0:
|
| 633 |
|
|
{
|
| 634 |
|
|
if (some_transition_condition)
|
| 635 |
|
|
{
|
| 636 |
|
|
state = 1;
|
| 637 |
|
|
}
|
| 638 |
|
|
break;
|
| 639 |
|
|
}
|
| 640 |
|
|
case 1:
|
| 641 |
|
|
{
|
| 642 |
|
|
if (some_other_transition_condition)
|
| 643 |
|
|
{
|
| 644 |
|
|
state = 0;
|
| 645 |
|
|
}
|
| 646 |
|
|
break;
|
| 647 |
|
|
}
|
| 648 |
|
|
case 2:
|
| 649 |
|
|
{
|
| 650 |
|
|
...
|
| 651 |
|
|
break;
|
| 652 |
|
|
}
|
| 653 |
|
|
}
|
| 654 |
|
|
\end{verbatim}
|
| 655 |
|
|
\end{small}
|
| 656 |
|
|
\caption{Most Obvious Construction of State Machine in Software}
|
| 657 |
|
|
\label{fig:sfrr0:secd0:00}
|
| 658 |
|
|
\end{figure}
|
| 659 |
|
|
|
| 660 |
|
|
The shortcoming of the approach shown in Fig. \ref{fig:sfrr0:secd0:00} is that
|
| 661 |
|
|
state machines are often accompanied by:
|
| 662 |
|
|
|
| 663 |
|
|
\begin{itemize}
|
| 664 |
|
|
\item Combinational logic that implements combinational functions involving
|
| 665 |
|
|
the discrete state of the state machine being considered.
|
| 666 |
|
|
\item Transition functions in other state machines that depend on the discrete
|
| 667 |
|
|
state of the state machine being considered.
|
| 668 |
|
|
\end{itemize}
|
| 669 |
|
|
|
| 670 |
|
|
|
| 671 |
|
|
\begin{figure}
|
| 672 |
|
|
\begin{small}
|
| 673 |
|
|
\begin{verbatim}
|
| 674 |
|
|
if (
|
| 675 |
|
|
(state == 0) || (state == 13) || (state == 18) || (state == 30)
|
| 676 |
|
|
|| (state == 31) || (state == 51) || (state == 99)
|
| 677 |
|
|
)
|
| 678 |
|
|
\end{verbatim}
|
| 679 |
|
|
\end{small}
|
| 680 |
|
|
\caption{Typical Test for Membership in a Set of Discrete States}
|
| 681 |
|
|
\label{fig:sfrr0:secd0:01}
|
| 682 |
|
|
\end{figure}
|
| 683 |
|
|
|
| 684 |
|
|
This can often lead to tests of the form shown in
|
| 685 |
|
|
Fig. \ref{fig:sfrr0:secd0:01}.
|
| 686 |
|
|
Such tests are very expensive, both in FLASH consumption and in execution time.
|
| 687 |
|
|
A typical compiler must generate many compare instructions.
|
| 688 |
|
|
|
| 689 |
|
|
One can make the observation that there are many machine instructions that
|
| 690 |
|
|
create equivalence classes within $\mathbb{Z}^+$:
|
| 691 |
|
|
|
| 692 |
|
|
\begin{itemize}
|
| 693 |
|
|
\item An \emph{AND \#1} instruction may create equivalence classes such as
|
| 694 |
|
|
\{0, 2, 4, \ldots{}\} versus \{1, 3, 5, \ldots{}\}. Other \emph{AND} instructions
|
| 695 |
|
|
can create more complex equivalence classes.
|
| 696 |
|
|
\item A \emph{CMP \#n} instruction usually creates three equivalence classes: the integers less than $n$,
|
| 697 |
|
|
$n$, and the integers greater than $n$.
|
| 698 |
|
|
\item There are other machine instructions that create different equivalence classes.
|
| 699 |
|
|
\end{itemize}
|
| 700 |
|
|
|
| 701 |
|
|
The critical question is whether one can assign discrete state values so as to
|
| 702 |
|
|
make the best utilization of the equivalence classes that machine instructions
|
| 703 |
|
|
naturally create. For example, if a test for 10 distinct discrete states occurs
|
| 704 |
|
|
many places in the software, it would make sense to try to assign these
|
| 705 |
|
|
state values so that they are part of an equivalence class that can be
|
| 706 |
|
|
identified immediately by one or two machine instructions.
|
| 707 |
|
|
|
| 708 |
|
|
It should be obvious that if many different tests of discrete state are involved,
|
| 709 |
|
|
identifying an optimal or near-optimal assignment of discrete state values and
|
| 710 |
|
|
the accompanying tests would be very difficult to do by hand. This type of
|
| 711 |
|
|
optimization is best done by software tools.
|
| 712 |
|
|
|
| 713 |
|
|
|
| 714 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 715 |
|
|
|
| 716 |
|
|
\subsection{Ordering of Transition Functions}
|
| 717 |
|
|
\label{sfrr0:sotf0}
|
| 718 |
|
|
|
| 719 |
|
|
It often happens that transition functions have common subexpressions.
|
| 720 |
|
|
For example, consider the code snippet in Fig. \ref{fig:sfrr0:sotf0:00}.
|
| 721 |
|
|
The subexpression ``\texttt{A \&\& B}'' is common to both transitions
|
| 722 |
|
|
out of State 0.
|
| 723 |
|
|
|
| 724 |
|
|
\begin{figure}
|
| 725 |
|
|
\begin{small}
|
| 726 |
|
|
\begin{verbatim}
|
| 727 |
|
|
switch (state)
|
| 728 |
|
|
{
|
| 729 |
|
|
default:
|
| 730 |
|
|
case 0:
|
| 731 |
|
|
{
|
| 732 |
|
|
if (A && B && C)
|
| 733 |
|
|
{
|
| 734 |
|
|
state = 1;
|
| 735 |
|
|
}
|
| 736 |
|
|
else if (A && B && !D)
|
| 737 |
|
|
{
|
| 738 |
|
|
state = 2;
|
| 739 |
|
|
}
|
| 740 |
|
|
break;
|
| 741 |
|
|
}
|
| 742 |
|
|
case 1:
|
| 743 |
|
|
{
|
| 744 |
|
|
...
|
| 745 |
|
|
break;
|
| 746 |
|
|
}
|
| 747 |
|
|
case 2:
|
| 748 |
|
|
{
|
| 749 |
|
|
...
|
| 750 |
|
|
break;
|
| 751 |
|
|
}
|
| 752 |
|
|
}
|
| 753 |
|
|
\end{verbatim}
|
| 754 |
|
|
\end{small}
|
| 755 |
|
|
\caption{State Machine Before Control Flow Removal of Common Subexpression}
|
| 756 |
|
|
\label{fig:sfrr0:sotf0:00}
|
| 757 |
|
|
\end{figure}
|
| 758 |
|
|
|
| 759 |
|
|
The code can be optimized to evaluate this subexpression only once
|
| 760 |
|
|
(Fig. \ref{fig:sfrr0:sotf0:01}).
|
| 761 |
|
|
|
| 762 |
|
|
\begin{figure}
|
| 763 |
|
|
\begin{small}
|
| 764 |
|
|
\begin{verbatim}
|
| 765 |
|
|
switch (state)
|
| 766 |
|
|
{
|
| 767 |
|
|
default:
|
| 768 |
|
|
case 0:
|
| 769 |
|
|
{
|
| 770 |
|
|
if (A && B)
|
| 771 |
|
|
{
|
| 772 |
|
|
if (C)
|
| 773 |
|
|
{
|
| 774 |
|
|
state = 1;
|
| 775 |
|
|
}
|
| 776 |
|
|
else if (!D)
|
| 777 |
|
|
{
|
| 778 |
|
|
state = 2;
|
| 779 |
|
|
}
|
| 780 |
|
|
}
|
| 781 |
|
|
break;
|
| 782 |
|
|
}
|
| 783 |
|
|
case 1:
|
| 784 |
|
|
{
|
| 785 |
|
|
...
|
| 786 |
|
|
break;
|
| 787 |
|
|
}
|
| 788 |
|
|
case 2:
|
| 789 |
|
|
{
|
| 790 |
|
|
...
|
| 791 |
|
|
break;
|
| 792 |
|
|
}
|
| 793 |
|
|
}
|
| 794 |
|
|
\end{verbatim}
|
| 795 |
|
|
\end{small}
|
| 796 |
|
|
\caption{State Machine After Control Flow Removal of Common Subexpression}
|
| 797 |
|
|
\label{fig:sfrr0:sotf0:01}
|
| 798 |
|
|
\end{figure}
|
| 799 |
|
|
|
| 800 |
|
|
In the trivial case presented, it is easy to identify the subexpression
|
| 801 |
|
|
and rearrange the code so that it is evaluated only once. However, more complex cases
|
| 802 |
|
|
involve logical implication; i.e. there is not an identifiable subexpression, but there
|
| 803 |
|
|
is still a way to rearrange the code for better efficiency. Such analysis is
|
| 804 |
|
|
best done by software tools.
|
| 805 |
|
|
|
| 806 |
|
|
|
| 807 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 808 |
|
|
|
| 809 |
|
|
\subsection{Common Subexpression Elimination}
|
| 810 |
|
|
\label{sfrr0:scse0}
|
| 811 |
|
|
|
| 812 |
|
|
It often occurs that the same subexpression appears in transition functions from
|
| 813 |
|
|
more than one discrete state. It can be economical to rearrange the
|
| 814 |
|
|
code to evaluate such subexpressions
|
| 815 |
|
|
only once. Two approaches occur in practice:
|
| 816 |
|
|
|
| 817 |
|
|
\begin{itemize}
|
| 818 |
|
|
\item The subexpression is evaluated once, regardless of discrete state, and the
|
| 819 |
|
|
result is placed in a temporary variable (often a bitfield if the expression
|
| 820 |
|
|
has a Boolean result).
|
| 821 |
|
|
\item The evaluation of the subexpression is implemented as a subroutine, and
|
| 822 |
|
|
the subroutine is called from more than one transition function.
|
| 823 |
|
|
\end{itemize}
|
| 824 |
|
|
|
| 825 |
|
|
Each of these two approaches has advantages and disadvantages.
|
| 826 |
|
|
|
| 827 |
|
|
Identifying common subexpressions and deciding how to eliminate the FLASH
|
| 828 |
|
|
penalty associated with duplicated code is a tedious task and best done
|
| 829 |
|
|
by software tools.
|
| 830 |
|
|
|
| 831 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 832 |
|
|
|
| 833 |
|
|
\subsection{Farey Series Approximations}
|
| 834 |
|
|
\label{sfrr0:sfsa0}
|
| 835 |
|
|
|
| 836 |
|
|
Many modern microcontrollers have an efficient integer multiplication
|
| 837 |
|
|
instruction, and some also have an efficient integer division instruction.
|
| 838 |
|
|
Fixed-point arithmetic is the norm in small microcontroller work, and it
|
| 839 |
|
|
is common to want to approximate functions of the form
|
| 840 |
|
|
|
| 841 |
|
|
\begin{equation}
|
| 842 |
|
|
y = r_I x
|
| 843 |
|
|
\end{equation}
|
| 844 |
|
|
|
| 845 |
|
|
\noindent{}with $r_I \in \mathbb{R}^+$ and $x,y \in \mathbb{Z}^+$. $r_I$ is the
|
| 846 |
|
|
``ideal'' scaling factor, which may be irrational.
|
| 847 |
|
|
|
| 848 |
|
|
If the processor has an integer multiplication instruction but no division
|
| 849 |
|
|
instruction, it is usually most effective to choose
|
| 850 |
|
|
|
| 851 |
|
|
\begin{equation}
|
| 852 |
|
|
r_A = \frac{h}{2^q} \approx r_I,
|
| 853 |
|
|
\end{equation}
|
| 854 |
|
|
|
| 855 |
|
|
\noindent{}with the division by a power of two implemented via a right shift.
|
| 856 |
|
|
|
| 857 |
|
|
However, if the processor also has an integer division instruction, we may choose
|
| 858 |
|
|
|
| 859 |
|
|
\begin{equation}
|
| 860 |
|
|
r_A = \frac{h}{k} \approx r_I,
|
| 861 |
|
|
\end{equation}
|
| 862 |
|
|
|
| 863 |
|
|
\noindent{}with $k$ not required to be a power of two. The specific function
|
| 864 |
|
|
implemented is usually
|
| 865 |
|
|
|
| 866 |
|
|
\begin{equation}
|
| 867 |
|
|
y = \left\lfloor \frac{hx}{k} \right\rfloor ,
|
| 868 |
|
|
\end{equation}
|
| 869 |
|
|
|
| 870 |
|
|
\noindent{}or perhaps
|
| 871 |
|
|
|
| 872 |
|
|
\begin{equation}
|
| 873 |
|
|
y = \left\lfloor \frac{hx + z}{k} \right\rfloor ,
|
| 874 |
|
|
\end{equation}
|
| 875 |
|
|
|
| 876 |
|
|
\noindent{}where $z \in \mathbb{Z}$ is used to shift the result so as to
|
| 877 |
|
|
provide a tighter bound on the error introduced due to truncation of the
|
| 878 |
|
|
division.
|
| 879 |
|
|
|
| 880 |
|
|
$h$ and $k$ are constrained by the sizes of operands accepted by the
|
| 881 |
|
|
machine instructions ($h \leq h_{MAX}$ and $k \leq k_{MAX}$).
|
| 882 |
|
|
There is an algorithm from number theory (involving Farey series and
|
| 883 |
|
|
continued fractions) that will allow the selection of $h$ and $k$ subject
|
| 884 |
|
|
to the constraints. The algorithm is $O(\log N)$ and so can be applied
|
| 885 |
|
|
to find best rational approximations even for processors that accommodate
|
| 886 |
|
|
32- or 64-bit operands.\footnote{The computational complexity of the algorithm is
|
| 887 |
|
|
a significant point, as $2^{64}$ (or $2^{128}$) is a very large number.}
|
| 888 |
|
|
|
| 889 |
|
|
For example, the best rational approximation to $\pi$ with
|
| 890 |
|
|
numerator and denominator not exceeding $2^{16}-1$ is 65,298/20,785\@.
|
| 891 |
|
|
On a processor with a 16-bit $\times$ 16-bit multiplication instruction and a
|
| 892 |
|
|
32-bit / 16-bit division instruction, one can approximate
|
| 893 |
|
|
|
| 894 |
|
|
\begin{equation}
|
| 895 |
|
|
y = \pi x
|
| 896 |
|
|
\end{equation}
|
| 897 |
|
|
|
| 898 |
|
|
\noindent{}with
|
| 899 |
|
|
|
| 900 |
|
|
\begin{equation}
|
| 901 |
|
|
y = \left\lfloor \frac{65,\!298 x}{20,\!785} \right\rfloor
|
| 902 |
|
|
\end{equation}
|
| 903 |
|
|
|
| 904 |
|
|
\noindent{}very efficiently (typically 2-4 machine instructions).
|
| 905 |
|
|
|
| 906 |
|
|
|
| 907 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 908 |
|
|
|
| 909 |
|
|
\subsection{Vertical Counters}
|
| 910 |
|
|
\label{sfrr0:svcn0}
|
| 911 |
|
|
|
| 912 |
|
|
The traditional arrangement for sequential logic is a
|
| 913 |
|
|
\texttt{switch()} statement (this might also be called
|
| 914 |
|
|
a ``horizontal'' counter). However, in some applications that must
|
| 915 |
|
|
implement many identical sequential mappings, it is
|
| 916 |
|
|
efficient to arrange the state vector so that the state of each sequential
|
| 917 |
|
|
mapping consists of a bit in the same position from several bytes. This
|
| 918 |
|
|
is called a ``vertical'' counter.\footnote{It is suspected that the nomenclature
|
| 919 |
|
|
\emph{vertical counter} comes about because if one arranges the 0s and 1s of
|
| 920 |
|
|
bytes horizontally, the state of an individual sequential machine consists
|
| 921 |
|
|
of a vertical row of bits.}
|
| 922 |
|
|
|
| 923 |
|
|
An example of a vertical counter application is 3/3 debouncing---a filtering
|
| 924 |
|
|
function where a discrete input must be in the same state for 3 consecutive
|
| 925 |
|
|
instants of discrete time before the output may change to that state.
|
| 926 |
|
|
|
| 927 |
|
|
If $A$ is the most recent sample, $B$ is the next-most-recent sample,
|
| 928 |
|
|
$C$ is the oldest sample, and $O$ is the output (assumed maintained
|
| 929 |
|
|
as a RAM location) Fig. \ref{fig:sfrr0:svcn0:00}
|
| 930 |
|
|
supplies the Karnaugh map for 3/3
|
| 931 |
|
|
debouncing.
|
| 932 |
|
|
|
| 933 |
|
|
\begin{figure}
|
| 934 |
|
|
\centering
|
| 935 |
|
|
\includegraphics[height=2.0in]{kmap33db.eps}
|
| 936 |
|
|
\caption{Karnaugh Map Of 3/3 Debouncing}
|
| 937 |
|
|
\label{fig:sfrr0:svcn0:00}
|
| 938 |
|
|
\end{figure}
|
| 939 |
|
|
|
| 940 |
|
|
It can be seen from the figure that the expression for the output is
|
| 941 |
|
|
|
| 942 |
|
|
\begin{equation}
|
| 943 |
|
|
\label{eq:sfrr0:svcn0:01}
|
| 944 |
|
|
ABC + AO + BO + CO = ABC + O(A + B + C).
|
| 945 |
|
|
\end{equation}
|
| 946 |
|
|
|
| 947 |
|
|
Intuitively, (\ref{eq:sfrr0:svcn0:01}) makes sense---the output
|
| 948 |
|
|
will be unconditionally \emph{T} if all three of the most recent samples
|
| 949 |
|
|
are \emph{T}
|
| 950 |
|
|
($ABC$). The output will also be \emph{T} if the previous output was \emph{T}
|
| 951 |
|
|
and at least one of the most recent samples are \emph{T} [$O(A+B+C)$]---at least
|
| 952 |
|
|
one \emph{T} recent sample blocks the output from transition to \emph{F}.
|
| 953 |
|
|
|
| 954 |
|
|
Figure \ref{fig:sfrr0:svcn0:01} supplies the C-language
|
| 955 |
|
|
code to implement 3/3 debouncing as a vertical mapping.
|
| 956 |
|
|
A C-compiler will typically implement this code very directly
|
| 957 |
|
|
using the bitwise logical instructions of the machine.
|
| 958 |
|
|
|
| 959 |
|
|
\begin{figure}
|
| 960 |
|
|
\begin{verbatim}
|
| 961 |
|
|
/**************************************************************/
|
| 962 |
|
|
/* Assume: */
|
| 963 |
|
|
/* A : Most recent sample (i.e. at t(0)), arranged as */
|
| 964 |
|
|
/* a group of 8 bits. */
|
| 965 |
|
|
/* B : Next most recent sample t(-1). */
|
| 966 |
|
|
/* C : Oldest sample t(-2). */
|
| 967 |
|
|
/* output : Debounced collection of 8 bits presented to */
|
| 968 |
|
|
/* software internals. Note that this is both */
|
| 969 |
|
|
/* an input (to the combinational mapping) and */
|
| 970 |
|
|
/* the new result. */
|
| 971 |
|
|
/**************************************************************/
|
| 972 |
|
|
|
| 973 |
|
|
output = (A & B & C) | (output & (A | B | C));
|
| 974 |
|
|
|
| 975 |
|
|
/* End of code. */
|
| 976 |
|
|
\end{verbatim}
|
| 977 |
|
|
\caption{C-Language Implementation Of 3/3 Debouncing}
|
| 978 |
|
|
\label{fig:sfrr0:svcn0:01}
|
| 979 |
|
|
\end{figure}
|
| 980 |
|
|
|
| 981 |
|
|
|
| 982 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 983 |
|
|
|
| 984 |
|
|
\section{Research Interests}
|
| 985 |
|
|
\label{srin0}
|
| 986 |
|
|
|
| 987 |
|
|
This section enumerates my specific research interests.
|
| 988 |
|
|
|
| 989 |
|
|
|
| 990 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 991 |
|
|
|
| 992 |
|
|
\subsection{Mathematical Properties of Timed Automata Systems}
|
| 993 |
|
|
\label{srin0:star0}
|
| 994 |
|
|
|
| 995 |
|
|
I have interest in the mathematical properties of timed automata systems,
|
| 996 |
|
|
including these questions:
|
| 997 |
|
|
|
| 998 |
|
|
\begin{itemize}
|
| 999 |
|
|
\item Can these systems be rearranged (independent of code generation) for more
|
| 1000 |
|
|
efficient implementation? Is there some canonical form?
|
| 1001 |
|
|
\item Can an automaton be ``factored'' into components (i.e. the reverse
|
| 1002 |
|
|
operation of ``shuffle'' illustrated in Figs.
|
| 1003 |
|
|
\ref{fig:staf0:stfw0:00}, \ref{fig:staf0:stfw0:01}, and \ref{fig:staf0:stfw0:02})?
|
| 1004 |
|
|
\item Is the factorization unique\footnote{In the same sense that the
|
| 1005 |
|
|
fundamental theorem of arithmetic guarantees that a composite
|
| 1006 |
|
|
can have only one unique factorization into primes.}
|
| 1007 |
|
|
or can it be made unique according
|
| 1008 |
|
|
to some metric?
|
| 1009 |
|
|
\item Can algorithms spot suboptimal designs and coach
|
| 1010 |
|
|
human programmers?\footnote{Example of a suboptimal design:
|
| 1011 |
|
|
identical behavior could be achieved using a simpler design.}
|
| 1012 |
|
|
\end{itemize}
|
| 1013 |
|
|
|
| 1014 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1015 |
|
|
|
| 1016 |
|
|
\subsection{Code Generation from Systems of Timed Automata}
|
| 1017 |
|
|
\label{srin0:snvf0}
|
| 1018 |
|
|
|
| 1019 |
|
|
I have interest in the mathematics of code generation from systems of timed
|
| 1020 |
|
|
automata. One might make the observation that all of the techniques
|
| 1021 |
|
|
described in \S{}\ref{sfrr0} are individual and seemingly disjoint techniques that
|
| 1022 |
|
|
come about through human ingenuity. I am interested in:
|
| 1023 |
|
|
|
| 1024 |
|
|
\begin{itemize}
|
| 1025 |
|
|
\item Any unified mathematical framework that includes all of the techniques.
|
| 1026 |
|
|
For example, can one find a common framework or way of thinking that includes both
|
| 1027 |
|
|
Farey series approximations and vertical counters?
|
| 1028 |
|
|
\item Any mathematical framework that, given a smorgasbord of disjoint techniques,
|
| 1029 |
|
|
can predict how to apply them to obtain optimal results (this is also
|
| 1030 |
|
|
a function of the processor instruction set). (Cost matrices and
|
| 1031 |
|
|
least-squares methods come to mind immediately, but I'd like to examine
|
| 1032 |
|
|
this more closely.)
|
| 1033 |
|
|
\end{itemize}
|
| 1034 |
|
|
|
| 1035 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1036 |
|
|
|
| 1037 |
|
|
\subsection{Code Generation and Formal Verification of Properties in the Same Framework}
|
| 1038 |
|
|
\label{srin0:sgvs0}
|
| 1039 |
|
|
|
| 1040 |
|
|
There seem to be no existing tools that will allow code generation (from
|
| 1041 |
|
|
a timed automata model) and the
|
| 1042 |
|
|
verification of formal properties in the same framework. In addition, the tools
|
| 1043 |
|
|
that do generate code (for small systems) can't optimize as effectively as a
|
| 1044 |
|
|
human programmer. With a more sound mathematical basis for optimization,
|
| 1045 |
|
|
I believe that tools should be able to optimize more effectively
|
| 1046 |
|
|
than a human programmer.
|
| 1047 |
|
|
|
| 1048 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1049 |
|
|
|
| 1050 |
|
|
\subsection{Enterprise Content Management}
|
| 1051 |
|
|
\label{srin0:secm0}
|
| 1052 |
|
|
|
| 1053 |
|
|
I administer web-based version control and defect-tracking databases. This type of
|
| 1054 |
|
|
technology is critical because human beings don't deal well with complexity and
|
| 1055 |
|
|
there is the inherent need to serialize (one bug at a time, one change at a time, etc.).
|
| 1056 |
|
|
|
| 1057 |
|
|
I have some interest in enterprise content management
|
| 1058 |
|
|
(see, for example, \emph{Alfresco}), especially the
|
| 1059 |
|
|
buy-versus-build dilemma and the difficulty
|
| 1060 |
|
|
and cost of developing custom in-house tools that are tailored to an individual
|
| 1061 |
|
|
company's processes (I have some ideas in this area).
|
| 1062 |
|
|
|
| 1063 |
|
|
|
| 1064 |
|
|
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
| 1065 |
|
|
\end{document}
|
| 1066 |
|
|
%
|
| 1067 |
|
|
%$Log: phdtopicpropa.tex,v $
|
| 1068 |
|
|
%Revision 1.20 2006/03/27 00:10:30 dashley
|
| 1069 |
|
|
%Presumed final edits.
|
| 1070 |
|
|
%
|
| 1071 |
|
|
%Revision 1.19 2006/03/26 23:26:23 dashley
|
| 1072 |
|
|
%Edits.
|
| 1073 |
|
|
%
|
| 1074 |
|
|
%Revision 1.18 2006/03/26 02:22:21 dashley
|
| 1075 |
|
|
%Edits.
|
| 1076 |
|
|
%
|
| 1077 |
|
|
%End of $RCSfile: phdtopicpropa.tex,v $.
|
| 1078 |
|
|
|
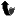 Parent Directory
|
Parent Directory
|  Revision Log
Revision Log